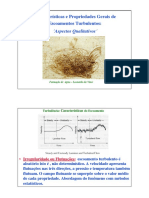
Potrebbero piacerti anche
- Algoritmos e Estruturas de Dados II - 1a Lista de ExercíciosDocumento9 pagineAlgoritmos e Estruturas de Dados II - 1a Lista de ExercíciosNetoberolaNessuna valutazione finora
- Avaliação 2 - PROGRAMAÇÃO PARALELADocumento6 pagineAvaliação 2 - PROGRAMAÇÃO PARALELAMurilo MontinoNessuna valutazione finora
- Implementação de Otimização Colônia de Formigas PDFDocumento14 pagineImplementação de Otimização Colônia de Formigas PDFSenhor MNessuna valutazione finora
- Lista de exercícios de algoritmos e estruturas de dadosDocumento6 pagineLista de exercícios de algoritmos e estruturas de dadosDavid AlanNessuna valutazione finora
- Metodo de AdamsDocumento10 pagineMetodo de AdamsHigorNessuna valutazione finora
- UFV Algoritmos Estruturas Lista Exercícios ComplexidadeDocumento3 pagineUFV Algoritmos Estruturas Lista Exercícios ComplexidadeJoão Paulo OliveiraNessuna valutazione finora
- 02_binario_in_out_precedencia_pipelinesolucaoDocumento19 pagine02_binario_in_out_precedencia_pipelinesolucaoAntonio Carlos BorréNessuna valutazione finora
- 3a-Lista de Exercicios Programacao-2022Documento6 pagine3a-Lista de Exercicios Programacao-2022Luan Henrique HillesheimNessuna valutazione finora
- PAA Trabalho Ordena oDocumento6 paginePAA Trabalho Ordena oAlice CabralNessuna valutazione finora
- Ponteiros e Alocação DinâmicaDocumento14 paginePonteiros e Alocação DinâmicaLobo Do CerradoNessuna valutazione finora
- Lista1 AlgoritimosDocumento4 pagineLista1 AlgoritimosMarkinho LiraNessuna valutazione finora
- Aula13 Somas de SeriesDocumento5 pagineAula13 Somas de SeriesGino CNessuna valutazione finora
- Atividade Avaliativa Introdução A ProgramaçãoDocumento70 pagineAtividade Avaliativa Introdução A ProgramaçãoandrepenhaNessuna valutazione finora
- Exercícios C estruturasDocumento15 pagineExercícios C estruturasBartolomeu DiasNessuna valutazione finora
- 2a-Lista de Exercicios Programacao-2022Documento4 pagine2a-Lista de Exercicios Programacao-2022Luan Henrique HillesheimNessuna valutazione finora
- Alocação dinâmica de memória em CDocumento7 pagineAlocação dinâmica de memória em Civan bragaNessuna valutazione finora
- Aula06 Mais Exemplos de RepeticaoDocumento5 pagineAula06 Mais Exemplos de RepeticaoGino CNessuna valutazione finora
- Lista I ResoluçãoDocumento8 pagineLista I Resoluçãojesuliana100% (1)
- Resolucao EDO NuméricaDocumento16 pagineResolucao EDO NuméricabheaoliveriaNessuna valutazione finora
- ComplexDocumento4 pagineComplexVitor RibasNessuna valutazione finora
- Lista de Exercícios de AlgoritmosDocumento19 pagineLista de Exercícios de AlgoritmosLuiz CarlosNessuna valutazione finora
- Introdução A Algoritmos Utilizando o PascalDocumento10 pagineIntrodução A Algoritmos Utilizando o PascalcportesNessuna valutazione finora
- Material de Apoio Parte 1 FCI 2010 2Documento12 pagineMaterial de Apoio Parte 1 FCI 2010 2Mateus MadeiraNessuna valutazione finora
- Aula 07 Complexidade de AlgoritmosDocumento57 pagineAula 07 Complexidade de AlgoritmosskimorodNessuna valutazione finora
- A Estrutura de Um Algoritmo em PseudocódigoDocumento16 pagineA Estrutura de Um Algoritmo em PseudocódigoKelly BatistaNessuna valutazione finora
- Exercícios Linguagem CDocumento4 pagineExercícios Linguagem Ccrismb75Nessuna valutazione finora
- Estudo do método de fatoração Crivo QuadráticoDocumento13 pagineEstudo do método de fatoração Crivo QuadráticoRubens Vilhena FonsecaNessuna valutazione finora
