Potrebbero piacerti anche
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDa EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeValutazione: 4 su 5 stelle4/5 (5794)
- The Yellow House: A Memoir (2019 National Book Award Winner)Da EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Valutazione: 4 su 5 stelle4/5 (98)
- Ejise Volume9 Issue1 Article490Documento13 pagineEjise Volume9 Issue1 Article490Arpit BajpaiNessuna valutazione finora
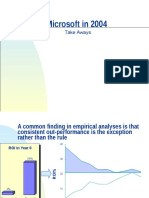
- Microsoft in 2004: Take AwaysDocumento20 pagineMicrosoft in 2004: Take AwaysArpit BajpaiNessuna valutazione finora
- This Hsdaasn'tDocumento1 paginaThis Hsdaasn'tArpit BajpaiNessuna valutazione finora
- AaaaaaDocumento8 pagineAaaaaaArpit BajpaiNessuna valutazione finora
- Functional Groups: Pilots Flight Attendants Gate Agents Ticket Agents Ops Agents Ramp AgentsDocumento8 pagineFunctional Groups: Pilots Flight Attendants Gate Agents Ticket Agents Ops Agents Ramp AgentsArpit BajpaiNessuna valutazione finora
- Pitch Book SampleDocumento58 paginePitch Book SampleThomas Kyei-BoatengNessuna valutazione finora
- IMOMATH - Generating FunctionsDocumento24 pagineIMOMATH - Generating FunctionsDijkschneier100% (1)
- RishiDocumento1 paginaRishiArpit BajpaiNessuna valutazione finora
- Pay in SlipDocumento1 paginaPay in SlipArpit BajpaiNessuna valutazione finora
- Net - Angels - : Boar LuringDocumento4 pagineNet - Angels - : Boar LuringArpit BajpaiNessuna valutazione finora
- BdlogDocumento6 pagineBdlogArpit BajpaiNessuna valutazione finora
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDa EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryValutazione: 3.5 su 5 stelle3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDa EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceValutazione: 4 su 5 stelle4/5 (895)
- The Little Book of Hygge: Danish Secrets to Happy LivingDa EverandThe Little Book of Hygge: Danish Secrets to Happy LivingValutazione: 3.5 su 5 stelle3.5/5 (400)
- Shoe Dog: A Memoir by the Creator of NikeDa EverandShoe Dog: A Memoir by the Creator of NikeValutazione: 4.5 su 5 stelle4.5/5 (537)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDa EverandNever Split the Difference: Negotiating As If Your Life Depended On ItValutazione: 4.5 su 5 stelle4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDa EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureValutazione: 4.5 su 5 stelle4.5/5 (474)
- Grit: The Power of Passion and PerseveranceDa EverandGrit: The Power of Passion and PerseveranceValutazione: 4 su 5 stelle4/5 (588)
- The Emperor of All Maladies: A Biography of CancerDa EverandThe Emperor of All Maladies: A Biography of CancerValutazione: 4.5 su 5 stelle4.5/5 (271)
- On Fire: The (Burning) Case for a Green New DealDa EverandOn Fire: The (Burning) Case for a Green New DealValutazione: 4 su 5 stelle4/5 (74)
- Team of Rivals: The Political Genius of Abraham LincolnDa EverandTeam of Rivals: The Political Genius of Abraham LincolnValutazione: 4.5 su 5 stelle4.5/5 (234)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDa EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaValutazione: 4.5 su 5 stelle4.5/5 (266)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDa EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersValutazione: 4.5 su 5 stelle4.5/5 (344)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDa EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyValutazione: 3.5 su 5 stelle3.5/5 (2259)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDa EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreValutazione: 4 su 5 stelle4/5 (1090)
- The Unwinding: An Inner History of the New AmericaDa EverandThe Unwinding: An Inner History of the New AmericaValutazione: 4 su 5 stelle4/5 (45)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Da EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Valutazione: 4.5 su 5 stelle4.5/5 (121)
- Her Body and Other Parties: StoriesDa EverandHer Body and Other Parties: StoriesValutazione: 4 su 5 stelle4/5 (821)
- Ác Ác Ác ÁcDocumento12 pagineÁc Ác Ác ÁcMran QilaNessuna valutazione finora
