Potrebbero piacerti anche
- Application of Residue Number System To Bioinformatics: Kwara State University, MaleteDocumento14 pagineApplication of Residue Number System To Bioinformatics: Kwara State University, Maletefeezy11Nessuna valutazione finora
- Final Project Report Transient Stability of Power System (Programming Massively Parallel Graphics Multiprocessors Using CUDA)Documento5 pagineFinal Project Report Transient Stability of Power System (Programming Massively Parallel Graphics Multiprocessors Using CUDA)shotorbariNessuna valutazione finora
- Jels LdaDocumento11 pagineJels LdamehdimatinfarNessuna valutazione finora
- A 2589 Line Topology Optimization Code Written For The Graphics CardDocumento20 pagineA 2589 Line Topology Optimization Code Written For The Graphics Cardgorot1Nessuna valutazione finora
- On The GOn The Grid Implementation of A Quantum Reactive Scattering Programrid Implementation of A Quantum Reactive Scattering ProgramDocumento17 pagineOn The GOn The Grid Implementation of A Quantum Reactive Scattering Programrid Implementation of A Quantum Reactive Scattering ProgramFreeWillNessuna valutazione finora
- GPU-based Matrix-Free Finite Element Solver ExploiDocumento26 pagineGPU-based Matrix-Free Finite Element Solver ExploiWajid SiyalNessuna valutazione finora
- A Fast Approach Distribution System Load Flow SolutionDocumento11 pagineA Fast Approach Distribution System Load Flow SolutionAlejandroHerreraGurideChileNessuna valutazione finora
- A Performance Study of Applying CUDA-Enabled GPU in Polar Hough Transform For LinesDocumento4 pagineA Performance Study of Applying CUDA-Enabled GPU in Polar Hough Transform For LinesJournal of ComputingNessuna valutazione finora
- Mcgill University School of Computer Science Acaps LaboratoryDocumento34 pagineMcgill University School of Computer Science Acaps Laboratorywoxawi6937Nessuna valutazione finora
- A Practical GPU Based KNN Algorithm: Quansheng Kuang, and Lei ZhaoDocumento5 pagineA Practical GPU Based KNN Algorithm: Quansheng Kuang, and Lei ZhaoDerry FajirwanNessuna valutazione finora
- GA and TS Optimization of ATM NetworksDocumento5 pagineGA and TS Optimization of ATM NetworksPrateek BahetiNessuna valutazione finora
- Optimal Placement of Measuring Devices For DistribDocumento14 pagineOptimal Placement of Measuring Devices For Distribepe3630Nessuna valutazione finora
- Application of Parallel Tabu Search Distribution Network Expansion Planning Distributed GenerationDocumento6 pagineApplication of Parallel Tabu Search Distribution Network Expansion Planning Distributed Generationbluemoon1172Nessuna valutazione finora
- GAAM: Energy Conservation in Sensor Networks Using Code MigrationDocumento6 pagineGAAM: Energy Conservation in Sensor Networks Using Code Migrationseetha04Nessuna valutazione finora
- An Improved Dijkstra Shortest Path AlgorithmDocumento4 pagineAn Improved Dijkstra Shortest Path AlgorithmHo Van RoiNessuna valutazione finora
- Scaling Kernel Machine Learning Algorithm Via The Use of GpusDocumento1 paginaScaling Kernel Machine Learning Algorithm Via The Use of GpusravigobiNessuna valutazione finora
- Journal of Computational Physics: Sanghyun Ha, Junshin Park, Donghyun YouDocumento19 pagineJournal of Computational Physics: Sanghyun Ha, Junshin Park, Donghyun Youflowh_Nessuna valutazione finora
- UNIT V Parallel Programming Patterns in CUDA (T2 Chapter 7) - P P With CUDADocumento35 pagineUNIT V Parallel Programming Patterns in CUDA (T2 Chapter 7) - P P With CUDAGANESH CINDINessuna valutazione finora
- Gauss User ManualDocumento6 pagineGauss User ManualMys GenieNessuna valutazione finora
