Potrebbero piacerti anche
- Festival de Praia de Boca do Acre anima a cidadeDocumento21 pagineFestival de Praia de Boca do Acre anima a cidadeMarina Gusmão100% (2)
- Festival de Praia de Boca do Acre promove cultura e economiaDocumento16 pagineFestival de Praia de Boca do Acre promove cultura e economiaBryam GarciaNessuna valutazione finora
- Contabilidade do Terceiro Setor: Percepção dos ContadoresDocumento12 pagineContabilidade do Terceiro Setor: Percepção dos ContadoresBryam GarciaNessuna valutazione finora
- Contabilidade do Terceiro Setor: Percepção dos ContadoresDocumento12 pagineContabilidade do Terceiro Setor: Percepção dos ContadoresBryam GarciaNessuna valutazione finora
- Atividade Simplificação PráticaDocumento1 paginaAtividade Simplificação PráticaBryam GarciaNessuna valutazione finora
- Compactação de solos: princípios e técnicasDocumento45 pagineCompactação de solos: princípios e técnicasAlberto CarlosNessuna valutazione finora
- 129 Professor 1o Ao 5o Ano 1551131016 PDFDocumento13 pagine129 Professor 1o Ao 5o Ano 1551131016 PDFBryam GarciaNessuna valutazione finora
- Modelo RelatorioDocumento10 pagineModelo RelatoriobaruanymNessuna valutazione finora
- Festival de Praia de Boca do Acre promove cultura e economiaDocumento16 pagineFestival de Praia de Boca do Acre promove cultura e economiaBryam GarciaNessuna valutazione finora
- 124 Psicopedagogo 1551130840 PDFDocumento14 pagine124 Psicopedagogo 1551130840 PDFBryam GarciaNessuna valutazione finora
- 124 Psicopedagogo 1551130840 PDFDocumento14 pagine124 Psicopedagogo 1551130840 PDFBryam GarciaNessuna valutazione finora
- 129 Professor 1o Ao 5o Ano 1551131016 PDFDocumento13 pagine129 Professor 1o Ao 5o Ano 1551131016 PDFBryam GarciaNessuna valutazione finora
- 6565Documento43 pagine6565Bryam GarciaNessuna valutazione finora
- 656Documento16 pagine656Bryam GarciaNessuna valutazione finora
- Lista 09Documento1 paginaLista 09Bryam GarciaNessuna valutazione finora
- 212Documento18 pagine212Bryam GarciaNessuna valutazione finora
- GravitacaoDocumento33 pagineGravitacaoBryam GarciaNessuna valutazione finora
- Tópicos de Estatística Utilizando o R ItaloDocumento32 pagineTópicos de Estatística Utilizando o R ItaloricpetterleNessuna valutazione finora
- Le 10Documento2 pagineLe 10Bryam GarciaNessuna valutazione finora
- Modelo 4 ESCALA 5-1 MM-ModelDocumento1 paginaModelo 4 ESCALA 5-1 MM-ModelBryam GarciaNessuna valutazione finora
- Modelo 4 ESCALA 5-1 MM-ModelDocumento1 paginaModelo 4 ESCALA 5-1 MM-ModelBryam GarciaNessuna valutazione finora
- Modelo 4 ESCALA 5-1 MM-ModelDocumento1 paginaModelo 4 ESCALA 5-1 MM-ModelBryam GarciaNessuna valutazione finora
- ANA3Documento1 paginaANA3Bryam GarciaNessuna valutazione finora
- Modelo 3 ESCALA 1-20 CM-ModelDocumento1 paginaModelo 3 ESCALA 1-20 CM-ModelBryam GarciaNessuna valutazione finora
- ANA4Documento1 paginaANA4Bryam GarciaNessuna valutazione finora
- ADocumento1 paginaABryam GarciaNessuna valutazione finora
- Modelo 21 ESCALA 1-1 MM-ModelDocumento1 paginaModelo 21 ESCALA 1-1 MM-ModelBryam GarciaNessuna valutazione finora
- ANA4Documento1 paginaANA4Bryam GarciaNessuna valutazione finora
- ANA2Documento1 paginaANA2Bryam GarciaNessuna valutazione finora
- ANA0Documento1 paginaANA0Bryam GarciaNessuna valutazione finora
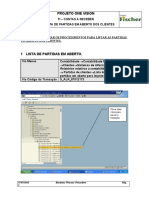
- AR F.21 - Lista de Partidas em Aberto Do ClienteDocumento4 pagineAR F.21 - Lista de Partidas em Aberto Do ClienteValdevy PiresNessuna valutazione finora
- Evk 214 N2Documento7 pagineEvk 214 N2Mauricioss2313 Soares100% (2)
