Potrebbero piacerti anche
- Differential Evolution: Fundamentals and ApplicationsDa EverandDifferential Evolution: Fundamentals and ApplicationsNessuna valutazione finora
- UntitledDocumento12 pagineUntitledapi-262707463Nessuna valutazione finora
- 2018FA MAT152 Test2AKEY 1Documento6 pagine2018FA MAT152 Test2AKEY 18987a&mNessuna valutazione finora
- Conditional Probability and TableDocumento11 pagineConditional Probability and TableFatah UmasugiNessuna valutazione finora
- Lesson 2.3: Measures of DispersionDocumento13 pagineLesson 2.3: Measures of DispersionChesca AlonNessuna valutazione finora
- MTH302 FAQsDocumento18 pagineMTH302 FAQsRamesh KumarNessuna valutazione finora
- UNIT3Documento71 pagineUNIT3TomNessuna valutazione finora
- STAT 250 Practice Problem SolutionsDocumento5 pagineSTAT 250 Practice Problem SolutionsKiet Phan100% (1)
- Classification Error: Training Errors Generalization ErrorsDocumento39 pagineClassification Error: Training Errors Generalization ErrorsOscar WongNessuna valutazione finora
- A Very Basic Introduction To Random Forests Using R - Oxford Protein Informatics GroupDocumento7 pagineA Very Basic Introduction To Random Forests Using R - Oxford Protein Informatics Groupcäsar SantanaNessuna valutazione finora
- Measurements Exam Guide & Data AnalysisDocumento7 pagineMeasurements Exam Guide & Data AnalysisrthincheyNessuna valutazione finora
- Assignment Name - Machine Learning Basics Problem StatementDocumento4 pagineAssignment Name - Machine Learning Basics Problem StatementMubassir SurveNessuna valutazione finora
- Confidence Intervals-summer22-Lecture11Documento23 pagineConfidence Intervals-summer22-Lecture11Abu Bakar AbbasiNessuna valutazione finora
- Decision Tree Explained in 40 CharactersDocumento16 pagineDecision Tree Explained in 40 Charactersreshma acharyaNessuna valutazione finora
- Practicing Statistics Guided Investigations For The Second Course 1st Edition Kuiper Solutions ManualDocumento25 paginePracticing Statistics Guided Investigations For The Second Course 1st Edition Kuiper Solutions Manualbarrydixonydazewpbxn100% (14)
- EpidemiologyDocumento7 pagineEpidemiologyDoggo OggodNessuna valutazione finora
- STA 100: Midterm II Practice QuestionsDocumento9 pagineSTA 100: Midterm II Practice QuestionsxinnianhaoNessuna valutazione finora
- Assignment06 1Documento4 pagineAssignment06 1Naresh SuwalNessuna valutazione finora
- Presentation MLDocumento33 paginePresentation MLfull entertainmentNessuna valutazione finora
- Pam3100 Ps5 Revised Spring 2018Documento5 paginePam3100 Ps5 Revised Spring 2018Marta Zavaleta DelgadoNessuna valutazione finora
- Nonparametric Testing Using The Chi-Square Distribution: Reading TipsDocumento4 pagineNonparametric Testing Using The Chi-Square Distribution: Reading TipsEncik SmkbaNessuna valutazione finora
- Section 7.2 Sample Proportions: Chapter 7: Sampling DistributionsDocumento22 pagineSection 7.2 Sample Proportions: Chapter 7: Sampling DistributionsGrace LiNessuna valutazione finora
- Lab06 Confidence IntervalsDocumento4 pagineLab06 Confidence IntervalskarpoviguessNessuna valutazione finora
- Exercises Sheet 1 Types of Statistical Data and Display of DataDocumento10 pagineExercises Sheet 1 Types of Statistical Data and Display of DataJaime-Nemilyn Ati-id FadcharNessuna valutazione finora
- One-Sample Test of Proportions: Z 1.733 One-Tailed Probability 0.042 Two-Tailed Probability 0.084Documento4 pagineOne-Sample Test of Proportions: Z 1.733 One-Tailed Probability 0.042 Two-Tailed Probability 0.084Chris TanginNessuna valutazione finora
- Cuckoo Egg Size VariationDocumento18 pagineCuckoo Egg Size Variationtian zhaoNessuna valutazione finora
- UntitledDocumento3 pagineUntitledapi-262707463Nessuna valutazione finora
