Potrebbero piacerti anche
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDa EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeValutazione: 4 su 5 stelle4/5 (5794)
- The Yellow House: A Memoir (2019 National Book Award Winner)Da EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Valutazione: 4 su 5 stelle4/5 (98)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDa EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryValutazione: 3.5 su 5 stelle3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDa EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceValutazione: 4 su 5 stelle4/5 (895)
- The Little Book of Hygge: Danish Secrets to Happy LivingDa EverandThe Little Book of Hygge: Danish Secrets to Happy LivingValutazione: 3.5 su 5 stelle3.5/5 (400)
- Shoe Dog: A Memoir by the Creator of NikeDa EverandShoe Dog: A Memoir by the Creator of NikeValutazione: 4.5 su 5 stelle4.5/5 (537)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDa EverandNever Split the Difference: Negotiating As If Your Life Depended On ItValutazione: 4.5 su 5 stelle4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDa EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureValutazione: 4.5 su 5 stelle4.5/5 (474)
- Grit: The Power of Passion and PerseveranceDa EverandGrit: The Power of Passion and PerseveranceValutazione: 4 su 5 stelle4/5 (588)
- The Emperor of All Maladies: A Biography of CancerDa EverandThe Emperor of All Maladies: A Biography of CancerValutazione: 4.5 su 5 stelle4.5/5 (271)
- On Fire: The (Burning) Case for a Green New DealDa EverandOn Fire: The (Burning) Case for a Green New DealValutazione: 4 su 5 stelle4/5 (74)
- Team of Rivals: The Political Genius of Abraham LincolnDa EverandTeam of Rivals: The Political Genius of Abraham LincolnValutazione: 4.5 su 5 stelle4.5/5 (234)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDa EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaValutazione: 4.5 su 5 stelle4.5/5 (266)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDa EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersValutazione: 4.5 su 5 stelle4.5/5 (344)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDa EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyValutazione: 3.5 su 5 stelle3.5/5 (2259)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDa EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreValutazione: 4 su 5 stelle4/5 (1090)
- The Unwinding: An Inner History of the New AmericaDa EverandThe Unwinding: An Inner History of the New AmericaValutazione: 4 su 5 stelle4/5 (45)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Da EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Valutazione: 4.5 su 5 stelle4.5/5 (121)
- Her Body and Other Parties: StoriesDa EverandHer Body and Other Parties: StoriesValutazione: 4 su 5 stelle4/5 (821)
- Srs For Notice BoardDocumento12 pagineSrs For Notice BoardVipin Pokhriyal50% (2)
- VB Advantages and DisadvantagesDocumento5 pagineVB Advantages and Disadvantageslalitha75% (4)
- How To Configure The Windows Default User Profile - Apache VCL - Apache Software FoundationDocumento7 pagineHow To Configure The Windows Default User Profile - Apache VCL - Apache Software FoundationRafael Nery BritoNessuna valutazione finora
- D-Link Wireless VPN Router DI 824-VUP & GreenBow IPSec VPN Client Software ConfigurationDocumento14 pagineD-Link Wireless VPN Router DI 824-VUP & GreenBow IPSec VPN Client Software Configurationgreenbow100% (1)
- CL ProgDocumento482 pagineCL ProgSat's100% (8)
- 1 Stykz IntroDocumento34 pagine1 Stykz IntrolorenabaldonNessuna valutazione finora
- DAA UNIT 1 - FinalDocumento38 pagineDAA UNIT 1 - FinalkarthickamsecNessuna valutazione finora
- 3GB Memory For CATIA V5 Under Windows OS: Ulrich Biewer September 2003Documento8 pagine3GB Memory For CATIA V5 Under Windows OS: Ulrich Biewer September 2003Antoneta DhemboNessuna valutazione finora
- Problem 1.1 (I) Shortest Remaining TimeDocumento4 pagineProblem 1.1 (I) Shortest Remaining TimeThanhluu TrinhNessuna valutazione finora
- 12.1.1 BC9000 - BC9050 Controlador Terminal de Bus Ethernet EN PDFDocumento2 pagine12.1.1 BC9000 - BC9050 Controlador Terminal de Bus Ethernet EN PDFLuis AngelNessuna valutazione finora
- ORACLE PLSQL Mid Term Part 1 SOLUTIONSDocumento17 pagineORACLE PLSQL Mid Term Part 1 SOLUTIONScrispy_joyNessuna valutazione finora
- Java - Crossword - 01: Bhuvaneswaran B / Ap (SS) / Cse / RecDocumento2 pagineJava - Crossword - 01: Bhuvaneswaran B / Ap (SS) / Cse / RecbhuvangatesNessuna valutazione finora
- EAI2Documento276 pagineEAI2Chiranjeevi ChNessuna valutazione finora
- BMR Best PracticesDocumento4 pagineBMR Best PracticesLVy AbNessuna valutazione finora
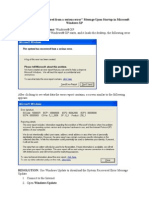
- The System Has Recovered From A Serious ErrorDocumento3 pagineThe System Has Recovered From A Serious Errorpuji_ascNessuna valutazione finora
- Electronic Data Processing: Advantages of Using EDPDocumento24 pagineElectronic Data Processing: Advantages of Using EDPRita Redoble EspirituNessuna valutazione finora
- Type of Public HolidaysDocumento7 pagineType of Public HolidaysBoban VasiljevicNessuna valutazione finora
- Verilog Prep MaterialDocumento11 pagineVerilog Prep MaterialSangeetha BajanthriNessuna valutazione finora
- Electronic Banking Fraud DetectionDocumento74 pagineElectronic Banking Fraud DetectionSusmita DhitalNessuna valutazione finora
- Scapy DocumentationDocumento63 pagineScapy Documentationpaolo the best(ia)Nessuna valutazione finora
- Mame Guide PDFDocumento222 pagineMame Guide PDFHelio Fernandes FariasNessuna valutazione finora
- AglDocumento86 pagineAglerikanathalie100% (1)
- Explain UNION and UNION ALL SQL Clause With ExampleDocumento8 pagineExplain UNION and UNION ALL SQL Clause With ExampleAawez AkhterNessuna valutazione finora
- PLP 26 PDFDocumento29 paginePLP 26 PDFdeepaklovesuNessuna valutazione finora
- IIB9Admin Chapter1 DemoVersion Installation HowtoDocumento30 pagineIIB9Admin Chapter1 DemoVersion Installation HowtoShivam GuptaNessuna valutazione finora
- Chapter 6 Programming in MatlabDocumento76 pagineChapter 6 Programming in MatlabKen LooNessuna valutazione finora
- IT Agile Project Manager Resume Example (FINRA) - Gaithersburg, MarylandDocumento5 pagineIT Agile Project Manager Resume Example (FINRA) - Gaithersburg, MarylandSanjay BoseNessuna valutazione finora
- Top 50 SAP Business Objects Data Services (BODS) Interview Questions With AnswersDocumento10 pagineTop 50 SAP Business Objects Data Services (BODS) Interview Questions With Answerssatishsapbiw100% (1)
- Accelerationg ANSYS Fluent Simulations With NVIDIA GPUs AA V9 I1 PDFDocumento3 pagineAccelerationg ANSYS Fluent Simulations With NVIDIA GPUs AA V9 I1 PDFZen KyoNessuna valutazione finora