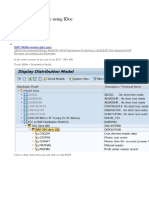
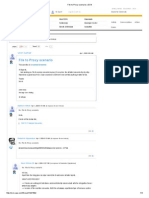
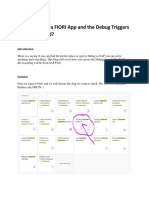
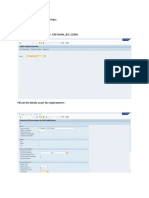
Potrebbero piacerti anche
- Exchange Rate Sync Using IDocDocumento18 pagineExchange Rate Sync Using IDoctoralberNessuna valutazione finora
- Sybase FundamentalsDocumento70 pagineSybase FundamentalsDinakar Babu JangaNessuna valutazione finora
- File To Proxy ScenarioDocumento4 pagineFile To Proxy Scenariodurgavenkatesh100% (1)
- Synchronous Timeout Exceeded Error in Sap Pi - TechTalkZoneDocumento7 pagineSynchronous Timeout Exceeded Error in Sap Pi - TechTalkZoneServicios Administrativos SAPNessuna valutazione finora
- File Adapter ParametersDocumento11 pagineFile Adapter Parametersleelub4u100% (4)
- SAP HANA Log Vol Is FullDocumento7 pagineSAP HANA Log Vol Is FullDinakar Babu JangaNessuna valutazione finora
- Error Codes 700 BNA3Documento97 pagineError Codes 700 BNA3cesar riosNessuna valutazione finora
- SAP PI For Beginners PDFDocumento31 pagineSAP PI For Beginners PDFAshish Kumar MishraNessuna valutazione finora
- Pi Quick GuideDocumento61 paginePi Quick GuideUdayNessuna valutazione finora
- SAP PI - PO Tutorial - Process Integration & OrchestrationDocumento12 pagineSAP PI - PO Tutorial - Process Integration & Orchestrationphogat projectNessuna valutazione finora
- SAP PI Interview Questions - TutorialspointDocumento12 pagineSAP PI Interview Questions - TutorialspointmohananudeepNessuna valutazione finora
- SAP HANA Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesDa EverandSAP HANA Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesNessuna valutazione finora
- SAP interface programming with RFC and VBA: Edit SAP data with MS AccessDa EverandSAP interface programming with RFC and VBA: Edit SAP data with MS AccessNessuna valutazione finora
- SAP S/4HANA Embedded Analytics: Experiences in the FieldDa EverandSAP S/4HANA Embedded Analytics: Experiences in the FieldNessuna valutazione finora
- SAP Basis Configuration Frequently Asked QuestionsDa EverandSAP Basis Configuration Frequently Asked QuestionsValutazione: 3.5 su 5 stelle3.5/5 (4)
- Software Development on the SAP HANA PlatformDa EverandSoftware Development on the SAP HANA PlatformValutazione: 4.5 su 5 stelle4.5/5 (2)
- QRFC and TRFCDocumento19 pagineQRFC and TRFCmayakuntlaNessuna valutazione finora
- SAP PI Naming Conventions Samples - Real TimeDocumento12 pagineSAP PI Naming Conventions Samples - Real TimeAbhiNessuna valutazione finora
- SAP Odata Course ContentDocumento1 paginaSAP Odata Course ContentvenkateshmachineniNessuna valutazione finora
- PI - SAP XI Troubleshooting GuideDocumento9 paginePI - SAP XI Troubleshooting GuideEduardo IkutaNessuna valutazione finora
- RFCLookup SampleDocumento13 pagineRFCLookup SampleProbal SilNessuna valutazione finora
- Sap Abap 751 WhyDocumento38 pagineSap Abap 751 WhyAnonymous Wu81XwWGSINessuna valutazione finora
- Sap Aba Fiori Ui5Documento5 pagineSap Aba Fiori Ui5raamanNessuna valutazione finora
- SAP PI Interview Questions 2Documento7 pagineSAP PI Interview Questions 2Platina 010203Nessuna valutazione finora
- SAP PI ConsultantDocumento10 pagineSAP PI Consultantsouvik_c82Nessuna valutazione finora
- Developing User Enhancement Modules in The Adapter Engine: Sap Netweaver Process Integration 7.1Documento45 pagineDeveloping User Enhancement Modules in The Adapter Engine: Sap Netweaver Process Integration 7.1omegalexandrosNessuna valutazione finora
