Potrebbero piacerti anche
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDa EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeValutazione: 4 su 5 stelle4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDa EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreValutazione: 4 su 5 stelle4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDa EverandNever Split the Difference: Negotiating As If Your Life Depended On ItValutazione: 4.5 su 5 stelle4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDa EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceValutazione: 4 su 5 stelle4/5 (895)
- Grit: The Power of Passion and PerseveranceDa EverandGrit: The Power of Passion and PerseveranceValutazione: 4 su 5 stelle4/5 (588)
- Shoe Dog: A Memoir by the Creator of NikeDa EverandShoe Dog: A Memoir by the Creator of NikeValutazione: 4.5 su 5 stelle4.5/5 (537)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDa EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersValutazione: 4.5 su 5 stelle4.5/5 (345)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDa EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureValutazione: 4.5 su 5 stelle4.5/5 (474)
- Her Body and Other Parties: StoriesDa EverandHer Body and Other Parties: StoriesValutazione: 4 su 5 stelle4/5 (821)
- The Emperor of All Maladies: A Biography of CancerDa EverandThe Emperor of All Maladies: A Biography of CancerValutazione: 4.5 su 5 stelle4.5/5 (271)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Da EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Valutazione: 4.5 su 5 stelle4.5/5 (121)
- The Little Book of Hygge: Danish Secrets to Happy LivingDa EverandThe Little Book of Hygge: Danish Secrets to Happy LivingValutazione: 3.5 su 5 stelle3.5/5 (400)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDa EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyValutazione: 3.5 su 5 stelle3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)Da EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Valutazione: 4 su 5 stelle4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDa EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaValutazione: 4.5 su 5 stelle4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDa EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryValutazione: 3.5 su 5 stelle3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnDa EverandTeam of Rivals: The Political Genius of Abraham LincolnValutazione: 4.5 su 5 stelle4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealDa EverandOn Fire: The (Burning) Case for a Green New DealValutazione: 4 su 5 stelle4/5 (74)
- The Unwinding: An Inner History of the New AmericaDa EverandThe Unwinding: An Inner History of the New AmericaValutazione: 4 su 5 stelle4/5 (45)
- DP-8060 ServiceManual Ver.1.4Documento955 pagineDP-8060 ServiceManual Ver.1.4Brad Hepper100% (3)
- Summer Training ProjectDocumento42 pagineSummer Training ProjectPoojaPandey100% (1)
- Audio On ARM Cortex-M ProcessorsDocumento5 pagineAudio On ARM Cortex-M ProcessorsravigobiNessuna valutazione finora
- A Comparative Runtime Analysis of Heuristic AlgorithmsDocumento18 pagineA Comparative Runtime Analysis of Heuristic AlgorithmsravigobiNessuna valutazione finora
- Analyzing HardFaults On Cortex-M CPUDocumento12 pagineAnalyzing HardFaults On Cortex-M CPUravigobiNessuna valutazione finora
- Streaming Linear Regression On Spark MLlib and MOADocumento4 pagineStreaming Linear Regression On Spark MLlib and MOAravigobiNessuna valutazione finora
- Spark On Hadoop Vs MPI OpenMP On BeowulfDocumento10 pagineSpark On Hadoop Vs MPI OpenMP On BeowulfravigobiNessuna valutazione finora
- Big O NotationsDocumento19 pagineBig O NotationsravigobiNessuna valutazione finora