- Corretor Ortográfico.: Universidade Federal de Sergipe Departamento de MatemáticaDocumento9 pagineCorretor Ortográfico.: Universidade Federal de Sergipe Departamento de Matemáticavitoria telesNessuna valutazione finora
- Ica MQNR 2020 PDFDocumento43 pagineIca MQNR 2020 PDFWilliam SantosNessuna valutazione finora
- Aula02 - Estrutura Condicional Simples e Composta PDFDocumento55 pagineAula02 - Estrutura Condicional Simples e Composta PDFLeandro GalvãoNessuna valutazione finora
- Introdução À Linguagem C++Documento64 pagineIntrodução À Linguagem C++DAVI BARBOSA DE MEDEIROSNessuna valutazione finora
- Python básicoDocumento8 paginePython básicoSebastião Lima100% (1)
- Aula 1 - Algoritmos DiretosDocumento5 pagineAula 1 - Algoritmos Diretoscarlos gabrielNessuna valutazione finora
- Análise de Algoritmo de OrdenaçãoDocumento19 pagineAnálise de Algoritmo de OrdenaçãoJean GomesNessuna valutazione finora
- Repetições, condicionais, fatorial, Fibonacci, sériesDocumento14 pagineRepetições, condicionais, fatorial, Fibonacci, sériesBruno HerysonNessuna valutazione finora
- Informatica LaurenDocumento9 pagineInformatica LaurenLemos ManuelNessuna valutazione finora
- FT 1 - Atribuicoes e Comandos CondicionaisDocumento6 pagineFT 1 - Atribuicoes e Comandos CondicionaisInês RebeloNessuna valutazione finora
- Lista 1 Exerc IccDocumento18 pagineLista 1 Exerc IccMatheus Henrique Lacerda Copi TerzoNessuna valutazione finora
- Mcecilia, Journal Manager, USANDO ALGORITMOS PARA COMPARAR PERFORMANCE DE COMPILADORES DE LINGUAGEM CDocumento8 pagineMcecilia, Journal Manager, USANDO ALGORITMOS PARA COMPARAR PERFORMANCE DE COMPILADORES DE LINGUAGEM CMarco Mateus SoaresNessuna valutazione finora
- AP.AL-07 FDocumento1 paginaAP.AL-07 Fvbruno640Nessuna valutazione finora
- Módulo 1 - Erros e Aritmética de Pontos FlutuantesDocumento6 pagineMódulo 1 - Erros e Aritmética de Pontos FlutuantesRafael GonçalvesNessuna valutazione finora
- 70 QuickSortC OkDocumento6 pagine70 QuickSortC OkDavid GabilanNessuna valutazione finora
- Algoritmos e Programação Estruturada WebDocumento83 pagineAlgoritmos e Programação Estruturada WebAlissan CamargoNessuna valutazione finora
- Algoritmos para cálculo de média, tabuada, imposto de renda e outrosDocumento11 pagineAlgoritmos para cálculo de média, tabuada, imposto de renda e outrosLuyri OeirasNessuna valutazione finora
- MATLAB exercícios resolvidosDocumento10 pagineMATLAB exercícios resolvidosAndersonpassosNessuna valutazione finora
- Algoritmos para resolução de problemas matemáticosDocumento7 pagineAlgoritmos para resolução de problemas matemáticosHumberto FelixxNessuna valutazione finora
- Lista 7 - CI208Documento15 pagineLista 7 - CI208Beatriz KandaNessuna valutazione finora
- Introducao A AnáliseDocumento19 pagineIntroducao A AnáliseCacio HenriqueNessuna valutazione finora
- Análise da Complexidade de AlgoritmosDocumento31 pagineAnálise da Complexidade de AlgoritmosRenata SalgadoNessuna valutazione finora
- Cálculo Numérico: Interpolação Polinomial de HermiteDocumento6 pagineCálculo Numérico: Interpolação Polinomial de HermiteWilson Jaime De CarvalhoNessuna valutazione finora
- Lista 3 AEDsDocumento12 pagineLista 3 AEDsCECILIA CAPURUCHO BOUCHARDETNessuna valutazione finora
- Bioinformática em PythonDocumento27 pagineBioinformática em PythonManoela NascenteNessuna valutazione finora