- XSLT Mapping in Sap Pi 7.1Documento21 pagineXSLT Mapping in Sap Pi 7.1Jennai Padilla Melo100% (2)
- Using SAP PI Lookup API and Dynamic Configuration in SAP GRC NFE Outbound B2B Interface For Dynamic E-Mail Determination PDFDocumento16 pagineUsing SAP PI Lookup API and Dynamic Configuration in SAP GRC NFE Outbound B2B Interface For Dynamic E-Mail Determination PDFJose CamposNessuna valutazione finora
- Web Services ProxyDocumento26 pagineWeb Services Proxysathish11407144Nessuna valutazione finora
- EDI To IDOC Development Using B2B AddDocumento3 pagineEDI To IDOC Development Using B2B AddMurali MuddadaNessuna valutazione finora
- SAP PI Interview QsAsDocumento28 pagineSAP PI Interview QsAssryalla67% (3)
- ABAP On HANADocumento23 pagineABAP On HANAKrishanu DuttaNessuna valutazione finora
- PI REST Adapter - Using DynamicDocumento8 paginePI REST Adapter - Using Dynamicprn1008Nessuna valutazione finora
- SAP XI Tips and TricksDocumento29 pagineSAP XI Tips and TricksLakshmi Narayana Madduri100% (1)
- SAP XI PI PO Cheat SheetzDocumento14 pagineSAP XI PI PO Cheat SheetzPankaj Singh100% (1)
- Delta Queue DemystificationDocumento22 pagineDelta Queue Demystificationsudha_sap_bw3206Nessuna valutazione finora
- How To Create Custom Adapter Module in SAP PI - PO For EJB 3.0 Version - SAP BlogsDocumento20 pagineHow To Create Custom Adapter Module in SAP PI - PO For EJB 3.0 Version - SAP BlogsmohananudeepNessuna valutazione finora
- SAP UI5 - FIORI OData NW Gateway - Syllabus SheetDocumento12 pagineSAP UI5 - FIORI OData NW Gateway - Syllabus Sheetorkut verificationNessuna valutazione finora
- Abap On Hana From Analysis To OptimizationDocumento27 pagineAbap On Hana From Analysis To Optimizationvtheamth100% (1)
- ABAP OO For SAP Business WorkflowDocumento15 pagineABAP OO For SAP Business Workflowtefa0529Nessuna valutazione finora
- Proxy To JDBC ScenarioDocumento36 pagineProxy To JDBC ScenarioDurga Prasad AnaganiNessuna valutazione finora
- Crud Operation Create - Deep - Entity. OdataDocumento9 pagineCrud Operation Create - Deep - Entity. OdatacarmenNessuna valutazione finora
- How To Debug A FIORI AppDocumento8 pagineHow To Debug A FIORI AppSunil GNessuna valutazione finora
- SAP - ABAP RESTful Programming ModelDocumento28 pagineSAP - ABAP RESTful Programming ModelAlan JamesNessuna valutazione finora
- Call Function in Update TaskDocumento4 pagineCall Function in Update TaskHarkesh Kumar YadavNessuna valutazione finora
- B2B - EDI Inbound - Step by Step ConfigurationDocumento19 pagineB2B - EDI Inbound - Step by Step ConfigurationMattana Mattana100% (1)
- SAP HCI DevGuideDocumento168 pagineSAP HCI DevGuideSrinivasan SriNessuna valutazione finora
- ABAP Programming - Upskilling From SAP ERP To SAP S4HANADocumento7 pagineABAP Programming - Upskilling From SAP ERP To SAP S4HANAFarrukhNessuna valutazione finora
- Alert Configuration Example in PI - PO Single Stack - SAP Integration Hub PDFDocumento17 pagineAlert Configuration Example in PI - PO Single Stack - SAP Integration Hub PDFSujith KumarNessuna valutazione finora
- XSLT Mapping in SAP PI 7.1 PDFDocumento21 pagineXSLT Mapping in SAP PI 7.1 PDFWin Vega Flores100% (1)
- SAP XI - PI - 1..N Message Split Interface Without BPMDocumento8 pagineSAP XI - PI - 1..N Message Split Interface Without BPMRezasalomoNessuna valutazione finora
- XSLT MAPPING - RiyazDocumento13 pagineXSLT MAPPING - Riyazprn10080% (1)
