Potrebbero piacerti anche
- A Formula Based Approach To Arithmetic CodingDocumento8 pagineA Formula Based Approach To Arithmetic CodingperhackerNessuna valutazione finora
- L #6: L C C S L G: Sfsu - E 301 - E L AB Ogic Ircuit Haracteristics and Imple Ogic AtesDocumento11 pagineL #6: L C C S L G: Sfsu - E 301 - E L AB Ogic Ircuit Haracteristics and Imple Ogic AtesRudra MishraNessuna valutazione finora
- Low-Pass Filter Control Memory HeadphoneDocumento6 pagineLow-Pass Filter Control Memory HeadphonematanveerNessuna valutazione finora
- Introduction To Pspice: Creating A Circuit Description FileDocumento2 pagineIntroduction To Pspice: Creating A Circuit Description FileskrtamilNessuna valutazione finora
- SkipDocumento22 pagineSkipAnonymous 0MQ3zRNessuna valutazione finora
- Compression: Author: Paul Penfield, Jr. 2004 Massachusetts Institute of Technology Url: Start: Back: NextDocumento8 pagineCompression: Author: Paul Penfield, Jr. 2004 Massachusetts Institute of Technology Url: Start: Back: Next沈国威Nessuna valutazione finora
- Compression IIDocumento51 pagineCompression IIJagadeesh NaniNessuna valutazione finora
- 6.02 Practice Problems - Routing PDFDocumento10 pagine6.02 Practice Problems - Routing PDFalanNessuna valutazione finora
- Compression: Author: Paul Penfield, Jr. Url: TocDocumento5 pagineCompression: Author: Paul Penfield, Jr. Url: TocAntónio LimaNessuna valutazione finora
- Low-Density Parity-Check Codes Over Gaussian Channels With ErasuresDocumento9 pagineLow-Density Parity-Check Codes Over Gaussian Channels With ErasuresBoazShuvalNessuna valutazione finora
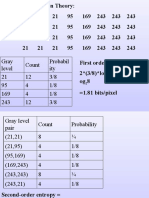
- Gray Level Count Probabil Ity 21 12 3/8 95 4 1/8 169 4 1/8 243 12 3/8Documento51 pagineGray Level Count Probabil Ity 21 12 3/8 95 4 1/8 169 4 1/8 243 12 3/8kamnakhannaNessuna valutazione finora
- Low-Density Parity-Check CodesDocumento6 pagineLow-Density Parity-Check CodesAhmed TorkiNessuna valutazione finora
- Concatenated Turbo/LDPC Codes For Deep Space Communications: Performance and ImplementationDocumento6 pagineConcatenated Turbo/LDPC Codes For Deep Space Communications: Performance and ImplementationmkawserNessuna valutazione finora
- 3.multimedia Compression AlgorithmsDocumento23 pagine3.multimedia Compression Algorithmsaishu sillNessuna valutazione finora
- SV5: Error Correcting Codes: Fachpraktikum SignalverarbeitungDocumento7 pagineSV5: Error Correcting Codes: Fachpraktikum SignalverarbeitungBshAekNessuna valutazione finora
- Cryptography - Exercises: 1 Historic CiphersDocumento7 pagineCryptography - Exercises: 1 Historic CiphersBeni RodriguezNessuna valutazione finora
- EEE316 Experiment 1Documento12 pagineEEE316 Experiment 1axeansNessuna valutazione finora
- On The K-Ary Hypercube: Theoretical Computer Science 140 (1995) 333-339Documento7 pagineOn The K-Ary Hypercube: Theoretical Computer Science 140 (1995) 333-339Khánh DuyNessuna valutazione finora
- Convolution Codes: 1.0 PrologueDocumento26 pagineConvolution Codes: 1.0 PrologueGourgobinda Satyabrata AcharyaNessuna valutazione finora
- Octave1 StartDocumento5 pagineOctave1 Startsorin0920047329Nessuna valutazione finora
- Lab #3 Digital Images: A/D and D/A: Shafaq Tauqir 198292Documento12 pagineLab #3 Digital Images: A/D and D/A: Shafaq Tauqir 198292Rabail InKrediblNessuna valutazione finora
- CMPT 371: Midterm 2: 1 Short Answer QuestionsDocumento4 pagineCMPT 371: Midterm 2: 1 Short Answer QuestionsNeil HolmesNessuna valutazione finora
- Image CompressionDocumento50 pagineImage CompressionVipin SinghNessuna valutazione finora
- Assignment 2: Communication TheoryDocumento2 pagineAssignment 2: Communication TheoryJahnavi RameshNessuna valutazione finora
- Wireless Access Systems Exercise Sheet 2: Coded OFDM Modem: Oals of The XerciseDocumento6 pagineWireless Access Systems Exercise Sheet 2: Coded OFDM Modem: Oals of The XerciseRashed IslamNessuna valutazione finora
- Solution Gates 2 SamplesDocumento9 pagineSolution Gates 2 SamplesluqmansulymanNessuna valutazione finora
