Potrebbero piacerti anche
- Sun in AstrologyDocumento60 pagineSun in Astrologyrajesh.shirwal382100% (1)
- Review Taylor SeriesDocumento5 pagineReview Taylor Seriestarun gehlot100% (1)
- Microsoft Word - Bhavas in DetailDocumento38 pagineMicrosoft Word - Bhavas in DetailAlbert HuangNessuna valutazione finora
- Lecture7, Linear TransformationDocumento36 pagineLecture7, Linear TransformationHisham MostafaNessuna valutazione finora
- Solving Differential EquationsDocumento9 pagineSolving Differential EquationsJong CruzNessuna valutazione finora
- Elementary Differential EquationsDocumento664 pagineElementary Differential EquationsBećo Merulić100% (4)
- Intro to Numerical Methods & MatlabDocumento45 pagineIntro to Numerical Methods & MatlabMd Jahirul Islam100% (1)
- Graha Lagna Phala (Results of Placement of Grahas in Lagna Bhava)Documento31 pagineGraha Lagna Phala (Results of Placement of Grahas in Lagna Bhava)Varaha Mihira100% (6)
- Set TheoryDocumento22 pagineSet Theoryjames SmithNessuna valutazione finora
- Integration (Calculus) Mathematics Question BankDa EverandIntegration (Calculus) Mathematics Question BankNessuna valutazione finora
- Counting Principles, Permutations & CombinationsDocumento19 pagineCounting Principles, Permutations & CombinationsPrashantTrehanNessuna valutazione finora
- Elementary Differential Equations with Linear AlgebraDa EverandElementary Differential Equations with Linear AlgebraNessuna valutazione finora
- NavamsaDocumento7 pagineNavamsarajesh.shirwal382Nessuna valutazione finora
- Lesson 2 DiscriminantDocumento6 pagineLesson 2 DiscriminantErwin GaraldeNessuna valutazione finora
- Significations of The Lagna BhavaDocumento13 pagineSignifications of The Lagna Bhavarajesh.shirwal382Nessuna valutazione finora
- Embedded C LanguageDocumento10 pagineEmbedded C Languagerajesh.shirwal382Nessuna valutazione finora
- Analytic Geometry - Lecture FineDocumento110 pagineAnalytic Geometry - Lecture FineJosephbraken Balderama LabacanacruzNessuna valutazione finora
- G10 DLP Q2 Week 1 Day 3Documento11 pagineG10 DLP Q2 Week 1 Day 3Kenneth Carl E. KadusaleNessuna valutazione finora
- Euclid's Geometry: 1 Origins of Geometry 2 The Axiomatic MethodDocumento8 pagineEuclid's Geometry: 1 Origins of Geometry 2 The Axiomatic MethodFelix PascuaNessuna valutazione finora
- 1 Functions, Limits and ContinuityDocumento6 pagine1 Functions, Limits and ContinuityReign dropping100% (1)
- Number TheoryDocumento85 pagineNumber TheoryArjunRanaNessuna valutazione finora
- Vector AnalysisDocumento182 pagineVector AnalysisArslan KianiNessuna valutazione finora
- MATH 10 Module 4 (Rational Exponents and Radical Expressions)Documento49 pagineMATH 10 Module 4 (Rational Exponents and Radical Expressions)Karla MarasiganNessuna valutazione finora
- Topic 20 Further TrigonometryDocumento22 pagineTopic 20 Further TrigonometryAntwayne Youcantstopmaprogress HardieNessuna valutazione finora
- Abstract Algebra AnswersDocumento26 pagineAbstract Algebra AnswersAlexander ClaussenNessuna valutazione finora
- Introduction To Modern GeometryDocumento73 pagineIntroduction To Modern GeometrycergNessuna valutazione finora
- Love MarriageDocumento3 pagineLove Marriagerajesh.shirwal382Nessuna valutazione finora
- Trigonometric Function and IdentitiesDocumento2 pagineTrigonometric Function and Identitieswyn perez100% (1)
- Mathematics ReflectioniozonesDocumento367 pagineMathematics Reflectioniozonesvrun100% (2)
