Potrebbero piacerti anche
- AUTOSAR ARXML Using EEA COMDocumento13 pagineAUTOSAR ARXML Using EEA COMann mariaNessuna valutazione finora
- Daivakarunya NovenaDocumento10 pagineDaivakarunya Novenaann mariaNessuna valutazione finora
- Autosar Sws CandriverDocumento110 pagineAutosar Sws Candriverann mariaNessuna valutazione finora
- IP Address Hacking Prevention SystemDocumento3 pagineIP Address Hacking Prevention Systemann mariaNessuna valutazione finora
- Shoe Dog: A Memoir by the Creator of NikeDa EverandShoe Dog: A Memoir by the Creator of NikeValutazione: 4.5 su 5 stelle4.5/5 (537)
- The Yellow House: A Memoir (2019 National Book Award Winner)Da EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Valutazione: 4 su 5 stelle4/5 (98)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDa EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeValutazione: 4 su 5 stelle4/5 (5794)
- The Little Book of Hygge: Danish Secrets to Happy LivingDa EverandThe Little Book of Hygge: Danish Secrets to Happy LivingValutazione: 3.5 su 5 stelle3.5/5 (400)
- Grit: The Power of Passion and PerseveranceDa EverandGrit: The Power of Passion and PerseveranceValutazione: 4 su 5 stelle4/5 (588)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDa EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureValutazione: 4.5 su 5 stelle4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDa EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryValutazione: 3.5 su 5 stelle3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDa EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceValutazione: 4 su 5 stelle4/5 (895)
- Team of Rivals: The Political Genius of Abraham LincolnDa EverandTeam of Rivals: The Political Genius of Abraham LincolnValutazione: 4.5 su 5 stelle4.5/5 (234)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDa EverandNever Split the Difference: Negotiating As If Your Life Depended On ItValutazione: 4.5 su 5 stelle4.5/5 (838)
- The Emperor of All Maladies: A Biography of CancerDa EverandThe Emperor of All Maladies: A Biography of CancerValutazione: 4.5 su 5 stelle4.5/5 (271)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDa EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaValutazione: 4.5 su 5 stelle4.5/5 (266)
- On Fire: The (Burning) Case for a Green New DealDa EverandOn Fire: The (Burning) Case for a Green New DealValutazione: 4 su 5 stelle4/5 (74)
- The Unwinding: An Inner History of the New AmericaDa EverandThe Unwinding: An Inner History of the New AmericaValutazione: 4 su 5 stelle4/5 (45)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDa EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersValutazione: 4.5 su 5 stelle4.5/5 (345)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDa EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyValutazione: 3.5 su 5 stelle3.5/5 (2259)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDa EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreValutazione: 4 su 5 stelle4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Da EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Valutazione: 4.5 su 5 stelle4.5/5 (121)
- Her Body and Other Parties: StoriesDa EverandHer Body and Other Parties: StoriesValutazione: 4 su 5 stelle4/5 (821)
- TUTOR Implementation GuideDocumento160 pagineTUTOR Implementation GuideNidhi SaxenaNessuna valutazione finora
- Understanding End-To-End 5G Transport NetworksDocumento32 pagineUnderstanding End-To-End 5G Transport NetworksTrịnhVạnPhướcNessuna valutazione finora
- Vtiger InstallationDocumento2 pagineVtiger InstallationShubhranshu Shekhar DwivediNessuna valutazione finora
