Potrebbero piacerti anche
- Shoe Dog: A Memoir by the Creator of NikeDa EverandShoe Dog: A Memoir by the Creator of NikeValutazione: 4.5 su 5 stelle4.5/5 (537)
- The Yellow House: A Memoir (2019 National Book Award Winner)Da EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Valutazione: 4 su 5 stelle4/5 (98)
- Impact of Stress On Software Engineers Knowledge Sharing and Creativity (A Pakistani Perspective)Documento5 pagineImpact of Stress On Software Engineers Knowledge Sharing and Creativity (A Pakistani Perspective)Integrated Intelligent ResearchNessuna valutazione finora
- RobustClustering Algorithm Based On Complete LinkApplied To Selection Ofbio - Basis Foramino Acid Sequence AnalysisDocumento10 pagineRobustClustering Algorithm Based On Complete LinkApplied To Selection Ofbio - Basis Foramino Acid Sequence AnalysisIntegrated Intelligent ResearchNessuna valutazione finora
- A Study For The Discovery of Web Usage Patterns Using Soft Computing Based Data Clustering TechniquesDocumento14 pagineA Study For The Discovery of Web Usage Patterns Using Soft Computing Based Data Clustering TechniquesIntegrated Intelligent ResearchNessuna valutazione finora
- Paper13 PDFDocumento8 paginePaper13 PDFIntegrated Intelligent ResearchNessuna valutazione finora
- Multidimensional Suppression For KAnonymity in Public Dataset Using See5Documento5 pagineMultidimensional Suppression For KAnonymity in Public Dataset Using See5Integrated Intelligent ResearchNessuna valutazione finora
- Predicting Movie Success Based On IMDB DataDocumento4 paginePredicting Movie Success Based On IMDB DataIntegrated Intelligent ResearchNessuna valutazione finora
- Analysis of Classification Algorithm in Data MiningDocumento4 pagineAnalysis of Classification Algorithm in Data MiningIntegrated Intelligent ResearchNessuna valutazione finora
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDa EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeValutazione: 4 su 5 stelle4/5 (5794)
- The Little Book of Hygge: Danish Secrets to Happy LivingDa EverandThe Little Book of Hygge: Danish Secrets to Happy LivingValutazione: 3.5 su 5 stelle3.5/5 (400)
- Grit: The Power of Passion and PerseveranceDa EverandGrit: The Power of Passion and PerseveranceValutazione: 4 su 5 stelle4/5 (588)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDa EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureValutazione: 4.5 su 5 stelle4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDa EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryValutazione: 3.5 su 5 stelle3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDa EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceValutazione: 4 su 5 stelle4/5 (895)
- Team of Rivals: The Political Genius of Abraham LincolnDa EverandTeam of Rivals: The Political Genius of Abraham LincolnValutazione: 4.5 su 5 stelle4.5/5 (234)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDa EverandNever Split the Difference: Negotiating As If Your Life Depended On ItValutazione: 4.5 su 5 stelle4.5/5 (838)
- The Emperor of All Maladies: A Biography of CancerDa EverandThe Emperor of All Maladies: A Biography of CancerValutazione: 4.5 su 5 stelle4.5/5 (271)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDa EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaValutazione: 4.5 su 5 stelle4.5/5 (266)
- On Fire: The (Burning) Case for a Green New DealDa EverandOn Fire: The (Burning) Case for a Green New DealValutazione: 4 su 5 stelle4/5 (74)
- The Unwinding: An Inner History of the New AmericaDa EverandThe Unwinding: An Inner History of the New AmericaValutazione: 4 su 5 stelle4/5 (45)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDa EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersValutazione: 4.5 su 5 stelle4.5/5 (345)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDa EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyValutazione: 3.5 su 5 stelle3.5/5 (2259)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDa EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreValutazione: 4 su 5 stelle4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Da EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Valutazione: 4.5 su 5 stelle4.5/5 (121)