- Corn Genetics - Kelompok 4Documento7 pagineCorn Genetics - Kelompok 4Delia NurusyifaNessuna valutazione finora
- HW 2 Write-UpDocumento4 pagineHW 2 Write-UpJennifer Alyce RiosNessuna valutazione finora
- Standard Deviation and Standard Error WorksheetDocumento7 pagineStandard Deviation and Standard Error WorksheetTrisha Bechard100% (1)
- L24 Quiz Group Meeting Biostatistics PDFDocumento21 pagineL24 Quiz Group Meeting Biostatistics PDFÁngeles La Fuente RodriguezNessuna valutazione finora
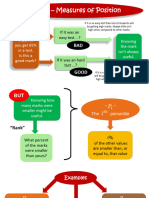
- Measures of Relative PositionDocumento18 pagineMeasures of Relative PositionEdesa Jarabejo100% (1)
- Sample VariationDocumento8 pagineSample Variationpartho143Nessuna valutazione finora
- The Test Use This Test WhenDocumento23 pagineThe Test Use This Test WhenHellen Jeans TutorNessuna valutazione finora
- Question Bank Research Methodology and Biostatistics BPT 402 1. Calculate Appropriate Measure of Skewness From The Following DataDocumento17 pagineQuestion Bank Research Methodology and Biostatistics BPT 402 1. Calculate Appropriate Measure of Skewness From The Following DataAtul DahiyaNessuna valutazione finora
- Modify-Use Bio. IB Book IB Biology Topic 1: Statistical AnalysisDocumento25 pagineModify-Use Bio. IB Book IB Biology Topic 1: Statistical AnalysissarfarazNessuna valutazione finora
- An Introduction To Classification and Regression Trees With PROC HPSPLITDocumento13 pagineAn Introduction To Classification and Regression Trees With PROC HPSPLITMachicheNessuna valutazione finora
- Retaltional DBDocumento25 pagineRetaltional DBNadim MominNessuna valutazione finora
- Sociology 592 - Research Statistics I Exam 1 September 28, 2001Documento3 pagineSociology 592 - Research Statistics I Exam 1 September 28, 2001stephen562001Nessuna valutazione finora
- Naive Bayes Classifier: Coin Toss and Fair Dice ExampleDocumento16 pagineNaive Bayes Classifier: Coin Toss and Fair Dice ExampleRupali PatilNessuna valutazione finora
- Unit-3 ML P (1) PPTs by DR KSRDocumento21 pagineUnit-3 ML P (1) PPTs by DR KSRGanesh DegalaNessuna valutazione finora
- ExamDocumento4 pagineExamredouane0% (4)
- Seminar 5 OutlineDocumento4 pagineSeminar 5 Outlinejeremydb77Nessuna valutazione finora
- Inf1343 2011W Assignment 1Documento4 pagineInf1343 2011W Assignment 1Ashraf Sayed AbdouNessuna valutazione finora
- Classification ProblemsDocumento53 pagineClassification ProblemsNaveen JaishankarNessuna valutazione finora
- Genetic AlgorithmDocumento40 pagineGenetic Algorithmpulkit guptaNessuna valutazione finora
- Answer Key To Sample AP-ExamDocumento7 pagineAnswer Key To Sample AP-ExamldlewisNessuna valutazione finora
- Sec 2.8 - 2021Documento20 pagineSec 2.8 - 2021sthembisoandile059Nessuna valutazione finora
- Appendix 7A: Details About Sources Used For Entries in Table 7.1Documento30 pagineAppendix 7A: Details About Sources Used For Entries in Table 7.1Henrique FreitasNessuna valutazione finora
- Midterm BioStat 2023Documento11 pagineMidterm BioStat 2023Young YoungNessuna valutazione finora
- FinalDocumento3 pagineFinalishmal khanNessuna valutazione finora
- Sta301 Short NotesDocumento6 pagineSta301 Short NotesAyesha MughalNessuna valutazione finora
- ETC1000 Exam Sem1 2017 PDFDocumento11 pagineETC1000 Exam Sem1 2017 PDFHelen ChenNessuna valutazione finora
- Measures of Central Tendency: Mode, Median, and MeanDocumento8 pagineMeasures of Central Tendency: Mode, Median, and MeanKikiez PathanasriwongNessuna valutazione finora
- 10 11.1 Day 3 Assignment 11Documento3 pagine10 11.1 Day 3 Assignment 11guyNessuna valutazione finora
- MATH 221 Final Exam Statistics For DecisionDocumento8 pagineMATH 221 Final Exam Statistics For DecisiongeorgettashipleyNessuna valutazione finora