- Complexity Measures For Meta-LearningDocumento12 pagineComplexity Measures For Meta-LearningravigobiNessuna valutazione finora
- Automotive Big DataDocumento10 pagineAutomotive Big DataravigobiNessuna valutazione finora
- ESL Brains Artificial Intelligence in Your Everyday Life SV 2091Documento3 pagineESL Brains Artificial Intelligence in Your Everyday Life SV 2091David KNOXNessuna valutazione finora
- Lec1-Introduction To Data Structure and AlgorithmsDocumento20 pagineLec1-Introduction To Data Structure and Algorithmssheheryar100% (3)
- JUE200Documento2 pagineJUE200ella100% (1)
- Ome44850s VR7000 7000SDocumento77 pagineOme44850s VR7000 7000SJahid IslamNessuna valutazione finora
- Service Manual: Trinitron Color TVDocumento17 pagineService Manual: Trinitron Color TVohukNessuna valutazione finora
- 4 TlsDocumento24 pagine4 TlsnshivegowdaNessuna valutazione finora
- Quectel UG95 TCPIP at Commands Manual V1.0Documento36 pagineQuectel UG95 TCPIP at Commands Manual V1.0frozenrain1027Nessuna valutazione finora
- Cs3591 CN Unit 1 Notes Eduengg - RemovedDocumento66 pagineCs3591 CN Unit 1 Notes Eduengg - RemovedSpam AccNessuna valutazione finora
- Motherboard Manual Ga-7ixe4 eDocumento67 pagineMotherboard Manual Ga-7ixe4 ebulkanoNessuna valutazione finora
- SQL: LIKE ConditionDocumento7 pagineSQL: LIKE ConditionjoseavilioNessuna valutazione finora
- Icafetech OBM Diskless 1.9Documento11 pagineIcafetech OBM Diskless 1.9Sirch RudolfNessuna valutazione finora
- The Phishing GuideDocumento47 pagineThe Phishing Guidezorantic1Nessuna valutazione finora
- How To Configure A Linux Router With Multiple ISPDocumento4 pagineHow To Configure A Linux Router With Multiple ISPdissidraNessuna valutazione finora
- Siemens Simatic st70n Catalogue 2014-Eng PDFDocumento276 pagineSiemens Simatic st70n Catalogue 2014-Eng PDFsalvadorNessuna valutazione finora
- Summer Internship Project Report On Web Development: Bachelor of Computer ApplicationsDocumento19 pagineSummer Internship Project Report On Web Development: Bachelor of Computer Applicationsits me Deepak yadavNessuna valutazione finora
- 1.60 Opera Standards PDFDocumento2 pagine1.60 Opera Standards PDFsNessuna valutazione finora
- Ecobank Omini Lite User GuideDocumento27 pagineEcobank Omini Lite User Guideguy playerNessuna valutazione finora
- Oracle Applications Basic Training ManualDocumento128 pagineOracle Applications Basic Training ManualDeepak ChoudhuryNessuna valutazione finora
- Raspberry Practical Manual SachinDocumento49 pagineRaspberry Practical Manual SachinVaibhav KarambeNessuna valutazione finora
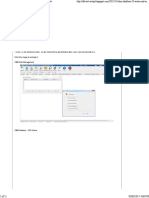
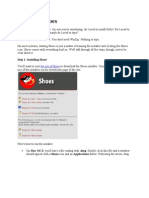
- Shoes GUI For RubyDocumento63 pagineShoes GUI For RubySlametz PembukaNessuna valutazione finora
- Mokerlink Outdoor Wirelss - AP - User - ManualDocumento11 pagineMokerlink Outdoor Wirelss - AP - User - ManualJai Sri HariNessuna valutazione finora
- USMTGUI User GuideDocumento11 pagineUSMTGUI User GuideNguyen Hoang AnhNessuna valutazione finora
- D000792212-Antivirus Guidelines For Vue PACS 12.2 - RevBDocumento9 pagineD000792212-Antivirus Guidelines For Vue PACS 12.2 - RevBchuswasadreamNessuna valutazione finora
- Oracle Application Framework: by Sridhar YerramDocumento63 pagineOracle Application Framework: by Sridhar YerramRabahNessuna valutazione finora
- DVD Player User Manual: ImagineDocumento16 pagineDVD Player User Manual: ImagineRamon AlamsyahNessuna valutazione finora
- 1.2.4.cloud ComputingDocumento2 pagine1.2.4.cloud ComputingLAVANYA SISTANessuna valutazione finora
- Ujian Modul 1 - 3Documento37 pagineUjian Modul 1 - 3Helmi YudistiraNessuna valutazione finora
- Chapter 2Documento52 pagineChapter 2Bam BoocNessuna valutazione finora