- Gabarito Oficial de InformáticaDocumento16 pagineGabarito Oficial de InformáticaNatália GabrielaNessuna valutazione finora
- Implementação de um compilador PascalDocumento123 pagineImplementação de um compilador PascalLaurindo PanzoNessuna valutazione finora
- Peças Sulcador Beija-FlorDocumento7 paginePeças Sulcador Beija-FlorVadinho BenezNessuna valutazione finora
- Segurança Cibernética - Propriedades e PrincípiosDocumento63 pagineSegurança Cibernética - Propriedades e PrincípiosTriploc MarquesNessuna valutazione finora
- Manual de Configuração REMUX IS720LADocumento15 pagineManual de Configuração REMUX IS720LAEngenhariaNessuna valutazione finora
- Curso Livre - AutoCAD 2018 - Professional - Senac São PauloDocumento3 pagineCurso Livre - AutoCAD 2018 - Professional - Senac São PauloDenner Melo FreitasNessuna valutazione finora
- Web CamDocumento9 pagineWeb CamMarcos Moura RamosNessuna valutazione finora
- Transações BasisDocumento24 pagineTransações Basis20jgas09Nessuna valutazione finora
- Avaliação Linguagem de Programação IDocumento11 pagineAvaliação Linguagem de Programação IPedro Heitor Venturini LinharesNessuna valutazione finora
- Uma visão do DMBOKDocumento46 pagineUma visão do DMBOKEveraldo ChavesNessuna valutazione finora
- Acesso AVA UNIPACDocumento26 pagineAcesso AVA UNIPACTALITA ELOAH GUERRA COUVEANessuna valutazione finora
- Controlador de Válvula Digital FIELDVUE DVC6200 Da Fisher: ÍndiceDocumento108 pagineControlador de Válvula Digital FIELDVUE DVC6200 Da Fisher: ÍndiceRicardo RodriguesNessuna valutazione finora
- DDL DML banco dados definir manipularDocumento21 pagineDDL DML banco dados definir manipularValtinhoNessuna valutazione finora
- Afiliados Hotmart Como Eu Devo Fazer - (Guia Completo) .Documento10 pagineAfiliados Hotmart Como Eu Devo Fazer - (Guia Completo) .Claudio Gomes Silva LeiteNessuna valutazione finora
- Tutorial A Prova de Idiotas Pra Fazer Seu GH3Documento3 pagineTutorial A Prova de Idiotas Pra Fazer Seu GH3Gray FullbusterNessuna valutazione finora
- Exercícios Resolvidos: Raiz ComplexaDocumento4 pagineExercícios Resolvidos: Raiz ComplexaDiego OliveiraNessuna valutazione finora
- CA Magazine Mai03 CasasinteligentesDocumento1 paginaCA Magazine Mai03 Casasinteligentessandro868Nessuna valutazione finora
- Resident Evil 1 Jill Valentine Parte 1Documento15 pagineResident Evil 1 Jill Valentine Parte 1DavidNessuna valutazione finora
- Slides01 DesenvolvimentoWebDocumento43 pagineSlides01 DesenvolvimentoWebFelipe TardivoNessuna valutazione finora
- Carta ABES val. 15.06.24Documento5 pagineCarta ABES val. 15.06.24Júnio JorgeNessuna valutazione finora
- Prática Profissional I - Atividade 04Documento2 paginePrática Profissional I - Atividade 04João Álvaro100% (1)
- Banco de Dados I - Transações e Controle de ConcorrênciaDocumento39 pagineBanco de Dados I - Transações e Controle de Concorrênciamfomoura1Nessuna valutazione finora
- Algebra BooleanaDocumento3 pagineAlgebra BooleanaSamuel RibeiroNessuna valutazione finora
- Grade Curricular Direito USP PDFDocumento1 paginaGrade Curricular Direito USP PDFpgn999Nessuna valutazione finora
- List A 2Documento4 pagineList A 2José Luiz Rybarczyk FilhoNessuna valutazione finora
- Amd690gm M2Documento16 pagineAmd690gm M2kakitosNessuna valutazione finora
- Manual de Instruções TopAcesso - MP04801-01Documento264 pagineManual de Instruções TopAcesso - MP04801-01paivapaivaNessuna valutazione finora
- Propagação via satélite em Banda KuDocumento20 paginePropagação via satélite em Banda KuIsrael FrankeNessuna valutazione finora