- Sampling and Sampling DistributionsDocumento5 pagineSampling and Sampling DistributionsImen KsouriNessuna valutazione finora
- Week 11: Review Before New: After Watching The Video, Please Answer The Following QuestionsDocumento8 pagineWeek 11: Review Before New: After Watching The Video, Please Answer The Following QuestionsDivyaNessuna valutazione finora
- ACTM-Statistics Regional Exam 2017 Multiple-Choice QuestionsDocumento15 pagineACTM-Statistics Regional Exam 2017 Multiple-Choice QuestionsJamesNessuna valutazione finora
- Installing the BatchInfo CSV File for SQL Server 2012 BIDocumento1 paginaInstalling the BatchInfo CSV File for SQL Server 2012 BIArpit GulatiNessuna valutazione finora
- Regression in R SoftwareDocumento24 pagineRegression in R SoftwareJoão Heitor De AvilaNessuna valutazione finora
- Ch4 AlgebraDocumento607 pagineCh4 AlgebrajamesyuNessuna valutazione finora
- Beer and PretzelsDocumento4 pagineBeer and PretzelsArpit GulatiNessuna valutazione finora
- IDS 507 - Fall 2016 - Case Study 1 AssignmentDocumento1 paginaIDS 507 - Fall 2016 - Case Study 1 AssignmentArpit GulatiNessuna valutazione finora
- BankofAmericaCorporation 10K 20090227Documento1.096 pagineBankofAmericaCorporation 10K 20090227Arpit GulatiNessuna valutazione finora
- 61 90 PDFDocumento20 pagine61 90 PDFArpit GulatiNessuna valutazione finora
- Book 1Documento1 paginaBook 1Arpit GulatiNessuna valutazione finora
- 2011 Er Relational Exercise Pharma PDFDocumento4 pagine2011 Er Relational Exercise Pharma PDFArpit GulatiNessuna valutazione finora
- Beer and PretzelsDocumento4 pagineBeer and PretzelsArpit GulatiNessuna valutazione finora
- Barnes & Noble AnalysisDocumento28 pagineBarnes & Noble Analysislethuy_tram391088% (8)
- Barnes & Noble vs Amazon Online Book BattleDocumento3 pagineBarnes & Noble vs Amazon Online Book BattleAarti AroraNessuna valutazione finora
- Modeling Data in The OrganizationDocumento45 pagineModeling Data in The OrganizationArpit GulatiNessuna valutazione finora
- Chap 08Documento37 pagineChap 08Arpit GulatiNessuna valutazione finora
- Ch1 Dbms MDMDocumento30 pagineCh1 Dbms MDMGerald Alminar-usltNessuna valutazione finora
- The Database Development ProcessDocumento37 pagineThe Database Development ProcessLidya IndrianiNessuna valutazione finora
- American Well targets insurers and providers with online care expansionDocumento6 pagineAmerican Well targets insurers and providers with online care expansionPreetam Joga75% (4)
- 840N Robinson SP08Documento13 pagine840N Robinson SP08Arpit GulatiNessuna valutazione finora
- American Well: The Doctor Will E-See You Now - CaseDocumento6 pagineAmerican Well: The Doctor Will E-See You Now - Casebinzidd007100% (4)
- Problems 2.7.4-2.7.5Documento4 pagineProblems 2.7.4-2.7.5Arpit GulatiNessuna valutazione finora
- Business Data Mining Homework 3 Due September 23Documento3 pagineBusiness Data Mining Homework 3 Due September 23Arpit GulatiNessuna valutazione finora
- Problem 2.4.5Documento1 paginaProblem 2.4.5Arpit GulatiNessuna valutazione finora
- 27Documento2 pagine27Arpit GulatiNessuna valutazione finora
- DtreeoutDocumento1 paginaDtreeoutArpit GulatiNessuna valutazione finora
- Problem 1.4.2Documento1 paginaProblem 1.4.2Arpit GulatiNessuna valutazione finora
- CXCXDocumento3 pagineCXCXArpit GulatiNessuna valutazione finora
- Analysis Ofad (RESPONSE) #2Documento1 paginaAnalysis Ofad (RESPONSE) #2Arpit GulatiNessuna valutazione finora
- Your Order Has Been Successfully PlacedDocumento1 paginaYour Order Has Been Successfully PlacedArpit GulatiNessuna valutazione finora
- Work Energy & Power (N)Documento1 paginaWork Energy & Power (N)Arpit GulatiNessuna valutazione finora
- Introduction To Econometrics, 5 Edition: Chapter HeadingDocumento69 pagineIntroduction To Econometrics, 5 Edition: Chapter HeadingUsama RajaNessuna valutazione finora
