Potrebbero piacerti anche
- The 2016 Presidential Election-An Abundance of ControversiesDocumento20 pagineThe 2016 Presidential Election-An Abundance of ControversiesHoover InstitutionNessuna valutazione finora
- Book Summary The Secrets of Millionaire MindDocumento5 pagineBook Summary The Secrets of Millionaire MindRajeev Bahuguna100% (7)
- Statistics 1232445944520487 1Documento101 pagineStatistics 1232445944520487 1lieynna4996Nessuna valutazione finora
- Criminological ResearchDocumento209 pagineCriminological ResearchBRYANTRONICO50% (2)
- Discriptive StatisticsDocumento50 pagineDiscriptive StatisticsSwathi JanardhanNessuna valutazione finora
- 3 - Logical Framework Analysis - ApproachDocumento35 pagine3 - Logical Framework Analysis - ApproachMuhammad SajidNessuna valutazione finora
- Mitchelle T Magadzire Dissertation R151541VDocumento81 pagineMitchelle T Magadzire Dissertation R151541Vvanyywalters1987100% (3)
- 11 Ways To Be Passive Aggressive - An Essential Pocket Guide - Talking ShrimpDocumento18 pagine11 Ways To Be Passive Aggressive - An Essential Pocket Guide - Talking ShrimpRehab WahshNessuna valutazione finora
- Burke and English Historical SchoolDocumento6 pagineBurke and English Historical SchoolCarlos105Nessuna valutazione finora
- Assignment 1: Aboriginal Education (Critically Reflective Essay)Documento11 pagineAssignment 1: Aboriginal Education (Critically Reflective Essay)api-355889713Nessuna valutazione finora
- God's Law and SocietyDocumento92 pagineGod's Law and SocietyNarrowPathPilgrim100% (5)
- 1-A Business Model Framework For The Design and Evaluation of Business Models in The Internet of ServicesDocumento13 pagine1-A Business Model Framework For The Design and Evaluation of Business Models in The Internet of ServicesmamatnamakuNessuna valutazione finora
- Uganda Management Institute DPAM 2014/2015Documento4 pagineUganda Management Institute DPAM 2014/2015Fred OchiengNessuna valutazione finora
- Data Are Collection of Any Number of Related ObservationsDocumento13 pagineData Are Collection of Any Number of Related Observationsolive103Nessuna valutazione finora
- Katushabe Hellen - E - Learning Platforms in UgandaDocumento20 pagineKatushabe Hellen - E - Learning Platforms in UgandaHellen KatushabeNessuna valutazione finora
- Assignment 1 (Descriptive Analysis)Documento4 pagineAssignment 1 (Descriptive Analysis)Anum SolehahNessuna valutazione finora
- Martha Olwenyi 0772574677: Result Based Monitoring & EvaluationDocumento38 pagineMartha Olwenyi 0772574677: Result Based Monitoring & EvaluationRonald Matsiko100% (1)
- Challenges of Implementing Agricultural Policy in UgandaDocumento26 pagineChallenges of Implementing Agricultural Policy in UgandaAfrican Centre for Media Excellence100% (5)
- Chalimbana Research Report FinaDocumento43 pagineChalimbana Research Report Finapaul chishimbaNessuna valutazione finora
- Project Prorposal IT and Information TechnologyDocumento100 pagineProject Prorposal IT and Information Technologyahishakiyeemma_18039Nessuna valutazione finora
- Sample Business Proposal Impact of Microfinance in KenyaDocumento64 pagineSample Business Proposal Impact of Microfinance in Kenyayedinkachaw shferawNessuna valutazione finora
- Rev. Fr. Odubuker Picho Epiphany, PHD: Epiphanyodubuker@yahoo - Co.ukDocumento11 pagineRev. Fr. Odubuker Picho Epiphany, PHD: Epiphanyodubuker@yahoo - Co.ukbob senyangeNessuna valutazione finora
- Economic Efficiency Analysis of Smallholder Sorghum Producers in West Hararghe Zone, Ethiopia.Documento8 pagineEconomic Efficiency Analysis of Smallholder Sorghum Producers in West Hararghe Zone, Ethiopia.Premier PublishersNessuna valutazione finora
- Introduction BS FinalDocumento54 pagineIntroduction BS FinalsathravguptaNessuna valutazione finora
- Case Study ProposalDocumento5 pagineCase Study ProposalTadele DandenaNessuna valutazione finora
