Potrebbero piacerti anche
- 1326370398-HS6-54 Use of MEWP Risk AssessmentDocumento2 pagine1326370398-HS6-54 Use of MEWP Risk AssessmentJohn David Hoyos Marmolejo83% (6)
- Aviation Week & Space Technology - September 22, 2014 USADocumento60 pagineAviation Week & Space Technology - September 22, 2014 USAJohn David Hoyos MarmolejoNessuna valutazione finora
- National Geographic Traveller UK - July August 2014Documento180 pagineNational Geographic Traveller UK - July August 2014John David Hoyos Marmolejo100% (1)
- Polyglot BookDocumento216 paginePolyglot BookSasa MilosevicNessuna valutazione finora
- 2pac-LyricsDocumento484 pagine2pac-LyricsJohn David Hoyos Marmolejo67% (3)
- The Yellow House: A Memoir (2019 National Book Award Winner)Da EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Valutazione: 4 su 5 stelle4/5 (98)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDa EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceValutazione: 4 su 5 stelle4/5 (895)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDa EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeValutazione: 4 su 5 stelle4/5 (5794)
- The Little Book of Hygge: Danish Secrets to Happy LivingDa EverandThe Little Book of Hygge: Danish Secrets to Happy LivingValutazione: 3.5 su 5 stelle3.5/5 (399)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDa EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaValutazione: 4.5 su 5 stelle4.5/5 (266)
- Shoe Dog: A Memoir by the Creator of NikeDa EverandShoe Dog: A Memoir by the Creator of NikeValutazione: 4.5 su 5 stelle4.5/5 (537)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDa EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureValutazione: 4.5 su 5 stelle4.5/5 (474)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDa EverandNever Split the Difference: Negotiating As If Your Life Depended On ItValutazione: 4.5 su 5 stelle4.5/5 (838)
- Grit: The Power of Passion and PerseveranceDa EverandGrit: The Power of Passion and PerseveranceValutazione: 4 su 5 stelle4/5 (588)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDa EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryValutazione: 3.5 su 5 stelle3.5/5 (231)
- The Emperor of All Maladies: A Biography of CancerDa EverandThe Emperor of All Maladies: A Biography of CancerValutazione: 4.5 su 5 stelle4.5/5 (271)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDa EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyValutazione: 3.5 su 5 stelle3.5/5 (2259)
- On Fire: The (Burning) Case for a Green New DealDa EverandOn Fire: The (Burning) Case for a Green New DealValutazione: 4 su 5 stelle4/5 (73)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDa EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersValutazione: 4.5 su 5 stelle4.5/5 (344)
- Team of Rivals: The Political Genius of Abraham LincolnDa EverandTeam of Rivals: The Political Genius of Abraham LincolnValutazione: 4.5 su 5 stelle4.5/5 (234)
- The Unwinding: An Inner History of the New AmericaDa EverandThe Unwinding: An Inner History of the New AmericaValutazione: 4 su 5 stelle4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDa EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreValutazione: 4 su 5 stelle4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Da EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Valutazione: 4.5 su 5 stelle4.5/5 (121)
- Her Body and Other Parties: StoriesDa EverandHer Body and Other Parties: StoriesValutazione: 4 su 5 stelle4/5 (821)