- Lecture #9: Distributed Deadlock DetectionDocumento17 pagineLecture #9: Distributed Deadlock DetectionANUPAM SURNessuna valutazione finora
- Opt ppt1Documento8 pagineOpt ppt1pramodkumar808751528270Nessuna valutazione finora
- Weather Trends Sales PredictorDocumento6 pagineWeather Trends Sales PredictorWananda Muhammad RifkiNessuna valutazione finora
- Trinanjan Saha: Data ScientistDocumento1 paginaTrinanjan Saha: Data ScientistAvishek GhoshNessuna valutazione finora
- BTonly CH 12345Documento267 pagineBTonly CH 12345jo_hannah_gutierrez43% (7)
- Error Control Coding PDFDocumento2 pagineError Control Coding PDFTiffanyNessuna valutazione finora
- Chapter 18Documento9 pagineChapter 18KANIKA GORAYANessuna valutazione finora
- FP425Documento9 pagineFP425DARWIN PATIÑO PÉREZNessuna valutazione finora
- Visible Surface DetectDocumento27 pagineVisible Surface Detectnasrin1111111Nessuna valutazione finora
- Hands-On Graph Neural Networks Using Python Practical Techniques and Architectures For Building Powerful Graph and Deep Learning Apps With PyTorch PDFDocumento354 pagineHands-On Graph Neural Networks Using Python Practical Techniques and Architectures For Building Powerful Graph and Deep Learning Apps With PyTorch PDFGéza Nagy100% (5)
- GTU Advanced Digital Signal ProcessingDocumento4 pagineGTU Advanced Digital Signal ProcessingDarshan BhattNessuna valutazione finora
- Data Science, Classification, and Related Methods PDFDocumento786 pagineData Science, Classification, and Related Methods PDFTumaini SankofaNessuna valutazione finora
- f4 ch9 Rational FunctionDocumento10 paginef4 ch9 Rational Functionapi-517118868Nessuna valutazione finora
- Network Diagram - CMPMDocumento18 pagineNetwork Diagram - CMPMLara RiveraNessuna valutazione finora
- Hartree-Fock on a superconducting qubit quantum computerDocumento30 pagineHartree-Fock on a superconducting qubit quantum computerLETSOGILENessuna valutazione finora
- Discrete Optimization B&B MethodDocumento33 pagineDiscrete Optimization B&B Methodkarly yuNessuna valutazione finora
- Comparative Study of Various Sentiment Classification Techniques in Twitter 1Documento9 pagineComparative Study of Various Sentiment Classification Techniques in Twitter 1International Journal of Innovative Science and Research TechnologyNessuna valutazione finora
- Or ObjectivesDocumento19 pagineOr ObjectivesKarthik SaraaNessuna valutazione finora
- Dense Optical Flow Expansion Based On Polynomial Basis ApproximationDocumento12 pagineDense Optical Flow Expansion Based On Polynomial Basis Approximationpi194043Nessuna valutazione finora
- HW10-SolutionsDocumento6 pagineHW10-Solutionsotieno.paul20Nessuna valutazione finora
- 2Documento2 pagine2MiltonNessuna valutazione finora
- Computational Thinking, Problem-Solving and Programming:: IB Computer ScienceDocumento8 pagineComputational Thinking, Problem-Solving and Programming:: IB Computer ScienceHanzaada ZhyldyzbekovaNessuna valutazione finora
- Discrete Mathematics SyllabusDocumento2 pagineDiscrete Mathematics SyllabusMiliyon TilahunNessuna valutazione finora
- Discrete MathsDocumento6 pagineDiscrete MathssanjayghoshNessuna valutazione finora
- Chapter 5 Project Time Cost Trade OffDocumento18 pagineChapter 5 Project Time Cost Trade OffWalid MarhabaNessuna valutazione finora
- Numerical DifferentiationDocumento3 pagineNumerical DifferentiationOwen MuloNessuna valutazione finora
- Hydroinformatics - Possibilities For PHDDocumento3 pagineHydroinformatics - Possibilities For PHDsolomatineNessuna valutazione finora
- LG 5 and 6 Activity Worksheet 2nd QuarterDocumento1 paginaLG 5 and 6 Activity Worksheet 2nd QuarterSherre Nicole CuentaNessuna valutazione finora
- Lecture 2Documento12 pagineLecture 2RMDNessuna valutazione finora