- Her Body and Other Parties: StoriesDa EverandHer Body and Other Parties: StoriesValutazione: 4 su 5 stelle4/5 (821)
- FINAL (SG) - PR1 11 - 12 - UNIT 4 - LESSON 1 - Relevant Literature Sources For Qualitative Research PDFDocumento16 pagineFINAL (SG) - PR1 11 - 12 - UNIT 4 - LESSON 1 - Relevant Literature Sources For Qualitative Research PDFKat DumpNessuna valutazione finora
- Multi Version Two-Phase Locking ProtocolDocumento2 pagineMulti Version Two-Phase Locking ProtocolAnjali Ganesh Jivani100% (9)
- 4a - Database SystemsDocumento35 pagine4a - Database SystemsPrakriti ShresthaNessuna valutazione finora
- Module 4Documento37 pagineModule 4Aryan VNessuna valutazione finora
- Eksistensi Citra Perempuan Dalam Novel Nadira KaryDocumento8 pagineEksistensi Citra Perempuan Dalam Novel Nadira KaryNyayu AlifahNessuna valutazione finora
- Designing An Adaptive Security Architecture For Protection From Advanced AttacksDocumento8 pagineDesigning An Adaptive Security Architecture For Protection From Advanced AttacksOscar Gopro SEISNessuna valutazione finora
- Boba (2001) - Introductory Guide To Crime Analysis and MappingDocumento74 pagineBoba (2001) - Introductory Guide To Crime Analysis and MappingPoliceFoundation100% (1)
- Resume Aditya GuptaDocumento1 paginaResume Aditya GuptaSai BodduNessuna valutazione finora
- The Definitive Airline Operations and KPI GuideDocumento71 pagineThe Definitive Airline Operations and KPI Guidethanapong mntsaNessuna valutazione finora
- Oracle Dbms - Stats TipsDocumento6 pagineOracle Dbms - Stats TipsHeshamAboulattaNessuna valutazione finora
- Syllabus of Big Data Analysis - ProposedDocumento2 pagineSyllabus of Big Data Analysis - ProposedSarit ChakrabortyNessuna valutazione finora
- Data DictionaryDocumento12 pagineData Dictionaryvanishree100% (1)
- Choosing Your Database Migration Path To AzureDocumento61 pagineChoosing Your Database Migration Path To AzureLeopoldo Garcia GarciaNessuna valutazione finora
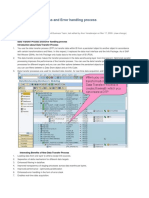
- DTP and Error HandlingDocumento4 pagineDTP and Error HandlingVinoth Kumar PeethambaramNessuna valutazione finora
- Resources and Help For GISDocumento5 pagineResources and Help For GISAnnette De La RosaNessuna valutazione finora
- Developing A Job Description For A Chief Clinical Informatics (Or Information) Officer (CCIO)Documento16 pagineDeveloping A Job Description For A Chief Clinical Informatics (Or Information) Officer (CCIO)AlessioNavarraNessuna valutazione finora
- Consumer Behavior - Test Bank SchiffmanDocumento33 pagineConsumer Behavior - Test Bank SchiffmanEnsoyNessuna valutazione finora
- Ip Practical File GVDocumento46 pagineIp Practical File GVSwagata SharmaNessuna valutazione finora
- Opensips PDFDocumento27 pagineOpensips PDFfequayNessuna valutazione finora
- CSE451 Introduction To Operating Systems Winter 2012: PagingDocumento29 pagineCSE451 Introduction To Operating Systems Winter 2012: PagingnadiyasabinNessuna valutazione finora
- Voting Reported It Er 1Documento32 pagineVoting Reported It Er 1padma babuNessuna valutazione finora
- 08 ArraysDocumento10 pagine08 ArraysXyzNessuna valutazione finora
- TalendOpenStudio DQ UG 7.0.1 en PDFDocumento309 pagineTalendOpenStudio DQ UG 7.0.1 en PDFRonny RoyNessuna valutazione finora
- Writing Scientific Manuscripts: A Guide For UndergraduatesDocumento30 pagineWriting Scientific Manuscripts: A Guide For Undergraduatesfirda diah utamiNessuna valutazione finora
- Mysql vs. SqliteDocumento15 pagineMysql vs. SqlitePedro Leite (Mindset Épico)Nessuna valutazione finora
- Smart Factory Navigator: Lukas Budde Roman Hänggi Thomas Friedli Adrian RüedyDocumento297 pagineSmart Factory Navigator: Lukas Budde Roman Hänggi Thomas Friedli Adrian RüedySTEFANI NUGRAHANessuna valutazione finora
- 7 Principles of Public SpeakingDocumento6 pagine7 Principles of Public Speakingxiejie22590100% (1)
- Stand Alone RowSetDocumento3 pagineStand Alone RowSetpeterlaskingNessuna valutazione finora
- Advanced Database Management SystemsDocumento2 pagineAdvanced Database Management Systemspreetu1986Nessuna valutazione finora
- Math7WS - Q4 - Week 2Documento4 pagineMath7WS - Q4 - Week 2ELJON MINDORONessuna valutazione finora