Potrebbero piacerti anche
- Beginners Guide To WinDBG Part-1Documento6 pagineBeginners Guide To WinDBG Part-1Boss MassNessuna valutazione finora
- Confident Programmer Debugging Guide: Confident ProgrammerDa EverandConfident Programmer Debugging Guide: Confident ProgrammerNessuna valutazione finora
- Embedded Linux System Development Training Lab BookDocumento4 pagineEmbedded Linux System Development Training Lab BookanmolneelNessuna valutazione finora
- Application Support A Complete Guide - 2020 EditionDa EverandApplication Support A Complete Guide - 2020 EditionNessuna valutazione finora
- Tools To Aid Debugging On AIXDocumento12 pagineTools To Aid Debugging On AIXYoussifAhmedJulaihNessuna valutazione finora
- Let's Use Bash on Windows 10! The Lite versionDa EverandLet's Use Bash on Windows 10! The Lite versionNessuna valutazione finora
- Software ListingDocumento5 pagineSoftware ListingStefan RadaNessuna valutazione finora
- Creating and Managing Virtual Machines and Networks Through Microsoft Azure Services for Remote Access ConnectionDa EverandCreating and Managing Virtual Machines and Networks Through Microsoft Azure Services for Remote Access ConnectionNessuna valutazione finora
- DB Final ProjectDocumento27 pagineDB Final ProjectRida Qureshi100% (1)
- R12 Overview of Issuing PaymentsDocumento22 pagineR12 Overview of Issuing Paymentsraacero100% (2)
- Dream Doxing: by Databuster: Good LuckDocumento7 pagineDream Doxing: by Databuster: Good LuckTechno Parag0% (1)
- Simple C# Notepad With The Option To Clear, Cut, Copy, PasteDocumento7 pagineSimple C# Notepad With The Option To Clear, Cut, Copy, PastePrashant KumarNessuna valutazione finora
- RSI Forensics Project 1 EER in HOT in DUrbanDocumento11 pagineRSI Forensics Project 1 EER in HOT in DUrbana2zconsultantsjprNessuna valutazione finora
- NMAP Command Guide SheetDocumento5 pagineNMAP Command Guide SheetRafoo MGNessuna valutazione finora
- CrackzDocumento29 pagineCrackzGabriel TellesNessuna valutazione finora
- Packet SniffersDocumento42 paginePacket SniffersAmit BoraNessuna valutazione finora
- Oracle Advanced CompressionDocumento2 pagineOracle Advanced CompressiondbareddyNessuna valutazione finora
- Installing VMWARE Server On CentOS 5 or Red Hat Enterprise Linux Version & Linux WgerDocumento14 pagineInstalling VMWARE Server On CentOS 5 or Red Hat Enterprise Linux Version & Linux WgerAshi SharmaNessuna valutazione finora
- ELearnSecurity ECPPT Notes ExamDocumento157 pagineELearnSecurity ECPPT Notes ExamAngel CabralesNessuna valutazione finora
- Cut, Copy and PasteDocumento10 pagineCut, Copy and PasteThessaloe B. FernandezNessuna valutazione finora
- WLAN SecurityDocumento20 pagineWLAN SecurityPankia Mer AmunNessuna valutazione finora
- Intitle:"Adsl Configuration Page"Intitle:"Azu Reus: Java Bittorrentclient Tracker"Intitle:" Belarcadvisorcu Rrentprofile" Intext:"ClickDocumento68 pagineIntitle:"Adsl Configuration Page"Intitle:"Azu Reus: Java Bittorrentclient Tracker"Intitle:" Belarcadvisorcu Rrentprofile" Intext:"ClickTOUSIFRAZAKHAN100% (1)
- All Projects ListDocumento20 pagineAll Projects ListGanji GirishNessuna valutazione finora
- Online Banking SoftwareDocumento16 pagineOnline Banking SoftwareBeverly WoodNessuna valutazione finora
- Chapter 3 - Working in Linux: ObjectivesDocumento20 pagineChapter 3 - Working in Linux: ObjectivesSai Vamsi Gandham100% (1)
- WiresharkDocumento8 pagineWiresharkLakshay MathurNessuna valutazione finora