- Proposal 3Documento17 pagineProposal 3KababaNessuna valutazione finora
- Business Statistics Module - 1 Introduction-Meaning, Definition, Functions, Objectives and Importance of StatisticsDocumento5 pagineBusiness Statistics Module - 1 Introduction-Meaning, Definition, Functions, Objectives and Importance of StatisticsPnx RageNessuna valutazione finora
- BD Hypothesis Testing WSDocumento4 pagineBD Hypothesis Testing WSAdarsh KumarNessuna valutazione finora
- Sectorial Planning VS Integrated PlanningDocumento3 pagineSectorial Planning VS Integrated PlanningMuhammad IDREES KHANNessuna valutazione finora
- Measurement of Variation Dispersion 2Documento25 pagineMeasurement of Variation Dispersion 2diana nyamisaNessuna valutazione finora
- 1 - Descriptive Statistics Data: Frequency DistributionDocumento57 pagine1 - Descriptive Statistics Data: Frequency DistributionspecialityNessuna valutazione finora
- X X X X N X N: 1. Discuss/define Three Measures of Central TendencyDocumento7 pagineX X X X N X N: 1. Discuss/define Three Measures of Central TendencyPandurang ThatkarNessuna valutazione finora
- 5Documento16 pagine5Sanya BajajNessuna valutazione finora
- Data Analysis: Kulwant Singh KapoorDocumento60 pagineData Analysis: Kulwant Singh KapoorTripty Khanna KarwalNessuna valutazione finora
- Measures of Dispersion - Range, Deviation and Variance With ExamplesDocumento14 pagineMeasures of Dispersion - Range, Deviation and Variance With ExamplesDCNessuna valutazione finora
- Week 2 Measures of Dispersion IIDocumento34 pagineWeek 2 Measures of Dispersion IITildaNessuna valutazione finora
- B9ed0measures of Central TendencyDocumento36 pagineB9ed0measures of Central TendencyGeetanshi AgarwalNessuna valutazione finora
- Assignment IIDocumento5 pagineAssignment IIsarah josephNessuna valutazione finora
- Dispersion 1Documento32 pagineDispersion 1Karishma ChaudharyNessuna valutazione finora
- Jurnal StatistikDocumento7 pagineJurnal StatistikAry PratiwiNessuna valutazione finora
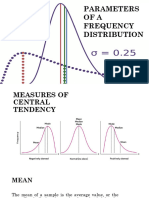
- Week 3 Parameters of A Frequency DistributionDocumento36 pagineWeek 3 Parameters of A Frequency DistributionJuliana Alexis MalabadNessuna valutazione finora
- Worksheets-Importance of MathematicsDocumento38 pagineWorksheets-Importance of MathematicsHarsh VyasNessuna valutazione finora
- CH 1-Data Condensation and Graphical MethodsDocumento16 pagineCH 1-Data Condensation and Graphical MethodsVishal Padhar100% (2)
- Study of Averages FinalDocumento111 pagineStudy of Averages FinalVishal KumarNessuna valutazione finora
- BIOSTATISTICSDocumento52 pagineBIOSTATISTICSbelachew meleseNessuna valutazione finora
- Measures of DispersionDocumento26 pagineMeasures of DispersionDrAmit VermaNessuna valutazione finora
- Statistical Inference: Prepared By: Antonio E. Chan, M.DDocumento227 pagineStatistical Inference: Prepared By: Antonio E. Chan, M.Dश्रीकांत शरमाNessuna valutazione finora
- TRISEM14-2021-22 BMT5113 TH VL2021220200049 Reference Material I 04-Aug-2021 Measures of DispersionDocumento59 pagineTRISEM14-2021-22 BMT5113 TH VL2021220200049 Reference Material I 04-Aug-2021 Measures of DispersionVickyNessuna valutazione finora
- 4.0 Measures of Skewness - Dispersion - VariabilityDocumento8 pagine4.0 Measures of Skewness - Dispersion - VariabilityBridget MatutuNessuna valutazione finora
- GE 104 Module 4Documento24 pagineGE 104 Module 4TeacherNessuna valutazione finora
- Basic StatisticsDocumento31 pagineBasic StatisticsStudyLaw pendialaNessuna valutazione finora
- Mb0040 - Statistics For Management: Mba Semester 1Documento16 pagineMb0040 - Statistics For Management: Mba Semester 1sphebbarNessuna valutazione finora
- Mb0040 - Statistics For Management: Mba Semester 1Documento16 pagineMb0040 - Statistics For Management: Mba Semester 1PushhpaNessuna valutazione finora