- Baan ERP HistoryDocumento18 pagineBaan ERP HistoryBalaji_SAPNessuna valutazione finora
- AMAZONE ZA-F 604 Uputstvo Za Koristenje I OdrzavanjeDocumento32 pagineAMAZONE ZA-F 604 Uputstvo Za Koristenje I OdrzavanjeIvonaLepir100% (1)
- Profile Measurement Full ReportDocumento16 pagineProfile Measurement Full ReportAman RedhaNessuna valutazione finora
- (ENG) C&T Catalog Hydrelio® Technology 2021Documento24 pagine(ENG) C&T Catalog Hydrelio® Technology 2021ReenNessuna valutazione finora
- Electrical Power Systems Wadhwa 15Documento1 paginaElectrical Power Systems Wadhwa 15ragupaNessuna valutazione finora
- Technology Architecture For NginX, postgreSQL, postgRESTDocumento5 pagineTechnology Architecture For NginX, postgreSQL, postgRESTkarelvdwalt9366Nessuna valutazione finora
- A140Documento104 pagineA140hungchagia1Nessuna valutazione finora
- Electric Fan RepairDocumento12 pagineElectric Fan RepairYsabelle Tagaruma33% (3)
- Q4X Stainless Steel Laser Sensor: Instruction ManualDocumento42 pagineQ4X Stainless Steel Laser Sensor: Instruction Manualtigres1Nessuna valutazione finora
- Serie: Guía RápidaDocumento12 pagineSerie: Guía RápidalumapueNessuna valutazione finora
- Hydro DepartmentDocumento5 pagineHydro DepartmentaminkhalilNessuna valutazione finora
- TMH 2019 2020 Mail PasswordDocumento7 pagineTMH 2019 2020 Mail PasswordAni AbrahamyanNessuna valutazione finora
- DIS2116 ManualDocumento88 pagineDIS2116 ManualHưng Tự Động HoáNessuna valutazione finora
- Acetic 2520acid 2520 Energy 2520balanceDocumento6 pagineAcetic 2520acid 2520 Energy 2520balancembeni0751Nessuna valutazione finora
- Performance of Gesture Controlled DroneDocumento11 paginePerformance of Gesture Controlled DroneKrishna SivaNessuna valutazione finora
- Sample Problem #8Documento8 pagineSample Problem #8DozdiNessuna valutazione finora
- Pawan Kumar Dubey: ProfileDocumento4 paginePawan Kumar Dubey: Profilepawandubey9Nessuna valutazione finora
- Pioneer pdp-424mv Pdp-42mve1 (ET)Documento122 paginePioneer pdp-424mv Pdp-42mve1 (ET)Manuel PeraltaNessuna valutazione finora
- Calculating The Pathlength of Liquid Cells by FTIR PIKEDocumento1 paginaCalculating The Pathlength of Liquid Cells by FTIR PIKEMoises RomeroNessuna valutazione finora
- Fastcap 22 630v PDFDocumento1 paginaFastcap 22 630v PDFDarrenNessuna valutazione finora
- Lecture 1 - Auditing & Internal ControlDocumento63 pagineLecture 1 - Auditing & Internal ControlLei CasipleNessuna valutazione finora
- Mac Puarsa MRL SCHEMATICDocumento28 pagineMac Puarsa MRL SCHEMATICthanggimme.phanNessuna valutazione finora
- Manual New AswanDocumento18 pagineManual New AswanmohamedmosallamNessuna valutazione finora
- Mals-11, Family Readiness Newsletter, July 2011, The Devilfish TidesDocumento9 pagineMals-11, Family Readiness Newsletter, July 2011, The Devilfish TidesDevilfish FRONessuna valutazione finora
- QCDD-Duyar-QR SprinklersDocumento2 pagineQCDD-Duyar-QR SprinklersBaraa' KahlawiNessuna valutazione finora
- Surface Finish StandardDocumento3 pagineSurface Finish StandardvinodmysoreNessuna valutazione finora
- Akta Satelit On Astra 4A at 4Documento6 pagineAkta Satelit On Astra 4A at 4Amirul AsyrafNessuna valutazione finora
- Sao Paulo Brand BookDocumento104 pagineSao Paulo Brand Booknicoagudelo82Nessuna valutazione finora
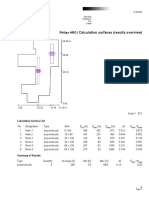
- Calculation Surfaces (Results Overview) : Philips HRODocumento4 pagineCalculation Surfaces (Results Overview) : Philips HROsanaNessuna valutazione finora