- Evolution of Restful ABAP Programming ModelDocumento9 pagineEvolution of Restful ABAP Programming ModelShadab AlamNessuna valutazione finora
- Navigating The BOPF - Part 1 - Getting Started - SAP BlogsDocumento9 pagineNavigating The BOPF - Part 1 - Getting Started - SAP BlogssudhNessuna valutazione finora
- Explain Node Functions - Process Integration - SCN WikiDocumento5 pagineExplain Node Functions - Process Integration - SCN WikiParvez2zNessuna valutazione finora
- Custom Fiori Applications in SAP HANA: Design, Develop, and Deploy Fiori Applications for the EnterpriseDa EverandCustom Fiori Applications in SAP HANA: Design, Develop, and Deploy Fiori Applications for the EnterpriseNessuna valutazione finora
- UI5 User Guide: How to develop responsive data-centric client web applicationsDa EverandUI5 User Guide: How to develop responsive data-centric client web applicationsNessuna valutazione finora
- Open Text GuideDocumento142 pagineOpen Text GuideAnonymous a6FyFaTNessuna valutazione finora
- DBA Cockpit For SAP HANADocumento11 pagineDBA Cockpit For SAP HANADinakar Babu JangaNessuna valutazione finora
- DBA Cockpit For SAP HANADocumento8 pagineDBA Cockpit For SAP HANADinakar Babu JangaNessuna valutazione finora
- Deployment Options PDFDocumento29 pagineDeployment Options PDFsampath2505Nessuna valutazione finora
- Basis Material From KeylabsDocumento231 pagineBasis Material From KeylabsPhanindra KolluruNessuna valutazione finora
- Central User AdministrationDocumento4 pagineCentral User Administrationapi-3832199100% (2)
- File 2 FileDocumento1 paginaFile 2 FileDinakar Babu JangaNessuna valutazione finora
- HANA Sizing Reprot ProcedureDocumento6 pagineHANA Sizing Reprot ProcedureDinakar Babu JangaNessuna valutazione finora
- About SAP GatewayDocumento12 pagineAbout SAP GatewayDinakar Babu JangaNessuna valutazione finora
- IDOC - Intermediate Document: InterchangeDocumento19 pagineIDOC - Intermediate Document: InterchangeDinakar Babu JangaNessuna valutazione finora
- SAP Implementation PhasesDocumento7 pagineSAP Implementation PhasesDinakar Babu JangaNessuna valutazione finora
- Creating A Secondary IndexDocumento3 pagineCreating A Secondary IndexDinakar Babu JangaNessuna valutazione finora
- Kernel Paramers For NW 7.4Documento1 paginaKernel Paramers For NW 7.4Dinakar Babu JangaNessuna valutazione finora
- SAP Adaptive Server EnterpriseDocumento3 pagineSAP Adaptive Server EnterpriseDinakar Babu JangaNessuna valutazione finora
- SnoteDocumento10 pagineSnoteDinakar Babu JangaNessuna valutazione finora
- Support Packs PhasesDocumento16 pagineSupport Packs PhasesDinakar Babu JangaNessuna valutazione finora
- Sap On SleDocumento120 pagineSap On SleDinakar Babu JangaNessuna valutazione finora
- SAP Sybase Database ASE Installation Steps On LinuxDocumento20 pagineSAP Sybase Database ASE Installation Steps On LinuxDinakar Babu JangaNessuna valutazione finora
- Server For Inst HanaDocumento16 pagineServer For Inst HanaDinakar Babu JangaNessuna valutazione finora
- Imp Note - NWA SiteDocumento4 pagineImp Note - NWA SiteDinakar Babu JangaNessuna valutazione finora
- Sybase ASE Developer Edition Linux Installation GuideDocumento8 pagineSybase ASE Developer Edition Linux Installation GuideDinakar Babu JangaNessuna valutazione finora
- Expert 24lx ManualDocumento140 pagineExpert 24lx ManualDiana ArghirNessuna valutazione finora
- 3S21 1-ModelDocumento1 pagina3S21 1-ModelFaisal KhanNessuna valutazione finora