- Drop Shipment: Safe Harbor StatementDocumento25 pagineDrop Shipment: Safe Harbor StatementPrahant KumarNessuna valutazione finora
- Squid Proxy Server TutorialDocumento7 pagineSquid Proxy Server Tutorialsn_moorthyNessuna valutazione finora
- Current NixOS PackagesDocumento520 pagineCurrent NixOS PackagespvnaaNessuna valutazione finora
- Mil Key WordsDocumento10 pagineMil Key WordsKris Lea Delos SantosNessuna valutazione finora
- Beginners Guide To Arch LinuxDocumento33 pagineBeginners Guide To Arch Linuxlga_scribdNessuna valutazione finora
- (WEP N WPA) Using Beini Minidwep-Gtk by Ayen46@Syok - Org Credit ToDocumento7 pagine(WEP N WPA) Using Beini Minidwep-Gtk by Ayen46@Syok - Org Credit ToAkasyah AShNessuna valutazione finora
- Cybereason Cobalt Kitty - AnswersDocumento15 pagineCybereason Cobalt Kitty - AnswersMuhammad AliNessuna valutazione finora
- Bank Management SystemDocumento5 pagineBank Management SystemShreenath SrivastavaNessuna valutazione finora
- Command Vps Auto ScriptDocumento2 pagineCommand Vps Auto ScriptWong CerbonNessuna valutazione finora
- Configuration Microsoft Windows Server 2019: For System ProvidersDocumento39 pagineConfiguration Microsoft Windows Server 2019: For System ProvidersChristopher Cesti CastroNessuna valutazione finora
- Amazon Route 53 FAQsDocumento32 pagineAmazon Route 53 FAQsasassaNessuna valutazione finora
- Oracle EBS R 12.2.3 Creating Bank AccountDocumento5 pagineOracle EBS R 12.2.3 Creating Bank AccountdbaahsumonbdNessuna valutazione finora
- Hack Hack101Documento3 pagineHack Hack101api-3745663Nessuna valutazione finora
- Getting Started With The CC SDKDocumento6 pagineGetting Started With The CC SDKBojan KojovicNessuna valutazione finora
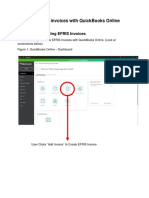
- Creating EFRIS Invoices With QuickBooks OnlineDocumento5 pagineCreating EFRIS Invoices With QuickBooks OnlineFarly DetriasNessuna valutazione finora
- AG2425 Spatial DatabasesDocumento36 pagineAG2425 Spatial DatabasessriniNessuna valutazione finora
- Website Payment Technology GuideDocumento18 pagineWebsite Payment Technology GuideYashNessuna valutazione finora
- LogsDocumento5 pagineLogsEkta TayalNessuna valutazione finora
- Hacking MAAS: Coding StyleDocumento7 pagineHacking MAAS: Coding StyleManuela TaverasNessuna valutazione finora
- How To Join A Ubuntu Machine To A Windows Domain - LinuxDocumento4 pagineHow To Join A Ubuntu Machine To A Windows Domain - LinuxAref MGHNessuna valutazione finora
- Ultimate Finacle Commands Used For BankingDocumento48 pagineUltimate Finacle Commands Used For BankingJayant100% (1)
- Dos AttackedDocumento4 pagineDos Attackedpaul_17oct@yahoo.co.in100% (2)
- Password ProtectionDocumento35 paginePassword ProtectionNitin BirariNessuna valutazione finora
- Openreports-Install-Guide-1 0Documento19 pagineOpenreports-Install-Guide-1 0george100% (2)
- Oracle AR Credit Card Issue SetupsDocumento21 pagineOracle AR Credit Card Issue SetupsMag Marina50% (2)
- SLO Assignment 1Documento3 pagineSLO Assignment 1eveswan2008Nessuna valutazione finora
- ExternalizationDocumento14 pagineExternalizationapi-254961130Nessuna valutazione finora
- Software ListDocumento31 pagineSoftware ListAnonymous yW1lcIy100% (1)
- How To Configure SUDODocumento6 pagineHow To Configure SUDOraghurampolaNessuna valutazione finora
- Credit Card Setup in AR Document 1357967Documento11 pagineCredit Card Setup in AR Document 1357967Madhuri UppalaNessuna valutazione finora
- Make Money Surfing The WebDocumento11 pagineMake Money Surfing The Webclash designNessuna valutazione finora