- Digitally Removing A DC Offset: DSP Without Mathematics: WP279 (v1.0) July 18, 2008Documento16 pagineDigitally Removing A DC Offset: DSP Without Mathematics: WP279 (v1.0) July 18, 2008santanu_sinha87Nessuna valutazione finora
- Unit20 HuffmanCodingDocumento22 pagineUnit20 HuffmanCodingVijaya AzimuddinNessuna valutazione finora
- Assignment 3Documento3 pagineAssignment 3Emmanuel OpolotNessuna valutazione finora
- 4 LZWDocumento7 pagine4 LZWmayur morvekarNessuna valutazione finora
- Sequential Decoding by Stack AlgorithmDocumento9 pagineSequential Decoding by Stack AlgorithmRam Chandram100% (1)
- Lecture 12: More On Registers, Multiplexers, Decoders, Comparators and Wot-NotsDocumento5 pagineLecture 12: More On Registers, Multiplexers, Decoders, Comparators and Wot-NotsTaqi ShahNessuna valutazione finora
- Cmos AnswersDocumento8 pagineCmos AnswersOnu SamNessuna valutazione finora
- Digital Principles and System DesignDocumento76 pagineDigital Principles and System Designraja rNessuna valutazione finora
- A SPICE (PSPICE) Tutorial: Appendix DDocumento16 pagineA SPICE (PSPICE) Tutorial: Appendix DSHOBHIT SHARMANessuna valutazione finora
- 2094expt 9 - PN Code - NewDocumento3 pagine2094expt 9 - PN Code - NewXavierNessuna valutazione finora
- Communication Basics: Principles and DogmasDocumento26 pagineCommunication Basics: Principles and DogmasArun JayaramanNessuna valutazione finora
- 1 Introduction To Linear Block CodesDocumento13 pagine1 Introduction To Linear Block CodesRini KamilNessuna valutazione finora
- Lemp El Ziv CompressionDocumento6 pagineLemp El Ziv CompressionssfofoNessuna valutazione finora
- Ahl Swede 00Documento13 pagineAhl Swede 00Monireh VaNessuna valutazione finora
- Algorithms and Data Structures Sample 3Documento9 pagineAlgorithms and Data Structures Sample 3Hebrew JohnsonNessuna valutazione finora
- Mob Net 2012 Exam SolutionDocumento16 pagineMob Net 2012 Exam SolutionMohammad IrsheadNessuna valutazione finora
- Data Communication FundamentalsDocumento1.399 pagineData Communication Fundamentalsnatasnji13Nessuna valutazione finora
- High Throughput, Parallel, Scalable LDPC Encoder/Decoder Architecture For Ofdm SystemsDocumento4 pagineHigh Throughput, Parallel, Scalable LDPC Encoder/Decoder Architecture For Ofdm Systemssandeepkarnati11Nessuna valutazione finora
- LZW Data CompressionDocumento5 pagineLZW Data CompressionAJER JOURNALNessuna valutazione finora
- ECE 368 A Tour by Example of Non-Trivial Circuit Design and VHDL DescriptionDocumento23 pagineECE 368 A Tour by Example of Non-Trivial Circuit Design and VHDL DescriptionAnand ChaudharyNessuna valutazione finora
- Convolutional Coding and Viterbi DecodingDocumento30 pagineConvolutional Coding and Viterbi DecodingEmNessuna valutazione finora
- A New Packet Loss Model of The IEEE 802.11g Wireless Network For Multimedia CommunicationsDocumento6 pagineA New Packet Loss Model of The IEEE 802.11g Wireless Network For Multimedia CommunicationsJuan Felipe Corso AriasNessuna valutazione finora
- Error Control Coding3Documento24 pagineError Control Coding3DuongMinhSOnNessuna valutazione finora
- COA Lab 1Documento11 pagineCOA Lab 1mudasirhussainf22Nessuna valutazione finora
- Chapter 07 - Lossless Compression AlgorithmsDocumento50 pagineChapter 07 - Lossless Compression Algorithmsa_setiajiNessuna valutazione finora
- Lab 2 Gnuradio ImplementationDocumento8 pagineLab 2 Gnuradio ImplementationSreeraj RajendranNessuna valutazione finora
- Elliptic Public Key Cryptosystem Using DHK and Partial Reduction Modulo TechniquesDocumento8 pagineElliptic Public Key Cryptosystem Using DHK and Partial Reduction Modulo TechniqueskesavantNessuna valutazione finora
- A Low-Power High-Radix Serial-Parallel MultiplierDocumento4 pagineA Low-Power High-Radix Serial-Parallel Multiplierspkrishna4u7369Nessuna valutazione finora
- PH435 2022 Group7Documento10 paginePH435 2022 Group7Jone jackNessuna valutazione finora
- Steber An LMS Impedance BridgeDocumento7 pagineSteber An LMS Impedance BridgebigpriapNessuna valutazione finora