- Definite Integral (Calculus) Mathematics E-Book For Public ExamsDa EverandDefinite Integral (Calculus) Mathematics E-Book For Public ExamsValutazione: 4 su 5 stelle4/5 (2)
- Linear Algebra II SyllabusDocumento2 pagineLinear Algebra II SyllabusMiliyon TilahunNessuna valutazione finora
- TrigonometryDocumento1 paginaTrigonometryJem Baes0% (1)
- Inverse Trigonometric Functions (Trigonometry) Mathematics Question BankDa EverandInverse Trigonometric Functions (Trigonometry) Mathematics Question BankNessuna valutazione finora
- Mechanical Behavior of Materials 01 PDFDocumento54 pagineMechanical Behavior of Materials 01 PDFjunee100% (2)
- Fundamental Counting PrincipleDocumento5 pagineFundamental Counting PrincipleRhonna Joy MalabanaNessuna valutazione finora
- MATH 113 Integral Calculus ProblemsDocumento13 pagineMATH 113 Integral Calculus ProblemsStand Out100% (1)
- Calculus 3 Lecture Notes 1 PDFDocumento240 pagineCalculus 3 Lecture Notes 1 PDFJamena AbbasNessuna valutazione finora
- Euclidean and Non Euclidean GeometryDocumento5 pagineEuclidean and Non Euclidean GeometryGiorgi BalkhamishviliNessuna valutazione finora
- Advanced Calculus LecturesDocumento216 pagineAdvanced Calculus LecturesGabriel Vasconcelos100% (1)
- Modern Geometry Principles with Applications to Plane and Spherical FiguresDocumento244 pagineModern Geometry Principles with Applications to Plane and Spherical FiguresMitch Lim100% (3)
- 27 Nakshatra PadasDocumento13 pagine27 Nakshatra PadasAstrologer in Dubai Call 0586846501Nessuna valutazione finora
- James J. Tattersall-Elementary Number Theory in Nine Chapters-Cambridge University Press (2005)Documento443 pagineJames J. Tattersall-Elementary Number Theory in Nine Chapters-Cambridge University Press (2005)Harold AponteNessuna valutazione finora
- Discrete Structure JHCSCDocumento21 pagineDiscrete Structure JHCSCrendezvousfrNessuna valutazione finora
- LINEAR RECURRENCEDocumento14 pagineLINEAR RECURRENCEnirajcj0% (1)
- Math in Our World - Module 3.1Documento10 pagineMath in Our World - Module 3.1Gee Lysa Pascua Vilbar100% (1)
- MATH10 Language of Mathematics Intersession2019Documento48 pagineMATH10 Language of Mathematics Intersession2019Jehann TanNessuna valutazione finora
- CMSC 56 Slide 06 - Set TheoryDocumento37 pagineCMSC 56 Slide 06 - Set TheoryCK LunaNessuna valutazione finora
- The History of Trigonometry and of Trigonometric Functions May Span Nearly 4Documento10 pagineThe History of Trigonometry and of Trigonometric Functions May Span Nearly 4chadlow100% (2)
- Approved Innovative Course: Modgeo 1.0Documento5 pagineApproved Innovative Course: Modgeo 1.0Grace 0815Nessuna valutazione finora
- Parabola of Analytic GeometryDocumento58 pagineParabola of Analytic Geometryaerogem618100% (1)
- Linear AlgebraDocumento466 pagineLinear Algebramfeinber100% (1)
- Number Theory AMC8 SyllabusDocumento2 pagineNumber Theory AMC8 SyllabusRutvik ShahNessuna valutazione finora
- Planarity and EulerDocumento9 paginePlanarity and EulerJeffrey LubianoNessuna valutazione finora
- Theory of Computation Lecture NotesDocumento38 pagineTheory of Computation Lecture NotesParesh PanditraoNessuna valutazione finora
- Garcia College of Technology Kalibo, Aklan Electrical Engineering DepartmentDocumento7 pagineGarcia College of Technology Kalibo, Aklan Electrical Engineering DepartmentgregNessuna valutazione finora