- Windows Tips CollectionDocumento8 pagineWindows Tips CollectionahamedshifanNessuna valutazione finora
- 182469Documento19 pagine182469PSGNessuna valutazione finora
- History 1Documento12 pagineHistory 1PSGNessuna valutazione finora
- Mewar Ramayana ManuscriptsDocumento25 pagineMewar Ramayana ManuscriptsPSGNessuna valutazione finora
- The Ali Rajas of Cannanore: Status and Identity at The Interface of Commercial and Political Expansion, 1663-1723Documento9 pagineThe Ali Rajas of Cannanore: Status and Identity at The Interface of Commercial and Political Expansion, 1663-1723PSGNessuna valutazione finora
- Select Bibliography: I Primary Sources (Printed)Documento18 pagineSelect Bibliography: I Primary Sources (Printed)PSGNessuna valutazione finora
- By J R : Notes Rec. (2019) 73, 149-166 Doi:10.1098/rsnr.2018.0039 Published Online 28 November 2018Documento18 pagineBy J R : Notes Rec. (2019) 73, 149-166 Doi:10.1098/rsnr.2018.0039 Published Online 28 November 2018PSGNessuna valutazione finora
- Notes On The Manufactures of Pottery in AssamDocumento16 pagineNotes On The Manufactures of Pottery in AssamPSGNessuna valutazione finora
- ArcheologyDocumento9 pagineArcheologyPSGNessuna valutazione finora
- EpigraphyDocumento3 pagineEpigraphyPSG100% (1)
- Temples and Legends of KeralaDocumento254 pagineTemples and Legends of KeralaPSG0% (1)
- MOHAMANA Bhairavi Varnam in Tiruvarur DDocumento9 pagineMOHAMANA Bhairavi Varnam in Tiruvarur DPSGNessuna valutazione finora
- Judges of The Chief CourtDocumento3 pagineJudges of The Chief CourtPSGNessuna valutazione finora
- Kusinagara00pati PDFDocumento50 pagineKusinagara00pati PDFPSGNessuna valutazione finora
- The CharmDocumento170 pagineThe CharmPSGNessuna valutazione finora
- 01 - Title Page PDFDocumento1 pagina01 - Title Page PDFPSGNessuna valutazione finora
- Gerard Foekema: An Analysis of Indian Temple ArchitectureDocumento3 pagineGerard Foekema: An Analysis of Indian Temple ArchitecturePSGNessuna valutazione finora
- Historical Perspective of Motifs and OrnamentationDocumento60 pagineHistorical Perspective of Motifs and OrnamentationPSGNessuna valutazione finora
- YiuyDocumento4 pagineYiuyPSGNessuna valutazione finora
- 01 - Title Page PDFDocumento1 pagina01 - Title Page PDFPSGNessuna valutazione finora
- ElectorialDocumento1 paginaElectorialPSGNessuna valutazione finora
- FamDocumento4 pagineFamPSGNessuna valutazione finora
- A New Form of Cosmic Siva From Kerala - PDDocumento8 pagineA New Form of Cosmic Siva From Kerala - PDPSGNessuna valutazione finora
- EligibilityDocumento1 paginaEligibilityPSGNessuna valutazione finora
- Chennai NoiseDocumento1 paginaChennai NoisePSGNessuna valutazione finora
- TumbooDocumento3 pagineTumbooPSGNessuna valutazione finora
- BiographyDocumento2 pagineBiographyPSGNessuna valutazione finora
- The Hindu Memories Come A Tram-FullDocumento5 pagineThe Hindu Memories Come A Tram-FullPSGNessuna valutazione finora
- PadamDocumento1 paginaPadamPSGNessuna valutazione finora
- ElectionDocumento1 paginaElectionPSGNessuna valutazione finora
- Telephone Triage For Oncology Nurses Print Replica Ebook PDFDocumento57 pagineTelephone Triage For Oncology Nurses Print Replica Ebook PDFdaniel.salazar678100% (37)
- Aja052550590 786Documento13 pagineAja052550590 786EugeneSeasoleNessuna valutazione finora
- Critical Thinking and The Nursing ProcessDocumento22 pagineCritical Thinking and The Nursing ProcessAnnapurna DangetiNessuna valutazione finora