- Lista1 PDFDocumento27 pagineLista1 PDFHelio JuniorNessuna valutazione finora
- Convert.ToInt32 vs Int32.ParseDocumento2 pagineConvert.ToInt32 vs Int32.ParseJuninho oliveiraNessuna valutazione finora
- Exercicios Resolvidos Matriz e VetorDocumento160 pagineExercicios Resolvidos Matriz e VetorCurtis Hood0% (1)
- Exercicios Resolvidos Matriz e VetorDocumento167 pagineExercicios Resolvidos Matriz e VetorCurtis HoodNessuna valutazione finora
- Análise de AlgoritmosDocumento27 pagineAnálise de Algoritmoscopiarte piratiniNessuna valutazione finora
- R Curso IntroduçãoDocumento113 pagineR Curso IntroduçãoWanly PereiraNessuna valutazione finora
- Controle Vetorial, Máquina De Indução E Métodos NuméricosDa EverandControle Vetorial, Máquina De Indução E Métodos NuméricosNessuna valutazione finora
- Injecao Eletronica BasicaDocumento56 pagineInjecao Eletronica BasicaSantosOliveira100% (1)
- MEV: Princípios e Formação de ImagensDocumento98 pagineMEV: Princípios e Formação de ImagensRonaldo Júnior FernandesNessuna valutazione finora
- Injecao Eletronica BasicaDocumento56 pagineInjecao Eletronica BasicaSantosOliveira100% (1)
- Aula 2Documento25 pagineAula 2gandalf_mlNessuna valutazione finora
- Apostila Algoritmos GeneticosDocumento48 pagineApostila Algoritmos GeneticosjoaobarrozoNessuna valutazione finora
- Apostila Computação EvolutivaDocumento61 pagineApostila Computação EvolutivaRui DiasNessuna valutazione finora
- Introdução ao uso do programa RDocumento50 pagineIntrodução ao uso do programa RCristiano ChristofaroNessuna valutazione finora
- Curso Injeção Eletronica 2Documento141 pagineCurso Injeção Eletronica 2Pampoline Carvalho Chaves Chaves100% (2)
- Aula 3Documento27 pagineAula 3gandalf_mlNessuna valutazione finora
- Fundamentos dos Algoritmos GenéticosDocumento33 pagineFundamentos dos Algoritmos GenéticosTony SoaresNessuna valutazione finora
- 2 TerminologiaDocumento3 pagine2 Terminologiagandalf_mlNessuna valutazione finora
- INTREQ3 w6Documento33 pagineINTREQ3 w6Helloise MotaNessuna valutazione finora
- Recuperação de CondensadoDocumento28 pagineRecuperação de CondensadoMarcelo MargonarNessuna valutazione finora
- Com Ciência - Modelagem Matemática - o Contido e o ResidualDocumento5 pagineCom Ciência - Modelagem Matemática - o Contido e o Residualgandalf_mlNessuna valutazione finora
- Eletro HidráulicaDocumento171 pagineEletro HidráulicaJamil AlmaroneNessuna valutazione finora
- Recuperação de CondensadoDocumento28 pagineRecuperação de CondensadoMarcelo MargonarNessuna valutazione finora
- Pneumatic A ParkerDocumento196 paginePneumatic A Parkerrodrigoferdinandi100% (1)
- MD LE1Documento3 pagineMD LE1gandalf_mlNessuna valutazione finora
- Estrutura de Dados Usando CDocumento16 pagineEstrutura de Dados Usando CLeonardo Costa VieiraNessuna valutazione finora
- Implantação de Sistema Help-Desk em Empresa de ConsultoriaDocumento30 pagineImplantação de Sistema Help-Desk em Empresa de ConsultoriaWagner DamascenoNessuna valutazione finora
- Ensaio de condutividade elétrica de correiasDocumento3 pagineEnsaio de condutividade elétrica de correiasWesley WielNessuna valutazione finora
- Detetor de fumo óptico Ex d para áreas explosivasDocumento20 pagineDetetor de fumo óptico Ex d para áreas explosivasLeonardo M. SilveiraNessuna valutazione finora
- Modelo de Proposta para Trabalho PedagógicoDocumento10 pagineModelo de Proposta para Trabalho PedagógicoProf. Elicio Lima100% (6)