- TAFJ-Oracle Install 12cR1Documento18 pagineTAFJ-Oracle Install 12cR1ganeshjayanthiNessuna valutazione finora
- Lecture 04 Layering ArchitectureDocumento23 pagineLecture 04 Layering ArchitectureAnshulNessuna valutazione finora
- Dbms Project Report: Agricultural Sales Management SystemDocumento20 pagineDbms Project Report: Agricultural Sales Management System2K18/ME/202 SAURAV BANSALNessuna valutazione finora
- Midshire Business Systems - Sharp MX-M182D / 202D / 232D 8pp Multifunction Mono Printers BrochureDocumento8 pagineMidshire Business Systems - Sharp MX-M182D / 202D / 232D 8pp Multifunction Mono Printers BrochureadietoppingNessuna valutazione finora
- ESCUELA INDUSTRIAL SUPERIOR PEDRO DOMINGO MURILLO InglesDocumento23 pagineESCUELA INDUSTRIAL SUPERIOR PEDRO DOMINGO MURILLO InglesAlejandrita NattesNessuna valutazione finora
- MicroStrategy Mobile TheBestPlatformForEnterpriseAppsDocumento6 pagineMicroStrategy Mobile TheBestPlatformForEnterpriseAppssarav.karthikNessuna valutazione finora
- WINCC Runtime Professional S7-Graph Overview and PLC Code ViewerDocumento35 pagineWINCC Runtime Professional S7-Graph Overview and PLC Code ViewerCarlos Octavio Gamarra LimaNessuna valutazione finora
- ICX Active-9: The Brand New Strong and Compact Active Coin SorterDocumento2 pagineICX Active-9: The Brand New Strong and Compact Active Coin SortersharkieNessuna valutazione finora
- Building Serverless App PythonDocumento266 pagineBuilding Serverless App PythonMatei Danut100% (3)
- Jobsheet 6 - TI2B - 07 - Dwi Suci AmliapdfDocumento26 pagineJobsheet 6 - TI2B - 07 - Dwi Suci AmliapdfDwi SuciNessuna valutazione finora
- Microcontroller PPT 1Documento23 pagineMicrocontroller PPT 1Luckmore Maponga100% (1)
- OOP Assignment.Documento8 pagineOOP Assignment.Syed Dawood ShahNessuna valutazione finora
- MongoDB Cheat Sheet Red Hat DeveloperDocumento16 pagineMongoDB Cheat Sheet Red Hat DeveloperYãsh ßhúvaNessuna valutazione finora
- ELS 01 November 2023 Rev 1.0Documento21 pagineELS 01 November 2023 Rev 1.0Smaba OrahitzNessuna valutazione finora
- Mistel MD600 User ManualDocumento2 pagineMistel MD600 User ManualChin Wang YiuNessuna valutazione finora
- Qpad x5 ManualDocumento48 pagineQpad x5 Manualx9erNessuna valutazione finora
- Cluster 4 TAP-Project - 25 09 2020 v1 3 - Checklist StudentDocumento21 pagineCluster 4 TAP-Project - 25 09 2020 v1 3 - Checklist StudentArthur InuguNessuna valutazione finora
- Unit III Levels of TestingDocumento42 pagineUnit III Levels of TestingPallavi BhartiNessuna valutazione finora
- Elec DVR Quick Start GuideDocumento15 pagineElec DVR Quick Start Guidebcgreene84Nessuna valutazione finora
- Hortonworks Sandbox SetupDocumento12 pagineHortonworks Sandbox SetupnguzNessuna valutazione finora
- Fsal Usage 12214Documento17 pagineFsal Usage 12214Matej DrageljevicNessuna valutazione finora
- setPartInformation (V2.0) - v17-20230130 - 144945Documento11 paginesetPartInformation (V2.0) - v17-20230130 - 144945LucienNessuna valutazione finora
- Guru99 Article TopicsDocumento4 pagineGuru99 Article Topicssadaqat_aliiNessuna valutazione finora
- Kronos C3 Brochure April 2016Documento3 pagineKronos C3 Brochure April 2016Aris AriyadiNessuna valutazione finora
- Expradv FilelistDocumento78 pagineExpradv FilelistlamorraesaNessuna valutazione finora
- HCP VM Deployment PDFDocumento187 pagineHCP VM Deployment PDFAdhe Widi AstatoNessuna valutazione finora