- WWW - Syng: Create by ARIJIT DEDocumento1 paginaWWW - Syng: Create by ARIJIT DEAshish KumarNessuna valutazione finora
- Axioo Diagnostic Flowcharts Guidance V.1.0Documento5 pagineAxioo Diagnostic Flowcharts Guidance V.1.0St khofifahNessuna valutazione finora
- Innovus Help and TipsDocumento8 pagineInnovus Help and Tipsvibhash kumarNessuna valutazione finora
- Ashish - Kotecha - Project Report of Captain PadDocumento71 pagineAshish - Kotecha - Project Report of Captain PadAshish KotechaNessuna valutazione finora
- Word Exercise 6 - Editing and Spell CheckDocumento4 pagineWord Exercise 6 - Editing and Spell CheckenggmohanNessuna valutazione finora
- Database Gateway Websphere MQ Installation and Users GuideDocumento123 pagineDatabase Gateway Websphere MQ Installation and Users GuideNikolya SmirnoffNessuna valutazione finora
- 12 Tips To Use Your Japanese IME Better - NihonshockDocumento14 pagine12 Tips To Use Your Japanese IME Better - NihonshockHuy RathanaNessuna valutazione finora
- EN Specification Sheet VEGAPULS 31 Two Wire 4 20 Ma HARTDocumento3 pagineEN Specification Sheet VEGAPULS 31 Two Wire 4 20 Ma HARTJose JohnNessuna valutazione finora
- Siddhant BansalDocumento1 paginaSiddhant BansalSiddhant BansalNessuna valutazione finora
- Smart Restaurant Menu Ordering SystemDocumento27 pagineSmart Restaurant Menu Ordering SystemŚowmyà ŚrìNessuna valutazione finora
- Major Models Used in SDLCDocumento14 pagineMajor Models Used in SDLCbobbydebNessuna valutazione finora
- How To Upgrade Firmware For LOM (Lights Out Management) - Dave On SecurityDocumento5 pagineHow To Upgrade Firmware For LOM (Lights Out Management) - Dave On Securitymartinhache2014Nessuna valutazione finora
- 02 - Data Center - LongDocumento9 pagine02 - Data Center - LongAdnan HaiderNessuna valutazione finora
- Hacking Talk With Trishneet Arora PaperbackDocumento4 pagineHacking Talk With Trishneet Arora Paperbackaw8040% (5)
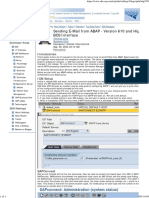
- Sending E-Mail From ABAP - Version 610 and Higher - BCS InterfaceDocumento1 paginaSending E-Mail From ABAP - Version 610 and Higher - BCS Interfacekrishnan_rajesh5740Nessuna valutazione finora
- TEMS LearningsDocumento12 pagineTEMS LearningsAugustin DasNessuna valutazione finora
- How To Customize Odoo Erp To Meet Your Business NeedsDocumento1 paginaHow To Customize Odoo Erp To Meet Your Business NeedsSravanNessuna valutazione finora
- COSC 101 Computer LiteracyDocumento4 pagineCOSC 101 Computer Literacypandorabox.y2kNessuna valutazione finora
- Ict Notes 4,5,6 Pre UpdateDocumento19 pagineIct Notes 4,5,6 Pre UpdateAtif Mehmood100% (1)
- AWP Question BankDocumento3 pagineAWP Question BankNitya JaniNessuna valutazione finora
- UD22321B Baseline User-Manual-of-NVR V4.30.210 20201208Documento96 pagineUD22321B Baseline User-Manual-of-NVR V4.30.210 20201208Mahmoud AhmedNessuna valutazione finora
- Active Directory Enumeration Attacks Module Cheat Sheet HTBDocumento34 pagineActive Directory Enumeration Attacks Module Cheat Sheet HTBLucas LuqueNessuna valutazione finora
- Diagnostics Tool User GuideDocumento15 pagineDiagnostics Tool User GuideDennis ManNessuna valutazione finora
- DSBDa MCQDocumento17 pagineDSBDa MCQnoxexNessuna valutazione finora
- Medal Log 20231201Documento22 pagineMedal Log 20231201MarcNessuna valutazione finora
- MorphoManager 15.4.3Documento5 pagineMorphoManager 15.4.3camilo angelNessuna valutazione finora
- Gartner Magic Quadrant For Mobile ApplicationDocumento34 pagineGartner Magic Quadrant For Mobile ApplicationCarlos Rojas RNessuna valutazione finora