Potrebbero piacerti anche
- Statistical Decision TheoryDocumento164 pagineStatistical Decision TheoryLam JamNessuna valutazione finora
- Decision MakingDocumento32 pagineDecision MakingLight GreatNessuna valutazione finora
- Section 1: Normal Form Games and Strategic Reasoning: 1.1.1 What We've Done So FarDocumento6 pagineSection 1: Normal Form Games and Strategic Reasoning: 1.1.1 What We've Done So FarEric HeNessuna valutazione finora
- 6-Testing&conf Intervals PDFDocumento43 pagine6-Testing&conf Intervals PDFKevin HyunNessuna valutazione finora
- Section 1.2: Probability and DecisionsDocumento54 pagineSection 1.2: Probability and DecisionsZiex SitzNessuna valutazione finora
- BBA - 2nd - Sem - 215-Busines Statistics - FinalDocumento175 pagineBBA - 2nd - Sem - 215-Busines Statistics - FinalNeha GuptaNessuna valutazione finora
- BBA - 2nd - Sem - 215-Busines Statistics - Final PDFDocumento175 pagineBBA - 2nd - Sem - 215-Busines Statistics - Final PDFNeha GuptaNessuna valutazione finora
- BBA - 2nd - Sem - 215-Busines Statistics - Final PDFDocumento175 pagineBBA - 2nd - Sem - 215-Busines Statistics - Final PDFNeha GuptaNessuna valutazione finora
- Lecture I-II: Motivation and Decision Theory - Markus M. MÄobiusDocumento9 pagineLecture I-II: Motivation and Decision Theory - Markus M. MÄobiuskuchbhirandomNessuna valutazione finora
- Exam 2021 With SolutionsDocumento6 pagineExam 2021 With SolutionsAnushree JainNessuna valutazione finora
- Introduction To Game Theory Markus Mobius HarvardDocumento176 pagineIntroduction To Game Theory Markus Mobius Harvardjameswen627100% (2)
- Groebner Business Statistics 7 Ch05Documento39 pagineGroebner Business Statistics 7 Ch05Zeeshan RiazNessuna valutazione finora
- Introduction To Game Theory (Harvard) PDFDocumento167 pagineIntroduction To Game Theory (Harvard) PDFAndresMartinez28Nessuna valutazione finora
- Ablan, Arjay I. Other Examples of Quantitative Models For Decision Making SimulationDocumento13 pagineAblan, Arjay I. Other Examples of Quantitative Models For Decision Making SimulationVJ CarbonellNessuna valutazione finora
- Time Series Smoothing in ExcelDocumento11 pagineTime Series Smoothing in ExcelNumXL ProNessuna valutazione finora
- In Order To Implement A Set of Rules / Tutorialoutlet Dot ComDocumento42 pagineIn Order To Implement A Set of Rules / Tutorialoutlet Dot Comjorge0050Nessuna valutazione finora
- Simple and Multiple Regression AnalysisDocumento48 pagineSimple and Multiple Regression AnalysisUmair Khan NiaziNessuna valutazione finora
- Mental Accounting 2Documento28 pagineMental Accounting 2Alvaro pensado fernandezNessuna valutazione finora
- Quantitative Analysis and Business Decisions: Decision Making Under RiskDocumento4 pagineQuantitative Analysis and Business Decisions: Decision Making Under RiskSiva Prasad PasupuletiNessuna valutazione finora
- Probability MITDocumento116 pagineProbability MITMinh Quan LENessuna valutazione finora
- Lecture 1Documento23 pagineLecture 1Ehsan jafariNessuna valutazione finora
- Decision Tree TutorialDocumento8 pagineDecision Tree TutorialДхиа ЕддинеNessuna valutazione finora
- Sukvin BBMP1103 May2022Documento13 pagineSukvin BBMP1103 May2022Cikgu SupianNessuna valutazione finora
- MIT18 05S14 ReadingsDocumento291 pagineMIT18 05S14 ReadingspucalerroneNessuna valutazione finora
- Applied Statistical Methodology For Research BusinessDocumento12 pagineApplied Statistical Methodology For Research BusinessgeofreyNessuna valutazione finora
- ABU Buad 837 SummaryDocumento14 pagineABU Buad 837 SummaryAdetunji TaiwoNessuna valutazione finora
- Chapter 6 The Statistical ToolsDocumento38 pagineChapter 6 The Statistical ToolsAllyssa Faye PartosaNessuna valutazione finora
- Decision Tree12Documento20 pagineDecision Tree12Shrutika BhosaleNessuna valutazione finora
- Stat Reviewer 1Documento61 pagineStat Reviewer 1Moises CalastravoNessuna valutazione finora
- Lecture Notes - Decision TreeDocumento13 pagineLecture Notes - Decision Treesamrat141988Nessuna valutazione finora
- Transitive Regret: Theoretical EconomicsDocumento14 pagineTransitive Regret: Theoretical EconomicsInder MohanNessuna valutazione finora
- Mit18 05 s22 ProbabilityDocumento112 pagineMit18 05 s22 ProbabilityMuhammad RafayNessuna valutazione finora