- ShapesDocumento36 pagineShapesaue.ponytoyNessuna valutazione finora
- Chapter - 4 DispersionDocumento10 pagineChapter - 4 DispersionKishan GuptaNessuna valutazione finora
- Quartile Deviation Chap3Documento11 pagineQuartile Deviation Chap3Ishwar Chandra100% (1)
- 2 Mean Median Mode VarianceDocumento29 pagine2 Mean Median Mode VarianceBonita Mdoda-ArmstrongNessuna valutazione finora
- Statistic Sample Question IiswbmDocumento15 pagineStatistic Sample Question IiswbmMudasarSNessuna valutazione finora
- Chapter 2Documento30 pagineChapter 2DesignNessuna valutazione finora
- Prob and Stats NotesDocumento22 pagineProb and Stats NotesbuTchaNessuna valutazione finora
- Mean Deviation: (For M.B.A. I Semester)Documento20 pagineMean Deviation: (For M.B.A. I Semester)Arun MishraNessuna valutazione finora
- L7 EstimationDocumento5 pagineL7 EstimationSaif UzZolNessuna valutazione finora
- Data AnalysisDocumento4 pagineData AnalysisRjian LlanesNessuna valutazione finora
- UsingStdNormalDataAnalysisKEO 1107Documento3 pagineUsingStdNormalDataAnalysisKEO 1107misterkenoNessuna valutazione finora
- List The Importance of Data Analysis in Daily LifeDocumento22 pagineList The Importance of Data Analysis in Daily LifeKogilan Bama Daven100% (1)
- Statistics For Managers - MB0040 (Assignment Winter 2013)Documento13 pagineStatistics For Managers - MB0040 (Assignment Winter 2013)Merwin AlvaNessuna valutazione finora
- Lecture 8 Statitical InferenceDocumento54 pagineLecture 8 Statitical InferenceSomia ZohaibNessuna valutazione finora
- Descriptive Statistics - Numerical MeasuresDocumento102 pagineDescriptive Statistics - Numerical MeasuresKautik ShahNessuna valutazione finora
- Ahmedmohamedjama: Curriculum Vitae: October 15 Ahmed Mohamed JamaDocumento5 pagineAhmedmohamedjama: Curriculum Vitae: October 15 Ahmed Mohamed JamaFred OchiengNessuna valutazione finora
- Fredochieng':Curriculum Vitae: Quickbooks, Pastel, Sage, Excel Among OthersDocumento6 pagineFredochieng':Curriculum Vitae: Quickbooks, Pastel, Sage, Excel Among OthersFred OchiengNessuna valutazione finora
- Techniques On The Sales Revenue of Bollore Africa Logistic Company''Documento4 pagineTechniques On The Sales Revenue of Bollore Africa Logistic Company''Fred OchiengNessuna valutazione finora
- Ircu Pastoral Handbook A5 c2Documento17 pagineIrcu Pastoral Handbook A5 c2Fred OchiengNessuna valutazione finora
- Car AgreementDocumento1 paginaCar AgreementFred OchiengNessuna valutazione finora
- NINATS New Profile - Catering Edit 1Documento14 pagineNINATS New Profile - Catering Edit 1Fred OchiengNessuna valutazione finora
- NSSF-Ninats Service Feedback FormDocumento1 paginaNSSF-Ninats Service Feedback FormFred OchiengNessuna valutazione finora
- P.O BOX, 00110 Mars TEL +256781980345 Website: Tec: Nancy Daniel 605 University of TechnologyDocumento2 pagineP.O BOX, 00110 Mars TEL +256781980345 Website: Tec: Nancy Daniel 605 University of TechnologyFred OchiengNessuna valutazione finora
- Category of Population Population: Market Vendors 325 Shop Owners 325 Animal Rearing 325 Others 325Documento14 pagineCategory of Population Population: Market Vendors 325 Shop Owners 325 Animal Rearing 325 Others 325Fred OchiengNessuna valutazione finora
- Revised QuatationDocumento3 pagineRevised QuatationFred OchiengNessuna valutazione finora
- Re: Request To Use Your Company As A Case Study of My Academic ResearchDocumento1 paginaRe: Request To Use Your Company As A Case Study of My Academic ResearchFred OchiengNessuna valutazione finora
- Wednesday, March 4, 2015: Tangerine (U) LTD P.O Box 37136 Plot 26, Kanjokya Street, Kamwokya KampalaDocumento1 paginaWednesday, March 4, 2015: Tangerine (U) LTD P.O Box 37136 Plot 26, Kanjokya Street, Kamwokya KampalaFred OchiengNessuna valutazione finora