- Multi-Factor Max Correlation Algorithm For Fault Tolerance in Cloud Simulated EnvironmentDocumento4 pagineMulti-Factor Max Correlation Algorithm For Fault Tolerance in Cloud Simulated EnvironmentijsretNessuna valutazione finora
- Trade-Offs in Multiplier Block Algorithms For Low Power Digit-Serial FIR FiltersDocumento6 pagineTrade-Offs in Multiplier Block Algorithms For Low Power Digit-Serial FIR FiltersPankaj JoshiNessuna valutazione finora
- Efficient Mapreduce Matrix Multiplication With Optimized Mapper SetDocumento12 pagineEfficient Mapreduce Matrix Multiplication With Optimized Mapper SetSandraPereraNessuna valutazione finora
- Sequence Alignment Algorithm OverviewDocumento1 paginaSequence Alignment Algorithm Overviewrobthomas1Nessuna valutazione finora
- Application of Parallel Tabu Search To Distribution Network Expansion Planning With Distributed GenerationDocumento6 pagineApplication of Parallel Tabu Search To Distribution Network Expansion Planning With Distributed GenerationItalo ChiarellaNessuna valutazione finora
- Distributed Optimization Using ALADIN For MPC in Smart GridsDocumento11 pagineDistributed Optimization Using ALADIN For MPC in Smart GridsRenato Fuentealba AravenaNessuna valutazione finora
- Breaking Through Memory Limitation in GPU Parallel Processing Using Strassen AlgorithmDocumento5 pagineBreaking Through Memory Limitation in GPU Parallel Processing Using Strassen AlgorithmDonkeyTankNessuna valutazione finora
- Dijkstra Algorithm For Feeder Routing of Radial Distribution SystemDocumento6 pagineDijkstra Algorithm For Feeder Routing of Radial Distribution SystemIOSRJEN : hard copy, certificates, Call for Papers 2013, publishing of journalNessuna valutazione finora
- Fast Polynomial Approximation Acceleration On The GPU: NtroductionDocumento4 pagineFast Polynomial Approximation Acceleration On The GPU: NtroductionbrufoNessuna valutazione finora
- A Simulated Annealing Method To Cover Dynamic Load Balancing in Grid EnvironmentDocumento10 pagineA Simulated Annealing Method To Cover Dynamic Load Balancing in Grid EnvironmentMauricio PalettaNessuna valutazione finora
- GPU ClusterDocumento12 pagineGPU ClusterPrashant GuptaNessuna valutazione finora
- I Jsa It 04132012Documento4 pagineI Jsa It 04132012WARSE JournalsNessuna valutazione finora
- Profile Front MinimizationDocumento12 pagineProfile Front MinimizationvttrlcNessuna valutazione finora
- Time Series Forecast of Electrical Load Based On XGBoostDocumento10 pagineTime Series Forecast of Electrical Load Based On XGBoostt.d.sudhakar.staffNessuna valutazione finora
- Research Article: Hybrid MPI and CUDA Parallelization For CFD Applications On Multi-GPU HPC ClustersDocumento15 pagineResearch Article: Hybrid MPI and CUDA Parallelization For CFD Applications On Multi-GPU HPC Clusterszhaojie qinNessuna valutazione finora
- FZHT2013 TECS RuleClusteringDocumento29 pagineFZHT2013 TECS RuleClusteringSalemHasnaouiNessuna valutazione finora
- Improvement in Power Transformer Intelligent Dissolved Gas Analysis MethodDocumento4 pagineImprovement in Power Transformer Intelligent Dissolved Gas Analysis MethodsueleninhaNessuna valutazione finora
- Local Adaptive Mesh Refinement For Shock Hydrodynamics: BergerDocumento21 pagineLocal Adaptive Mesh Refinement For Shock Hydrodynamics: BergeryeibiNessuna valutazione finora
- Optimal Distributed Generation Placement Using Ant Colony OptimizationDocumento6 pagineOptimal Distributed Generation Placement Using Ant Colony OptimizationPervez AhmadNessuna valutazione finora
- Ij N×NDocumento5 pagineIj N×NLaila Azwani PanjaitanNessuna valutazione finora
- Heterogeneous Distributed Computing: Muthucumaru Maheswaran, Tracy D. Braun, and Howard Jay SiegelDocumento44 pagineHeterogeneous Distributed Computing: Muthucumaru Maheswaran, Tracy D. Braun, and Howard Jay SiegelNegovan StankovicNessuna valutazione finora