- Sample MIS ExamDocumento204 pagineSample MIS ExamDeniz ToramanNessuna valutazione finora
- Syllabus-IS3150 - Introduction To Information Systems-Seattle University (Su)Documento6 pagineSyllabus-IS3150 - Introduction To Information Systems-Seattle University (Su)Human Resource ManagementNessuna valutazione finora
- The Role of Financial Literacy, Use of Accounting Information Systems, Human Resources On SME PerformanceDocumento5 pagineThe Role of Financial Literacy, Use of Accounting Information Systems, Human Resources On SME PerformanceInternational Journal of Innovative Science and Research TechnologyNessuna valutazione finora
- Information Management Systems Syllabus July 2020Documento5 pagineInformation Management Systems Syllabus July 2020Michael James CaminoNessuna valutazione finora
- Debovski VD (2022) - Conversational Agents in Creative Work - A Systematic Literature Review and Research Agenda For Remote Design ThinkingDocumento18 pagineDebovski VD (2022) - Conversational Agents in Creative Work - A Systematic Literature Review and Research Agenda For Remote Design ThinkingMetin ÖrnekNessuna valutazione finora
- Fi FMDocumento2 pagineFi FMAlexFluidoNessuna valutazione finora
- AIS Chapter 1Documento31 pagineAIS Chapter 1Dr. Mohammad Noor AlamNessuna valutazione finora
- Dokumen - Tips - Paul Beynon Davies Business Information Systems Business Information Systems Paul Beynon Davies Website OverviewDocumento9 pagineDokumen - Tips - Paul Beynon Davies Business Information Systems Business Information Systems Paul Beynon Davies Website OverviewAkil AjNessuna valutazione finora
- Mis Assignment 2 by Daniel Awoke Id Mao 1522 2013Documento14 pagineMis Assignment 2 by Daniel Awoke Id Mao 1522 2013Dani Azmi AwokeNessuna valutazione finora
- Transactional and Financial Management Information System For GrafituxDocumento36 pagineTransactional and Financial Management Information System For GrafituxCamille BoteNessuna valutazione finora
- Business-It Alignment in The Banking Sector: A Case From A Developing CountryDocumento13 pagineBusiness-It Alignment in The Banking Sector: A Case From A Developing CountryayalewtesfawNessuna valutazione finora
- MIS Quiz 1Documento5 pagineMIS Quiz 1Uzair ArbabNessuna valutazione finora
- PUMBA 2013 15 Batch Dossier PDFDocumento86 paginePUMBA 2013 15 Batch Dossier PDFAjinkya JagtapNessuna valutazione finora
- N-MIS-10.0Documento43 pagineN-MIS-10.0Thao PhamNessuna valutazione finora
- Engineering 1Documento107 pagineEngineering 1ozoemena29Nessuna valutazione finora
- Process Mining of Event Logs in Internal AuditingDocumento31 pagineProcess Mining of Event Logs in Internal Auditinghoangnguyen7xNessuna valutazione finora
- 1st AssignmentDocumento12 pagine1st AssignmentAnonymous f7wV1lQKRNessuna valutazione finora
- Decision Support System - Chapter 1Documento30 pagineDecision Support System - Chapter 1Ver Dnad Jacobe100% (2)
- Health Information SystemDocumento132 pagineHealth Information SystemSiAgam DevinfoNessuna valutazione finora
- DMC 216Documento7 pagineDMC 216Anubhav SharmaNessuna valutazione finora
- Mis MCQSDocumento13 pagineMis MCQSVee BeatNessuna valutazione finora
- Lecture 6: Other Fundamentals of Information SystemsDocumento31 pagineLecture 6: Other Fundamentals of Information SystemsJamielyn EducalanNessuna valutazione finora
- Information Systems, Organizations, and Strategy: Slides Prepared by MAKS, MIS Department, DUDocumento50 pagineInformation Systems, Organizations, and Strategy: Slides Prepared by MAKS, MIS Department, DUSP VetNessuna valutazione finora
- List of Books Published by Matrix EducareDocumento5 pagineList of Books Published by Matrix Educarekuntal.kgec.cse323950% (2)
- PH D-BT280711 PDFDocumento13 paginePH D-BT280711 PDFShuvajoyyyNessuna valutazione finora
- Critical Success Factors For ERP ProjectsDocumento8 pagineCritical Success Factors For ERP ProjectsZubair KhanNessuna valutazione finora
- CargillsDocumento10 pagineCargillsKarthik Sivanesarajah90% (10)
- Ibm PMODocumento26 pagineIbm PMOJuan Carlos MonteroNessuna valutazione finora
- Performance Management AccaDocumento131 paginePerformance Management AccaAliya Zamri100% (1)