- Thermal Conductivity and Heat Transfer in Coal SlagDocumento17 pagineThermal Conductivity and Heat Transfer in Coal SlagBun YaminNessuna valutazione finora
- Factors Influencing The PerceptionDocumento1 paginaFactors Influencing The PerceptionTinesh Kumar100% (1)
- CrimLaw2 Reviewer (2007 BarOps) PDFDocumento158 pagineCrimLaw2 Reviewer (2007 BarOps) PDFKarla EspinosaNessuna valutazione finora
- Cover Letter-Alexis ReedDocumento1 paginaCover Letter-Alexis Reedapi-252291947Nessuna valutazione finora
- Word FormationDocumento3 pagineWord Formationamalia9bochisNessuna valutazione finora
- Saham LQ 20Documento21 pagineSaham LQ 20ALDI.S. TUBENessuna valutazione finora
- 112-1 中英筆譯Documento15 pagine112-1 中英筆譯beenbenny825Nessuna valutazione finora
- Spouses Roque vs. AguadoDocumento14 pagineSpouses Roque vs. AguadoMary May AbellonNessuna valutazione finora
- DECLAMATIONDocumento19 pagineDECLAMATIONJohn Carlos Wee67% (3)
- Complete Wedding With DJ Worksheets.4pgsDocumento4 pagineComplete Wedding With DJ Worksheets.4pgsDanniNessuna valutazione finora
- Powerful Hero Dpa Rtsal Protective DeityDocumento50 paginePowerful Hero Dpa Rtsal Protective DeityjinpaNessuna valutazione finora
- RR 1116Documento72 pagineRR 1116Кирилл КрыловNessuna valutazione finora
- Jaw Crusher Kinematics Simulation and AnalysisDocumento5 pagineJaw Crusher Kinematics Simulation and AnalysisInternational Journal of Research in Engineering and ScienceNessuna valutazione finora
- 4067 XLS EngDocumento11 pagine4067 XLS EngMILIND SHEKHARNessuna valutazione finora
- Behind The Scrubs: Monica Velarde Saint Mary's College December 09, 2008Documento21 pagineBehind The Scrubs: Monica Velarde Saint Mary's College December 09, 2008EthanNessuna valutazione finora
- G.R. No. 92735 Monarch V CA - DigestDocumento2 pagineG.R. No. 92735 Monarch V CA - DigestOjie Santillan100% (1)
- Dental MneumonicDocumento30 pagineDental Mneumonictmle44% (9)
- Activateroom HLDZDocumento11 pagineActivateroom HLDZPerinorte100% (2)
- DPP-Control and Coordination (Prashant Kirad)Documento9 pagineDPP-Control and Coordination (Prashant Kirad)ABHI TECH 983Nessuna valutazione finora
- Social Defence Vision 2020: Dr. Hira Singh Former Director National Institute of Social DefenceDocumento19 pagineSocial Defence Vision 2020: Dr. Hira Singh Former Director National Institute of Social DefencePASION Jovelyn M.Nessuna valutazione finora
- CC 109 - MLGCLDocumento25 pagineCC 109 - MLGCLClark QuayNessuna valutazione finora
- Upload - 00083938 - 1499831786562 BOND MAXDocumento17 pagineUpload - 00083938 - 1499831786562 BOND MAXkrsrinivasarajuNessuna valutazione finora
- Prompts QueryDocumento4 paginePrompts Querysatyanarayana NVSNessuna valutazione finora
- Self Incompatibility: Dr. L.K.GangwarDocumento38 pagineSelf Incompatibility: Dr. L.K.GangwarSiddhant Singh100% (1)
- y D Starter PDFDocumento13 paginey D Starter PDFnazar750Nessuna valutazione finora
- CAM386 Tannenberg 1914 Destruction of The Russian Second ArmyDocumento97 pagineCAM386 Tannenberg 1914 Destruction of The Russian Second ArmyCesarPastenSozaNessuna valutazione finora
- Theatrical Script Legend of La LloronaDocumento2 pagineTheatrical Script Legend of La LloronaScribdTranslationsNessuna valutazione finora
- iPhone Unlocked for the Non-Tech Savvy: Color Images & Illustrated Instructions to Simplify the Smartphone Use for Beginners & Seniors [COLOR EDITION]Da EverandiPhone Unlocked for the Non-Tech Savvy: Color Images & Illustrated Instructions to Simplify the Smartphone Use for Beginners & Seniors [COLOR EDITION]Valutazione: 5 su 5 stelle5/5 (2)