- Energies 11 01288Documento20 pagineEnergies 11 01288Sudarsan Kumar VenkatesanNessuna valutazione finora
- Clustering Techniques and Their Applications in EngineeringDocumento16 pagineClustering Techniques and Their Applications in EngineeringIgor Demetrio100% (1)
- Digital: Calculation of 3-Phase S Circuits by MethodDocumento5 pagineDigital: Calculation of 3-Phase S Circuits by MethodAbcdNessuna valutazione finora
- CUDA 2D Stencil Computations for the Jacobi Method OptimizationDocumento4 pagineCUDA 2D Stencil Computations for the Jacobi Method Optimizationopenid_AePkLAJcNessuna valutazione finora
- All OptimizersDocumento13 pagineAll Optimizersnada montasser gaberNessuna valutazione finora
- Achieving High Speed CFD Simulations: Optimization, Parallelization, and FPGA Acceleration For The Unstructured DLR TAU CodeDocumento20 pagineAchieving High Speed CFD Simulations: Optimization, Parallelization, and FPGA Acceleration For The Unstructured DLR TAU Codesmith1011Nessuna valutazione finora
- On The Use of Low-Power Devices, Approximate Adders and Near-Threshold Operation For Energy-Efficient MultipliersDocumento12 pagineOn The Use of Low-Power Devices, Approximate Adders and Near-Threshold Operation For Energy-Efficient Multipliersprocess dasNessuna valutazione finora
- TSP CMC 27974 Yamini SCIDocumento16 pagineTSP CMC 27974 Yamini SCIRooban SNessuna valutazione finora
- Giris Hetal 2013Documento8 pagineGiris Hetal 2013Serese RemeNessuna valutazione finora
- A Chaos-based Complex Micro-Instruction Set for Mitigating Instruction Reverse EngineeringDocumento14 pagineA Chaos-based Complex Micro-Instruction Set for Mitigating Instruction Reverse EngineeringMesbahNessuna valutazione finora
- Ivan S. Ufimtsev and Todd J. Martınez - Quantum Chemistry On Graphical Processing Units. 1. Strategies For Two-Electron Integral EvaluationDocumento10 pagineIvan S. Ufimtsev and Todd J. Martınez - Quantum Chemistry On Graphical Processing Units. 1. Strategies For Two-Electron Integral EvaluationElectro_LiteNessuna valutazione finora
- SDN 2014Documento9 pagineSDN 2014AGUNG TRI LAKSONONessuna valutazione finora
- Rssi07 PaperDocumento8 pagineRssi07 PaperradicalbndNessuna valutazione finora
- Optimal Location and Sizing Uncertainty Load Genetic Algorithm PDFDocumento14 pagineOptimal Location and Sizing Uncertainty Load Genetic Algorithm PDFtarekegnNessuna valutazione finora
- 70 bd17Documento10 pagine70 bd17pradiptamNessuna valutazione finora
- Digital Simulation Lab-1Documento73 pagineDigital Simulation Lab-1Rahul ChowdariNessuna valutazione finora
- Automatic routing of urban MV distribution networksDocumento6 pagineAutomatic routing of urban MV distribution networksbluemoon1172Nessuna valutazione finora
- Weekly Wimax Traffic Forecasting Using Trainable Cascade-Forward Backpropagation Network in Wavelet DomainDocumento6 pagineWeekly Wimax Traffic Forecasting Using Trainable Cascade-Forward Backpropagation Network in Wavelet DomainInternational Journal of Application or Innovation in Engineering & ManagementNessuna valutazione finora
- TAU - DLR Deutsh Software Flow Aero SolverDocumento7 pagineTAU - DLR Deutsh Software Flow Aero SolverilyesingenieurNessuna valutazione finora
- Backpropagation: Fundamentals and Applications for Preparing Data for Training in Deep LearningDa EverandBackpropagation: Fundamentals and Applications for Preparing Data for Training in Deep LearningNessuna valutazione finora
- Model A360 CatalogDocumento12 pagineModel A360 CatalogThomas StempienNessuna valutazione finora
- Cyber Dynamic Line UsDocumento8 pagineCyber Dynamic Line UsMilan PitovicNessuna valutazione finora