- Research Methods Ad (S.P.S.S)Documento1 paginaResearch Methods Ad (S.P.S.S)Fred OchiengNessuna valutazione finora
- Uganda Management Institute: From Personnel Management To HRM: Key Issues and Challenges Síle FlemingDocumento7 pagineUganda Management Institute: From Personnel Management To HRM: Key Issues and Challenges Síle FlemingFred OchiengNessuna valutazione finora
- Place. I Have Kindly Selected You To Assist Me by Answering The Questions ProvidedDocumento2 paginePlace. I Have Kindly Selected You To Assist Me by Answering The Questions ProvidedFred OchiengNessuna valutazione finora
- Cash ManagementDocumento51 pagineCash ManagementFred OchiengNessuna valutazione finora
- Importance of Human Resource ManagementDocumento2 pagineImportance of Human Resource ManagementFred OchiengNessuna valutazione finora
- What Is Media Violence?Documento2 pagineWhat Is Media Violence?Fred OchiengNessuna valutazione finora
- Headed Paper Florance PDFDocumento1 paginaHeaded Paper Florance PDFFred OchiengNessuna valutazione finora
- Buz S-W ApplicationDocumento6 pagineBuz S-W ApplicationFred OchiengNessuna valutazione finora
- Institute of Advanced Leadership: End of Semester ExaminationsDocumento7 pagineInstitute of Advanced Leadership: End of Semester ExaminationsFred OchiengNessuna valutazione finora
- Gender Studies Subjective - 1Documento1 paginaGender Studies Subjective - 1A JawadNessuna valutazione finora
- Four Days Late, But Still On TimeDocumento5 pagineFour Days Late, But Still On TimeK Songput100% (1)
- The Good LifeDocumento34 pagineThe Good LifeJessa Vel FloresNessuna valutazione finora
- 3 2947Documento32 pagine3 2947Lei ZhouNessuna valutazione finora
- QuranDocumento4 pagineQuranmohiNessuna valutazione finora
- Formative Assessment 2Documento16 pagineFormative Assessment 2Mohammad Nurul AzimNessuna valutazione finora
- جودة الخدمة ودورها في الاداء المتميزDocumento28 pagineجودة الخدمة ودورها في الاداء المتميزqoseNessuna valutazione finora
- Lesson Plan ReadingDocumento7 pagineLesson Plan ReadingNiar SamandiNessuna valutazione finora
- Flow Induced Vibration Choke ValvesDocumento8 pagineFlow Induced Vibration Choke Valvesharmeeksingh01Nessuna valutazione finora
- Fayol Stands The Test of TimeFayol Stands The Test of TimeDocumento17 pagineFayol Stands The Test of TimeFayol Stands The Test of Timecarlos_xccunhaNessuna valutazione finora
- ПерекладознавствоDocumento128 pagineПерекладознавствоNataliia DerzhyloNessuna valutazione finora
- Untitled 5Documento5 pagineUntitled 5Boshra BoshraNessuna valutazione finora
- Teachers Profile MNHSDocumento28 pagineTeachers Profile MNHSMICHELLE CANONIGONessuna valutazione finora
- Lecture On ProphethoodDocumento31 pagineLecture On ProphethoodDanish Uttra100% (1)
- Cowan A., Women, Gossip and Marriage in VeniceDocumento23 pagineCowan A., Women, Gossip and Marriage in Veniceneven81Nessuna valutazione finora
- Syntax4 PDFDocumento5 pagineSyntax4 PDFririnsepNessuna valutazione finora
- RVR JC College of Engineering Question Bank 1Documento2 pagineRVR JC College of Engineering Question Bank 1MOHAMMED AFZALNessuna valutazione finora
- Cambridge Books OnlineDocumento23 pagineCambridge Books OnlineЊегош ВујадиновићNessuna valutazione finora
- Women's Development Cell: ObjectivesDocumento2 pagineWomen's Development Cell: ObjectivesSoviljot SinghNessuna valutazione finora
- Learning Outcomes - Values and Attitudes: Vandeveer, Menefee, Sinclair 1Documento22 pagineLearning Outcomes - Values and Attitudes: Vandeveer, Menefee, Sinclair 1Nurhikmah RnNessuna valutazione finora
- Correlations - Sagun & Nirgun UpasanaDocumento9 pagineCorrelations - Sagun & Nirgun UpasanaAnupam ShilNessuna valutazione finora
- Speakers & Workshop Leaders: Catherine DayDocumento4 pagineSpeakers & Workshop Leaders: Catherine DaylilikaliaNessuna valutazione finora