- Parts Manual: 120H Motor GraderDocumento1.068 pagineParts Manual: 120H Motor GraderJoel Rodríguez100% (8)
- Manual de Proprietario Do Motor de Popa Mercury 2.5-3.3HP BDocumento50 pagineManual de Proprietario Do Motor de Popa Mercury 2.5-3.3HP Bq9kram100% (2)
- Espaços de Lazer Público e Privado Na Cidade de Bragança/PADocumento12 pagineEspaços de Lazer Público e Privado Na Cidade de Bragança/PARafael CoimbraNessuna valutazione finora
- Baudrillard e simulacrosDocumento8 pagineBaudrillard e simulacroscmdicolla6163Nessuna valutazione finora
- Exercitando Diagrama Caso de Uso2Documento5 pagineExercitando Diagrama Caso de Uso2Alex Fernandes0% (2)
- Nova métrica funcional para estimativas ágeisDocumento83 pagineNova métrica funcional para estimativas ágeislascarmoNessuna valutazione finora
- Pregos Gerdau - Dimensões e aplicaçõesDocumento8 paginePregos Gerdau - Dimensões e aplicaçõesconsultachNessuna valutazione finora
- Engenharia de manutenção aeronáutica sistemasDocumento50 pagineEngenharia de manutenção aeronáutica sistemasIgor Moura QueirozNessuna valutazione finora
- Check List TrafegoDocumento5 pagineCheck List TrafegoMatheus SanNessuna valutazione finora
- Manual roçadeira articulada MFW Harpia 515Documento25 pagineManual roçadeira articulada MFW Harpia 515walyrysNessuna valutazione finora
- Dissertacao - 2006 - Jose Carlos RuelaDocumento160 pagineDissertacao - 2006 - Jose Carlos RuelaJonnas Câmara de AbreuNessuna valutazione finora
- Piaget Construção de Conceitos - GeométricosDocumento14 paginePiaget Construção de Conceitos - Geométricosshirleymuller046583100% (3)
- Óleos essenciais na culináriaDocumento14 pagineÓleos essenciais na culináriaMayara Letícia LongenNessuna valutazione finora
- Lista de materiais para esculturaDocumento3 pagineLista de materiais para esculturaenilimaleite7435Nessuna valutazione finora
- Tipos de compressores e condensadores em sistemas de refrigeraçãoDocumento3 pagineTipos de compressores e condensadores em sistemas de refrigeraçãoDídimo GomesNessuna valutazione finora
- Lista Precos Soldafria 4Documento72 pagineLista Precos Soldafria 4Ilton SilvaNessuna valutazione finora
- Curso Direitos HumanosDocumento1 paginaCurso Direitos HumanosErik HenriqueNessuna valutazione finora
- Regulamento Mega Ton taxas especiaisDocumento2 pagineRegulamento Mega Ton taxas especiaisJL InformáticaNessuna valutazione finora
- O Jogo e A AprendizagemDocumento7 pagineO Jogo e A AprendizagemLucimara S. SilvaNessuna valutazione finora
- Portaria e Regimento Interno Do CFAPDocumento29 paginePortaria e Regimento Interno Do CFAPMarcos AraújoNessuna valutazione finora
- Tabelas de atenuação e filtros para equalização de áudio em veículosDocumento3 pagineTabelas de atenuação e filtros para equalização de áudio em veículosVanderlei Roberto MorettoNessuna valutazione finora
- Compartilhamento de infraestrutura para telecomDocumento26 pagineCompartilhamento de infraestrutura para telecomFernando SantosNessuna valutazione finora
- Módulo 5 - Implementação Do IPv4 PDFDocumento47 pagineMódulo 5 - Implementação Do IPv4 PDFRafael AlmeidaNessuna valutazione finora
- ELETRONICA - Experimento - Guia 2 - 2010 - 1Documento8 pagineELETRONICA - Experimento - Guia 2 - 2010 - 1Filipe Rodrigues ViannaNessuna valutazione finora
- Desenho técnico - representação e cotagem de peçasDocumento3 pagineDesenho técnico - representação e cotagem de peçasDagdaPicksNessuna valutazione finora