- Basic RegressionDocumento14 pagineBasic RegressionAlem AyahuNessuna valutazione finora
- Statistics For EconomicsDocumento214 pagineStatistics For EconomicsKulbir SinghNessuna valutazione finora
- Algebra: Average of An AverageDocumento9 pagineAlgebra: Average of An AverageHuseini MohammedNessuna valutazione finora
- (Economics Collection) Shahdad Naghshpour - Statistics For Economics-Business Expert Press (2012) PDFDocumento214 pagine(Economics Collection) Shahdad Naghshpour - Statistics For Economics-Business Expert Press (2012) PDFShreya MondalNessuna valutazione finora
- Game Theory Thesis PDFDocumento7 pagineGame Theory Thesis PDFstephaniekingmanchester100% (1)
- Trading Strategies From Technical Analysis - 6Documento19 pagineTrading Strategies From Technical Analysis - 6GEorge StassanNessuna valutazione finora
- Ch10 Experimental Design Statistical Analysis of DataDocumento38 pagineCh10 Experimental Design Statistical Analysis of DataAriza Cisnero DelacruzNessuna valutazione finora
- 2009 Metrics Solutions 9 Ec1126 PDFDocumento3 pagine2009 Metrics Solutions 9 Ec1126 PDFADITYANessuna valutazione finora
- Prospect TheoryDocumento4 pagineProspect TheoryTamanna RathNessuna valutazione finora
- Lect Notes 1Documento91 pagineLect Notes 1Safis HajjouzNessuna valutazione finora
- Numerical Methods CollardDocumento431 pagineNumerical Methods CollardSafis HajjouzNessuna valutazione finora
- Decision Making Under Uncertainty - NextDocumento16 pagineDecision Making Under Uncertainty - NextkniqaNessuna valutazione finora
- Statistical Analysis: Dr. Shahid Iqbal Fall 2021Documento65 pagineStatistical Analysis: Dr. Shahid Iqbal Fall 2021Wasif AbbasiNessuna valutazione finora
- Introduction To Hypothesis Testing: Breakthrough Management GroupDocumento28 pagineIntroduction To Hypothesis Testing: Breakthrough Management GroupvyerramallaNessuna valutazione finora
- Mean, Variance, and SDDocumento19 pagineMean, Variance, and SDMICHELLE CASTRONessuna valutazione finora
- Potential Outcomes FrameworkDocumento7 paginePotential Outcomes FrameworkStanislao Maldonado100% (1)
- Bachelor Thesis Game TheoryDocumento4 pagineBachelor Thesis Game Theorynlcnqrgld100% (2)
- Stat Ess Mod 3 Ses 1Documento29 pagineStat Ess Mod 3 Ses 1Akila100% (1)
- Mtid 321 W4Documento18 pagineMtid 321 W4Zhen WeiNessuna valutazione finora
- Principal Agent NotesDocumento19 paginePrincipal Agent Notessamiyah.haque01Nessuna valutazione finora
- Module 1 Lecture 3Documento6 pagineModule 1 Lecture 3Swapan Kumar SahaNessuna valutazione finora
- Summary of Decision TheoryDocumento15 pagineSummary of Decision TheoryEngr Evans OhajiNessuna valutazione finora
- Cross Sectional DataDocumento4 pagineCross Sectional DataChasNessuna valutazione finora
- Assignment No. 02 Introduction To Educational Statistics (8614)Documento19 pagineAssignment No. 02 Introduction To Educational Statistics (8614)somiNessuna valutazione finora
- Game TheoryDocumento155 pagineGame TheoryAnand Kr100% (1)
- The Practically Cheating Statistics Handbook, The Sequel! (2nd Edition)Da EverandThe Practically Cheating Statistics Handbook, The Sequel! (2nd Edition)Valutazione: 4.5 su 5 stelle4.5/5 (3)
- Guidelines For Installing A Rainwater Collection and Utilization SystemDocumento41 pagineGuidelines For Installing A Rainwater Collection and Utilization SystemSiva Shali100% (2)
- Report On Rainwater Harvesting and UsageDocumento66 pagineReport On Rainwater Harvesting and Usageexlimit218Nessuna valutazione finora
- Plant II - Course Details 201801Documento2 paginePlant II - Course Details 201801exlimit218Nessuna valutazione finora
- Circuit Theory Fundamental Practise QuestionsDocumento4 pagineCircuit Theory Fundamental Practise Questionsexlimit218Nessuna valutazione finora
- Water Temperature Vs Cold Water Flow Rate With Fixed Hot Water Flow Rate at 3LPMDocumento3 pagineWater Temperature Vs Cold Water Flow Rate With Fixed Hot Water Flow Rate at 3LPMexlimit218Nessuna valutazione finora
- Chemistry For EngineeringDocumento3 pagineChemistry For Engineeringexlimit218Nessuna valutazione finora
- XRD Brief ExplanationDocumento1 paginaXRD Brief Explanationexlimit218Nessuna valutazione finora