- iPhone 14 Guide for Seniors: Unlocking Seamless Simplicity for the Golden Generation with Step-by-Step ScreenshotsDa EverandiPhone 14 Guide for Seniors: Unlocking Seamless Simplicity for the Golden Generation with Step-by-Step ScreenshotsValutazione: 5 su 5 stelle5/5 (2)
- RHCSA Red Hat Enterprise Linux 9: Training and Exam Preparation Guide (EX200), Third EditionDa EverandRHCSA Red Hat Enterprise Linux 9: Training and Exam Preparation Guide (EX200), Third EditionNessuna valutazione finora
- Kali Linux - An Ethical Hacker's Cookbook - Second Edition: Practical recipes that combine strategies, attacks, and tools for advanced penetration testing, 2nd EditionDa EverandKali Linux - An Ethical Hacker's Cookbook - Second Edition: Practical recipes that combine strategies, attacks, and tools for advanced penetration testing, 2nd EditionValutazione: 5 su 5 stelle5/5 (1)
- Linux For Beginners: The Comprehensive Guide To Learning Linux Operating System And Mastering Linux Command Line Like A ProDa EverandLinux For Beginners: The Comprehensive Guide To Learning Linux Operating System And Mastering Linux Command Line Like A ProNessuna valutazione finora
- Excel : The Ultimate Comprehensive Step-By-Step Guide to the Basics of Excel Programming: 1Da EverandExcel : The Ultimate Comprehensive Step-By-Step Guide to the Basics of Excel Programming: 1Valutazione: 4.5 su 5 stelle4.5/5 (3)
- Azure DevOps Engineer: Exam AZ-400: Azure DevOps Engineer: Exam AZ-400 Designing and Implementing Microsoft DevOps SolutionsDa EverandAzure DevOps Engineer: Exam AZ-400: Azure DevOps Engineer: Exam AZ-400 Designing and Implementing Microsoft DevOps SolutionsNessuna valutazione finora
- Hacking : The Ultimate Comprehensive Step-By-Step Guide to the Basics of Ethical HackingDa EverandHacking : The Ultimate Comprehensive Step-By-Step Guide to the Basics of Ethical HackingValutazione: 5 su 5 stelle5/5 (3)
- Linux: A Comprehensive Guide to Linux Operating System and Command LineDa EverandLinux: A Comprehensive Guide to Linux Operating System and Command LineNessuna valutazione finora
- MAC OS X UNIX Toolbox: 1000+ Commands for the Mac OS XDa EverandMAC OS X UNIX Toolbox: 1000+ Commands for the Mac OS XNessuna valutazione finora
- Mastering Linux Security and Hardening - Second Edition: Protect your Linux systems from intruders, malware attacks, and other cyber threats, 2nd EditionDa EverandMastering Linux Security and Hardening - Second Edition: Protect your Linux systems from intruders, malware attacks, and other cyber threats, 2nd EditionNessuna valutazione finora
- React.js for A Beginners Guide : From Basics to Advanced - A Comprehensive Guide to Effortless Web Development for Beginners, Intermediates, and ExpertsDa EverandReact.js for A Beginners Guide : From Basics to Advanced - A Comprehensive Guide to Effortless Web Development for Beginners, Intermediates, and ExpertsNessuna valutazione finora
- Mastering Swift 5 - Fifth Edition: Deep dive into the latest edition of the Swift programming language, 5th EditionDa EverandMastering Swift 5 - Fifth Edition: Deep dive into the latest edition of the Swift programming language, 5th EditionNessuna valutazione finora
- The iPadOS 17: The Complete User Manual to Quick Set Up and Mastering the iPadOS 17 with New Features, Pictures, Tips, and TricksDa EverandThe iPadOS 17: The Complete User Manual to Quick Set Up and Mastering the iPadOS 17 with New Features, Pictures, Tips, and TricksNessuna valutazione finora