- Form-HSE-TMR-006 Compressor, Genzet, Water Jet InspectionDocumento2 pagineForm-HSE-TMR-006 Compressor, Genzet, Water Jet Inspectionkenia infoNessuna valutazione finora
- Carrier LDU ManualDocumento123 pagineCarrier LDU Manualdafrie rimbaNessuna valutazione finora
- Classful IP Addressing (Cont.) : Address Prefix Address SuffixDocumento25 pagineClassful IP Addressing (Cont.) : Address Prefix Address SuffixGetachew ShambelNessuna valutazione finora
- Advanced Photoshop Magazine 121-2014 PDFDocumento100 pagineAdvanced Photoshop Magazine 121-2014 PDFgusoneNessuna valutazione finora
- Executive MBA Placement Brochure of IIM Bangalore PDFDocumento48 pagineExecutive MBA Placement Brochure of IIM Bangalore PDFnIKKOONessuna valutazione finora
- Checklist For BrickworkDocumento2 pagineChecklist For Brickworkइंजि कौस्तुभ पवारNessuna valutazione finora
- Your One Source In Water Systems Product Catalog 2008Documento44 pagineYour One Source In Water Systems Product Catalog 2008Gerry Dan ChanliongcoNessuna valutazione finora
- Effect of CSR on Corporate Reputation and PerformanceDocumento13 pagineEffect of CSR on Corporate Reputation and PerformanceAnthon AqNessuna valutazione finora
- Approved List of Manufacturers: Line Pipes (Carbon/Alloy Steel)Documento4 pagineApproved List of Manufacturers: Line Pipes (Carbon/Alloy Steel)Sourav Kumar GuptaNessuna valutazione finora
- Tensile TestDocumento15 pagineTensile Testdwimukh360Nessuna valutazione finora
- PACK PAR BoilersDocumento31 paginePACK PAR BoilersJosé MacedoNessuna valutazione finora
- PF0060 KR QUANTEC Pro en PDFDocumento2 paginePF0060 KR QUANTEC Pro en PDFdanipopa_scribdNessuna valutazione finora
- Director Insurance Development Optimization in Cleveland OH Resume Samuel BeldenDocumento3 pagineDirector Insurance Development Optimization in Cleveland OH Resume Samuel BeldenSamuelBeldenNessuna valutazione finora
- Host 1Documento6 pagineHost 1Lukman FafaNessuna valutazione finora
- Philips 26 PFL 3405 Chassis Tpn1.1e-La SM PDFDocumento63 paginePhilips 26 PFL 3405 Chassis Tpn1.1e-La SM PDFViorel GabrielNessuna valutazione finora
- Fault Database - Flat TVDocumento3 pagineFault Database - Flat TVZu AhmadNessuna valutazione finora
- KPC Tech Catalog 2010Documento84 pagineKPC Tech Catalog 2010Mattia KrumenakerNessuna valutazione finora
- 16BBG - Sec17 - NPR NPRHD NQR NRR Diesel Cab Chassis Electrical Revision 3 100115 FinalDocumento34 pagine16BBG - Sec17 - NPR NPRHD NQR NRR Diesel Cab Chassis Electrical Revision 3 100115 FinalJou Power50% (2)
- F Pv28T: PR EN 2714-013A/B/C/DDocumento2 pagineF Pv28T: PR EN 2714-013A/B/C/DFredNessuna valutazione finora
- SAIC-A-2009 Rev 2Documento5 pagineSAIC-A-2009 Rev 2ரமேஷ் பாலக்காடுNessuna valutazione finora
- H61H2 A ManualDocumento88 pagineH61H2 A ManualkuriganoNessuna valutazione finora
- Staggered Truss System - Wikipedia, The Free EncyclopediaDocumento3 pagineStaggered Truss System - Wikipedia, The Free EncyclopediashawnideaNessuna valutazione finora
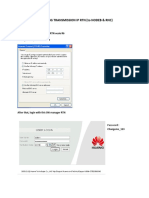
- How to ping NodeB and RNC using RTN transmission IPDocumento14 pagineHow to ping NodeB and RNC using RTN transmission IPPaulo DembiNessuna valutazione finora
- Screw Conveyor O&M ManualDocumento20 pagineScrew Conveyor O&M Manualjay b100% (1)
- INDUCTORDocumento18 pagineINDUCTORBhavaniPrasadNessuna valutazione finora
- Scientific Management's Influence on Organizational DesignDocumento8 pagineScientific Management's Influence on Organizational Designjailekha0% (1)
- Cable Diagram: Technical Data SheetDocumento1 paginaCable Diagram: Technical Data SheetCharlie MendozaNessuna valutazione finora
- File 2 DATN dịch tiếng Anh sang Việt mô hình máy phát điện SEGDocumento28 pagineFile 2 DATN dịch tiếng Anh sang Việt mô hình máy phát điện SEGdangvanthanh150873Nessuna valutazione finora