- Solving System of Linear Equations Unit Plan TemplateDocumento6 pagineSolving System of Linear Equations Unit Plan Templateapi-351781754Nessuna valutazione finora
- Calculus II - Series - Convergence - DivergenceDocumento8 pagineCalculus II - Series - Convergence - DivergencemengelhuNessuna valutazione finora
- Writing A Matrix Into Row Echelon FormDocumento1 paginaWriting A Matrix Into Row Echelon FormMatthewNessuna valutazione finora
- College Algebra FundamentalsDocumento8 pagineCollege Algebra FundamentalsMichael FigueroaNessuna valutazione finora
- Natural NumberDocumento8 pagineNatural NumberkentbnxNessuna valutazione finora
- Solid Geometry Syllabus 2016Documento9 pagineSolid Geometry Syllabus 2016yeah_123100% (2)
- Non-Positional Number SystemDocumento6 pagineNon-Positional Number SystemhellorosyNessuna valutazione finora
- Lecture 2 (Trigonometric Integrals)Documento27 pagineLecture 2 (Trigonometric Integrals)Clarisson Rizzie P. CanluboNessuna valutazione finora
- Integral Calculus: Engr. Anacleto M. Cortez JRDocumento10 pagineIntegral Calculus: Engr. Anacleto M. Cortez JRPanfilo Diaz LacsonNessuna valutazione finora
- Obe Nce 311Documento12 pagineObe Nce 311Jayson IsidroNessuna valutazione finora
- The Real Number SystemDocumento36 pagineThe Real Number SystemKalson UmpuNessuna valutazione finora
- Numerical Analysis ExercisesDocumento160 pagineNumerical Analysis ExercisesA.BenhariNessuna valutazione finora
- Postgraduate Mathematics Courses, Schemes & SyllabiDocumento24 paginePostgraduate Mathematics Courses, Schemes & Syllabichuyenvien94Nessuna valutazione finora
- Number Theory SyllabusDocumento3 pagineNumber Theory SyllabusMiliyon TilahunNessuna valutazione finora
- A Positive IntegerDocumento1 paginaA Positive Integerrajesh.shirwal382Nessuna valutazione finora
- Lakshmi Siddha Beej MantraDocumento1 paginaLakshmi Siddha Beej Mantrarajesh.shirwal382Nessuna valutazione finora
- Interesting Facts About Somnath TempleDocumento3 pagineInteresting Facts About Somnath Templerajesh.shirwal382Nessuna valutazione finora
- 1ST CuspDocumento25 pagine1ST Cusprajesh.shirwal382Nessuna valutazione finora
- Hanuman Stutihi English LyricsDocumento1 paginaHanuman Stutihi English Lyricsrajesh.shirwal382Nessuna valutazione finora
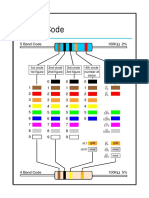
- Common resistor color codes chartDocumento2 pagineCommon resistor color codes chartkarwalpkNessuna valutazione finora
- Case Study in RtlinuxDocumento5 pagineCase Study in Rtlinuxrajesh.shirwal382Nessuna valutazione finora
- HOUSESDocumento26 pagineHOUSESAman SodhiNessuna valutazione finora
- Resistor LegendDocumento6 pagineResistor LegendRuban PalaniNessuna valutazione finora
- DandruffDocumento2 pagineDandruffrajesh.shirwal382Nessuna valutazione finora
- Reading Capacitor CodesDocumento2 pagineReading Capacitor Codesfurious143Nessuna valutazione finora
- I always meditate upon HanumanDocumento1 paginaI always meditate upon Hanumanrajesh.shirwal382Nessuna valutazione finora
- House GroupingDocumento6 pagineHouse Groupingrajesh.shirwal382Nessuna valutazione finora
- Res CodeDocumento2 pagineRes Coderajesh.shirwal382Nessuna valutazione finora
- Death Dosham / Marana Samaya Dosham Death Dosha's Are 3 Types. They AreDocumento1 paginaDeath Dosham / Marana Samaya Dosham Death Dosha's Are 3 Types. They Arerajesh.shirwal382Nessuna valutazione finora
- MCA New SyllabusDocumento31 pagineMCA New Syllabusa janaNessuna valutazione finora
- First BhavaDocumento12 pagineFirst Bhavarajesh.shirwal382Nessuna valutazione finora