- Error-Correction on Non-Standard Communication ChannelsDa EverandError-Correction on Non-Standard Communication ChannelsNessuna valutazione finora
- CCNA Interview Questions You'll Most Likely Be AskedDa EverandCCNA Interview Questions You'll Most Likely Be AskedNessuna valutazione finora
- IMRDocumento786 pagineIMRTanvi SharmaNessuna valutazione finora
- Information Required For Mentoring The StudentsDocumento1 paginaInformation Required For Mentoring The StudentsTanvi SharmaNessuna valutazione finora
- Raghunath Monthly Momentum StrategyDocumento10 pagineRaghunath Monthly Momentum StrategyTanvi SharmaNessuna valutazione finora
- Project Report Submission GuidelinesDocumento7 pagineProject Report Submission GuidelinesTanvi SharmaNessuna valutazione finora
- Undertaking From StudentDocumento1 paginaUndertaking From StudentTanvi SharmaNessuna valutazione finora
- English SolutionDocumento1 paginaEnglish SolutionTanvi SharmaNessuna valutazione finora
- EnglishDocumento10 pagineEnglishTanvi SharmaNessuna valutazione finora
- POJODocumento2 paginePOJOTanvi SharmaNessuna valutazione finora
- Chapter 8: Central Processing Unit: Cpe 252: Computer Organization 1Documento30 pagineChapter 8: Central Processing Unit: Cpe 252: Computer Organization 1Tanvi SharmaNessuna valutazione finora
- ROOM & LAB Time TableDocumento6 pagineROOM & LAB Time TableTanvi SharmaNessuna valutazione finora
- Wireless Sensor NetworksDocumento24 pagineWireless Sensor NetworksTanvi SharmaNessuna valutazione finora
- Data Structures and Algorithms (Practical) : L T P: 3 0 0 Credits: 02Documento1 paginaData Structures and Algorithms (Practical) : L T P: 3 0 0 Credits: 02Tanvi SharmaNessuna valutazione finora
- CSCE 411H Design and Analysis of Algorithms: Set 8: Greedy Algorithms Prof. Evdokia Nikolova Spring 2013Documento61 pagineCSCE 411H Design and Analysis of Algorithms: Set 8: Greedy Algorithms Prof. Evdokia Nikolova Spring 2013Tanvi SharmaNessuna valutazione finora
- Answer Key of The Competitive Examination: Punjab Public Service CommissionDocumento1 paginaAnswer Key of The Competitive Examination: Punjab Public Service CommissionTanvi SharmaNessuna valutazione finora
- Assignment On Mobile ComputingDocumento4 pagineAssignment On Mobile ComputingTanvi SharmaNessuna valutazione finora
- Course Syllabus: Introduction To Information Technology (Theory-IT101)Documento2 pagineCourse Syllabus: Introduction To Information Technology (Theory-IT101)Tanvi SharmaNessuna valutazione finora
- One Pass AssemblerDocumento2 pagineOne Pass AssemblerTanvi SharmaNessuna valutazione finora
- Roll No. Name Name of The Training Organization Name of The TeacherDocumento2 pagineRoll No. Name Name of The Training Organization Name of The TeacherTanvi SharmaNessuna valutazione finora
- Java Technologies (Practical-IT782) : L T P: 0 0 3 Credits: 02Documento2 pagineJava Technologies (Practical-IT782) : L T P: 0 0 3 Credits: 02Tanvi SharmaNessuna valutazione finora
- Functional ProgrammingDocumento7 pagineFunctional ProgrammingTanvi SharmaNessuna valutazione finora
- Steganography in ImagesDocumento16 pagineSteganography in Imagesseema_kawathekarNessuna valutazione finora
- 2D Discrete Cosine TransformDocumento12 pagine2D Discrete Cosine TransformakshayaNessuna valutazione finora
- A Bibliography On Blind Methods For IdenDocumento11 pagineA Bibliography On Blind Methods For IdenSrilakshmi VNessuna valutazione finora
- Facial Features ExtractionDocumento12 pagineFacial Features ExtractionSohaib Lucky CharmNessuna valutazione finora
- DCT Based Video Watermarking in MATLAB PDFDocumento11 pagineDCT Based Video Watermarking in MATLAB PDFKamlesh DahiyaNessuna valutazione finora
- A Novel Video EncryptionDocumento4 pagineA Novel Video EncryptionSuganya SelvarajNessuna valutazione finora
- Image Fusion Using Various Transforms: IPASJ International Journal of Computer Science (IIJCS)Documento8 pagineImage Fusion Using Various Transforms: IPASJ International Journal of Computer Science (IIJCS)International Journal of Application or Innovation in Engineering & ManagementNessuna valutazione finora
