Potrebbero piacerti anche
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDa EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeValutazione: 4 su 5 stelle4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDa EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreValutazione: 4 su 5 stelle4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDa EverandNever Split the Difference: Negotiating As If Your Life Depended On ItValutazione: 4.5 su 5 stelle4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDa EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceValutazione: 4 su 5 stelle4/5 (895)
- Grit: The Power of Passion and PerseveranceDa EverandGrit: The Power of Passion and PerseveranceValutazione: 4 su 5 stelle4/5 (588)
- Shoe Dog: A Memoir by the Creator of NikeDa EverandShoe Dog: A Memoir by the Creator of NikeValutazione: 4.5 su 5 stelle4.5/5 (537)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDa EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersValutazione: 4.5 su 5 stelle4.5/5 (344)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDa EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureValutazione: 4.5 su 5 stelle4.5/5 (474)
- Her Body and Other Parties: StoriesDa EverandHer Body and Other Parties: StoriesValutazione: 4 su 5 stelle4/5 (821)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Da EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Valutazione: 4.5 su 5 stelle4.5/5 (121)
- The Emperor of All Maladies: A Biography of CancerDa EverandThe Emperor of All Maladies: A Biography of CancerValutazione: 4.5 su 5 stelle4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingDa EverandThe Little Book of Hygge: Danish Secrets to Happy LivingValutazione: 3.5 su 5 stelle3.5/5 (400)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDa EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyValutazione: 3.5 su 5 stelle3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)Da EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Valutazione: 4 su 5 stelle4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDa EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaValutazione: 4.5 su 5 stelle4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDa EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryValutazione: 3.5 su 5 stelle3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnDa EverandTeam of Rivals: The Political Genius of Abraham LincolnValutazione: 4.5 su 5 stelle4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealDa EverandOn Fire: The (Burning) Case for a Green New DealValutazione: 4 su 5 stelle4/5 (74)
- The Unwinding: An Inner History of the New AmericaDa EverandThe Unwinding: An Inner History of the New AmericaValutazione: 4 su 5 stelle4/5 (45)
- Amazon Organizational StructureDocumento2 pagineAmazon Organizational StructurePolina100% (1)
- Mittal Resume SP14Documento1 paginaMittal Resume SP14RishiKumarMittalNessuna valutazione finora
- P403PSP2985577 Repayment ReportDocumento9 pagineP403PSP2985577 Repayment ReportgingeevimalNessuna valutazione finora
- B0 S0 UEl Qy Q4 CSODrDocumento2 pagineB0 S0 UEl Qy Q4 CSODrgingeevimalNessuna valutazione finora
- PythonDocumento58 paginePythonSirishaNessuna valutazione finora
- QuestionAnalysis ReportDocumento1 paginaQuestionAnalysis ReportgingeevimalNessuna valutazione finora
- Enrollment BackendDocumento3 pagineEnrollment BackendgingeevimalNessuna valutazione finora
- Learn Python in Three HoursDocumento53 pagineLearn Python in Three HoursshahedsNessuna valutazione finora
- 2 - Companies SearchDocumento4 pagine2 - Companies SearchgingeevimalNessuna valutazione finora
- Boat SaftyDocumento2 pagineBoat SaftygingeevimalNessuna valutazione finora
- RAilDocumento10 pagineRAilgingeevimalNessuna valutazione finora
- SSRS Install Step by StepDocumento2 pagineSSRS Install Step by StepgingeevimalNessuna valutazione finora
- Bio DataDocumento1 paginaBio DatagingeevimalNessuna valutazione finora
- DBDocumento1 paginaDBgingeevimalNessuna valutazione finora
- Bio DataDocumento1 paginaBio DatagingeevimalNessuna valutazione finora
- Billing System Synopsis: AbstractDocumento4 pagineBilling System Synopsis: AbstractgingeevimalNessuna valutazione finora
- Testing SampleDocumento6 pagineTesting SamplegingeevimalNessuna valutazione finora
- 208 DataflowdgmDocumento46 pagine208 DataflowdgmgingeevimalNessuna valutazione finora
- Application Blank Trident-1Documento5 pagineApplication Blank Trident-1gingeevimalNessuna valutazione finora
- Need To ProvideDocumento1 paginaNeed To ProvidegingeevimalNessuna valutazione finora
- An RFID-based System For Emergency Health Care ServicesDocumento4 pagineAn RFID-based System For Emergency Health Care ServicesgingeevimalNessuna valutazione finora