- Appendix ADocumento13 pagineAppendix Aexlimit218Nessuna valutazione finora
- Explanation of Q4b in Tutorial Sheet No. 3Documento1 paginaExplanation of Q4b in Tutorial Sheet No. 3exlimit218Nessuna valutazione finora
- Geometric Properties of Line and Area ElementsDocumento2 pagineGeometric Properties of Line and Area Elementsexlimit218100% (1)
- Performance CH 33Documento54 paginePerformance CH 33Yasichalew sefinehNessuna valutazione finora
- Manual Safety Relays 3SK2 en-USDocumento352 pagineManual Safety Relays 3SK2 en-USKarina Ospina100% (3)
- SAP ABAP ResumeDocumento3 pagineSAP ABAP Resumeshakti1392821Nessuna valutazione finora
- Sap BarcodesDocumento59 pagineSap BarcodesDarmin MemiševićNessuna valutazione finora
- Altair EngineeringDocumento11 pagineAltair EngineeringKarthikNessuna valutazione finora
- NAD Factory Default and Software CheckDocumento13 pagineNAD Factory Default and Software CheckNorma FloresNessuna valutazione finora
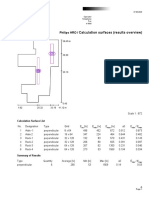
- Calculation Surfaces (Results Overview) : Philips HRODocumento4 pagineCalculation Surfaces (Results Overview) : Philips HROsanaNessuna valutazione finora
- Est-Pergola Octogonal 21-03-2022Documento1 paginaEst-Pergola Octogonal 21-03-2022Victor MuñozNessuna valutazione finora
- Transport ModellingDocumento37 pagineTransport ModellingRiza Atiq Abdullah Rahmat100% (6)
- Unit Standards and Competencies Diagram: Performance StandardDocumento11 pagineUnit Standards and Competencies Diagram: Performance Standarddanica baguiNessuna valutazione finora
- Task 3.a-WordDocumento22 pagineTask 3.a-WordVenkata jahnavi PunatiNessuna valutazione finora
- Vatufeku Longman Writing Academic English Xufex PDFDocumento4 pagineVatufeku Longman Writing Academic English Xufex PDFNZAR AREFNessuna valutazione finora
- ABB SWBD VD4 Brochure PDFDocumento6 pagineABB SWBD VD4 Brochure PDFanand_girgaonkarNessuna valutazione finora
- Harden's Spices Model For Biochemistry in Medical CurriculumDocumento10 pagineHarden's Spices Model For Biochemistry in Medical CurriculumGlobal Research and Development Services100% (1)
- Oscilloscope Lab Manual11Documento16 pagineOscilloscope Lab Manual11DM RafiunNessuna valutazione finora
- 06 NetNumen U31 System DescriptionDocumento39 pagine06 NetNumen U31 System Descriptionمحيي الدين الكميشى100% (1)
- T8000 Type2 USER MANUAL - 47501358-A0 EN 2016-6-1Documento10 pagineT8000 Type2 USER MANUAL - 47501358-A0 EN 2016-6-1AerdiaNessuna valutazione finora
- Unit-I Introduction To Erp Enterprise Resource Planning (ERP) Is An Integrated Computer-Based SystemDocumento51 pagineUnit-I Introduction To Erp Enterprise Resource Planning (ERP) Is An Integrated Computer-Based Systemchandru5g100% (4)
- Pawan Kumar Dubey: ProfileDocumento4 paginePawan Kumar Dubey: Profilepawandubey9Nessuna valutazione finora
- Municipality of AloguinsanDocumento5 pagineMunicipality of AloguinsanLady Mae BrigoliNessuna valutazione finora
- Renderoc RsxtraDocumento4 pagineRenderoc RsxtraBalasubramanian AnanthNessuna valutazione finora
- Duty Engineer: Grand Mercure & Ibis Yogyakarta Adi SuciptoDocumento1 paginaDuty Engineer: Grand Mercure & Ibis Yogyakarta Adi Suciptoali maulana yuthiaNessuna valutazione finora
- Profile Measurement Full ReportDocumento16 pagineProfile Measurement Full ReportAman RedhaNessuna valutazione finora
- Automatic Transmission: Models FA and FB With Allison AT542Documento22 pagineAutomatic Transmission: Models FA and FB With Allison AT542nguyenxuanvinhv3Nessuna valutazione finora
- Cu Ext 2015Documento4 pagineCu Ext 2015mohammedzuluNessuna valutazione finora
- Barrett Light 50Documento23 pagineBarrett Light 50Zayd Iskandar Dzolkarnain Al-HadramiNessuna valutazione finora
- Opamp 5Documento42 pagineOpamp 5Ann RazonNessuna valutazione finora
- Tkinter GUI Programming by ExampleDocumento374 pagineTkinter GUI Programming by ExampleArphan Desoja100% (5)
- 90 61 085 Transportation ValvesDocumento18 pagine90 61 085 Transportation ValvesarrikanNessuna valutazione finora
- Maintenance and Repair Instructions TM 124/11: Spring-Applied Sliding Caliper Brake FSG110 With Hub CenteringDocumento11 pagineMaintenance and Repair Instructions TM 124/11: Spring-Applied Sliding Caliper Brake FSG110 With Hub CenteringNik100% (1)