- Major Project Synopsis1-NewDocumento13 pagineMajor Project Synopsis1-NewShivani goswamiNessuna valutazione finora
- An Improved Method of Speech Compression Using Warped LPC and Mlt-Spiht AlgorithmDocumento10 pagineAn Improved Method of Speech Compression Using Warped LPC and Mlt-Spiht AlgorithmHadeel OsmanNessuna valutazione finora
- Digital Image Forgery DetectionDocumento25 pagineDigital Image Forgery DetectionAli BabarNessuna valutazione finora
- Steganography in PictureDocumento24 pagineSteganography in Picturesilessingh100% (1)
- A Steganography Scheme On JPEG Compressed Cover Image With High Embedding CapacityDocumento23 pagineA Steganography Scheme On JPEG Compressed Cover Image With High Embedding Capacitychinnujan24Nessuna valutazione finora
- Discrete Cosine TransformDocumento12 pagineDiscrete Cosine TransformGeleta AmanNessuna valutazione finora
- Huffman Coding PaperDocumento3 pagineHuffman Coding Paperrohith4991Nessuna valutazione finora
- Deep Learning For Environmentally Robust Speech Recognition - An Overview of Recent Developments PDFDocumento28 pagineDeep Learning For Environmentally Robust Speech Recognition - An Overview of Recent Developments PDF福福Nessuna valutazione finora
- Image Segmentation Using Nearest Neighbor Classifier in MatlabDocumento16 pagineImage Segmentation Using Nearest Neighbor Classifier in MatlabRashi AgarwalNessuna valutazione finora
- Digital Image Watermarking PHD ThesisDocumento7 pagineDigital Image Watermarking PHD Thesiskarenalvarezreno100% (1)
- Digital Image Processing - S. Jayaraman, S. Esakkirajan and T. VeerakumarDocumento111 pagineDigital Image Processing - S. Jayaraman, S. Esakkirajan and T. VeerakumarMonishaNessuna valutazione finora
- Modified Discrete Cosine Transform - Its Implications For Audio Coding and Error ConcealmentDocumento10 pagineModified Discrete Cosine Transform - Its Implications For Audio Coding and Error ConcealmentdhermioneNessuna valutazione finora
- DCT-History - How I Came Up With The Discrete Cosine TransformDocumento2 pagineDCT-History - How I Came Up With The Discrete Cosine Transformworkhardplayhard100% (5)
- Python Fundamentals For Machine Learning Version1Documento58 paginePython Fundamentals For Machine Learning Version1NABI MNessuna valutazione finora
- Feature Extraction Methods LPC, PLP and MFCCDocumento5 pagineFeature Extraction Methods LPC, PLP and MFCCRasool Reddy100% (1)
- Matlab ExercisesDocumento5 pagineMatlab Exercisesj_salazar20Nessuna valutazione finora
- 18AEE15 Advanced Digital Image Processing LTPC 3 0 0 3: Course OutcomesDocumento1 pagina18AEE15 Advanced Digital Image Processing LTPC 3 0 0 3: Course Outcomesranjani093Nessuna valutazione finora
- A Project On Digital Watermarking Using MatlabDocumento24 pagineA Project On Digital Watermarking Using MatlabAjith P ShettyNessuna valutazione finora
- Chapter 2 - Two Dimensional System: 1. Discrete Fourier Transform (DFT)Documento11 pagineChapter 2 - Two Dimensional System: 1. Discrete Fourier Transform (DFT)Gorakh Raj JoshiNessuna valutazione finora
- An Audio Encryption Scheme Based On Fast Walsh HadDocumento11 pagineAn Audio Encryption Scheme Based On Fast Walsh Hadanurag kumar singhNessuna valutazione finora
- A Semi-Blind Reference Watermarking Scheme Using DWT-DCT-SVD For Copyright ProtectionDocumento14 pagineA Semi-Blind Reference Watermarking Scheme Using DWT-DCT-SVD For Copyright ProtectionAnonymous Gl4IRRjzNNessuna valutazione finora
- 2 - FPGA Implementation of Pipelined 2D-DCT and Quantization Architecture For JPEG Image Compression.Documento6 pagine2 - FPGA Implementation of Pipelined 2D-DCT and Quantization Architecture For JPEG Image Compression.Mahesh MahiNessuna valutazione finora
- Tms320C62X Image/Videoprocessing Library: Programmer'S ReferenceDocumento125 pagineTms320C62X Image/Videoprocessing Library: Programmer'S ReferenceKariem MuhammedNessuna valutazione finora