- ArchDocumento1 paginaArchgingeevimalNessuna valutazione finora
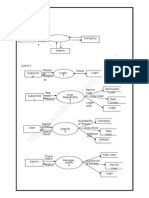
- Data Flow DiagramDocumento2 pagineData Flow DiagramgingeevimalNessuna valutazione finora
- Modules: Rfid Hospital: Patient RegistrationDocumento1 paginaModules: Rfid Hospital: Patient RegistrationgingeevimalNessuna valutazione finora
- Sequence Diagram LoginDocumento3 pagineSequence Diagram LogingingeevimalNessuna valutazione finora
- ArchDocumento1 paginaArchgingeevimalNessuna valutazione finora
- Main Project Scrutiny CommiteeDocumento3 pagineMain Project Scrutiny CommiteegingeevimalNessuna valutazione finora
- AMM Screen ShotDocumento7 pagineAMM Screen ShotgingeevimalNessuna valutazione finora
- A Polynomial-Time Algorithm For Computing Disjoint Lightpaths Pairs in Minimumisolated-Failure-Immune WDM Optical NetworksDocumento5 pagineA Polynomial-Time Algorithm For Computing Disjoint Lightpaths Pairs in Minimumisolated-Failure-Immune WDM Optical NetworksgingeevimalNessuna valutazione finora
- Airline Reservation System Project Report inDocumento64 pagineAirline Reservation System Project Report ingingeevimal67% (9)
- AMM Screen ShotDocumento7 pagineAMM Screen ShotgingeevimalNessuna valutazione finora
- SubtitlesDocumento5 pagineSubtitlesSpeak1 2truthNessuna valutazione finora
- Bridging Machine Learning and Computer Network ResDocumento16 pagineBridging Machine Learning and Computer Network ResMaxwell AniakorNessuna valutazione finora
- Verification by Static Analysis: Intelligent Testing ConferenceDocumento13 pagineVerification by Static Analysis: Intelligent Testing ConferenceUpak OloNessuna valutazione finora
- The Network Configuration Operators GroupDocumento2 pagineThe Network Configuration Operators Groupferro4uNessuna valutazione finora
- Automated Ballot VoteDocumento13 pagineAutomated Ballot VoteRaju DantuluriNessuna valutazione finora
- Emu LogDocumento2 pagineEmu LogDan Do ThatNessuna valutazione finora
- EMCTL Commands For Management AgentDocumento8 pagineEMCTL Commands For Management AgentAlfredo TorresNessuna valutazione finora
- Consistency ModelsDocumento41 pagineConsistency ModelsGarin TianNessuna valutazione finora
- Project ReportDocumento48 pagineProject ReportRAUSHAN KUMAR RAUNIYARNessuna valutazione finora
- 31dsad PowtoonDocumento38 pagine31dsad PowtoonWaka KaNessuna valutazione finora
- How To Set Up A Scanner To Function Through An ICA Session With XenApp Twain Escaner CitrixDocumento8 pagineHow To Set Up A Scanner To Function Through An ICA Session With XenApp Twain Escaner CitrixdocuNessuna valutazione finora
- 3 41eDocumento2 pagine3 41esatarupaNessuna valutazione finora
- De La Salle Lipa: Web Developers in Batangas"Documento2 pagineDe La Salle Lipa: Web Developers in Batangas"Hannah Bea LindoNessuna valutazione finora
- IIMS College: Putalisadak, Kathmandu, NepalDocumento8 pagineIIMS College: Putalisadak, Kathmandu, Nepalzenesh shresthaNessuna valutazione finora
- Schindler Vs OtisDocumento1 paginaSchindler Vs OtisMark Goduco0% (1)
- Cam Renki Ölçüm Cihazı - ILIS CHROMADocumento16 pagineCam Renki Ölçüm Cihazı - ILIS CHROMALevent KazasNessuna valutazione finora
- JOVIAL (J73) Programming Language Tutorial (1982) AD-A142 780Documento194 pagineJOVIAL (J73) Programming Language Tutorial (1982) AD-A142 780Paul McGinnis100% (2)
- Patran Technics PDFDocumento93 paginePatran Technics PDFedggyNessuna valutazione finora
- N2810SERIES N4810 N4820U HDD SSD ListDocumento26 pagineN2810SERIES N4810 N4820U HDD SSD ListfoursoulNessuna valutazione finora
- Type of RecursionDocumento23 pagineType of RecursionYuyun JoeNessuna valutazione finora
- Jjeb Mock S6 Ict 1Documento11 pagineJjeb Mock S6 Ict 1amb roseNessuna valutazione finora
- Gender Differences in Emotional Expressiveness ADocumento18 pagineGender Differences in Emotional Expressiveness AAla'a Bani KhalefNessuna valutazione finora
- Xfinity NH Recruitment WorkbookDocumento7 pagineXfinity NH Recruitment Workbookmanuel FabianNessuna valutazione finora
- Embedded IOT 2018-19Documento8 pagineEmbedded IOT 2018-19Anonymous 1aqlkZNessuna valutazione finora
- Development of Church Information System (A Case Study Approach)Documento10 pagineDevelopment of Church Information System (A Case Study Approach)Eddy ManurungNessuna valutazione finora
- IT Security and SafetyDocumento11 pagineIT Security and SafetyRosy Gaby EstudilloNessuna valutazione finora
- Vaksin Anakku and MyVAS Guide For Schools JKN PahangDocumento26 pagineVaksin Anakku and MyVAS Guide For Schools JKN Pahangsmart designNessuna valutazione finora
- CCNA 200-301 Official Cert Guide, Volume 2: ISBN-10: 1-58714-713-0 ISBN-13: 978-1-58714-713-5Documento2 pagineCCNA 200-301 Official Cert Guide, Volume 2: ISBN-10: 1-58714-713-0 ISBN-13: 978-1-58714-713-5Monu ChouhanNessuna valutazione finora