- Why Use DMADocumento8 pagineWhy Use DMArajesh.shirwal382100% (1)
- Weaknesses and Drawbacks of Moon Signs in ZodiacDocumento2 pagineWeaknesses and Drawbacks of Moon Signs in Zodiacrajesh.shirwal382Nessuna valutazione finora
- PTU MCA SyllabusDocumento42 paginePTU MCA SyllabusSaloni Sharma0% (1)
- 11Documento15 pagine11rajesh.shirwal382Nessuna valutazione finora
- 1Documento9 pagine1rajesh.shirwal382Nessuna valutazione finora
- REVIEWER IN GENERAL MATHEMATICS PART IDocumento1 paginaREVIEWER IN GENERAL MATHEMATICS PART IKristine CastroNessuna valutazione finora
- Professor Smith Math 295 Lecture Notes: 1 October 29: Compactness, Open Covers, and SubcoversDocumento5 pagineProfessor Smith Math 295 Lecture Notes: 1 October 29: Compactness, Open Covers, and Subcovershamza iftikharNessuna valutazione finora
- Estimating Square Root CardsDocumento6 pagineEstimating Square Root Cardsapi-265678639Nessuna valutazione finora
- Complex NumbersDocumento18 pagineComplex NumbersMIGHTY KNIGHTNessuna valutazione finora
- Partial DerivativesDocumento12 paginePartial DerivativesEdu Manzano AlbayNessuna valutazione finora
- Tribhuvan University: Institute of Science and Technology 2065Documento2 pagineTribhuvan University: Institute of Science and Technology 2065vikashNessuna valutazione finora
- Differentiation of y Ax N by The General RuleDocumento2 pagineDifferentiation of y Ax N by The General RuleJericho CunananNessuna valutazione finora
- Comcot Manual V 17 PDFDocumento65 pagineComcot Manual V 17 PDFmerdeka48Nessuna valutazione finora
- Printable Collection of Bode Plot Web PagesDocumento48 paginePrintable Collection of Bode Plot Web PagesThan HtetNessuna valutazione finora
- Calculus II SyllabusDocumento2 pagineCalculus II SyllabusMiliyon TilahunNessuna valutazione finora
- LPP Model Formation, Module-1Documento4 pagineLPP Model Formation, Module-1Khushal JhaNessuna valutazione finora
- 1a MaterialDocumento22 pagine1a MaterialKshavzhxnNessuna valutazione finora
- Home Assignment 1 PHY 306/604 Advanced Statistical MechanicsDocumento4 pagineHome Assignment 1 PHY 306/604 Advanced Statistical MechanicsSayan KuntiNessuna valutazione finora
- 10 EMI 07 Sampled Data Systems and The Z-TransformDocumento39 pagine10 EMI 07 Sampled Data Systems and The Z-Transformapi-3707706Nessuna valutazione finora
- Calculus 1Documento1 paginaCalculus 1alimajeg2Nessuna valutazione finora
- Vector Field: Vector Fields On Subsets of Euclidean SpaceDocumento8 pagineVector Field: Vector Fields On Subsets of Euclidean SpaceDiego VillalobosNessuna valutazione finora
- SSC CGL Numerical Aptitude Basic AlgebraDocumento11 pagineSSC CGL Numerical Aptitude Basic AlgebraIAS EXAM PORTALNessuna valutazione finora
- Lesson Plan in Mathematics 11Documento5 pagineLesson Plan in Mathematics 11markNessuna valutazione finora
- Simbol Matematik 2Documento12 pagineSimbol Matematik 2Anonymous Ztyzc5Nessuna valutazione finora
- mywbut Math SyllabusDocumento3 paginemywbut Math SyllabusSubrata PaulNessuna valutazione finora
- HW-5 Week 5: Dhananjai SharmaDocumento6 pagineHW-5 Week 5: Dhananjai Sharmadhananjaisharma123Nessuna valutazione finora
- Additional Exercises for Convex Optimization TopicsDocumento152 pagineAdditional Exercises for Convex Optimization TopicsnudalaNessuna valutazione finora
- Iterative Methods Questions MMEDocumento8 pagineIterative Methods Questions MMEswiftmessiNessuna valutazione finora