Potrebbero piacerti anche
- Shoe Dog: A Memoir by the Creator of NikeDa EverandShoe Dog: A Memoir by the Creator of NikeValutazione: 4.5 su 5 stelle4.5/5 (537)
- 1830 Photonic Vr70 Cert EngDocumento12 pagine1830 Photonic Vr70 Cert Engsrotenstein3114Nessuna valutazione finora
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDa EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeValutazione: 4 su 5 stelle4/5 (5794)
- Validated FIPS 140-1 and FIPS 140-2 Cryptographic ModulesDocumento85 pagineValidated FIPS 140-1 and FIPS 140-2 Cryptographic Modulessrotenstein3114Nessuna valutazione finora
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDa EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceValutazione: 4 su 5 stelle4/5 (895)
- Optical Encryption: First Line of Defense For Network ServicesDocumento32 pagineOptical Encryption: First Line of Defense For Network Servicessrotenstein3114Nessuna valutazione finora
- The Yellow House: A Memoir (2019 National Book Award Winner)Da EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Valutazione: 4 su 5 stelle4/5 (98)
- 1830 Photonic vr70 Eval Eng PDFDocumento1 pagina1830 Photonic vr70 Eval Eng PDFsrotenstein3114Nessuna valutazione finora
- Grit: The Power of Passion and PerseveranceDa EverandGrit: The Power of Passion and PerseveranceValutazione: 4 su 5 stelle4/5 (588)
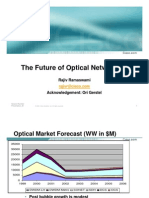
- Optical Communications Market Research Company, News & ReportsDocumento2 pagineOptical Communications Market Research Company, News & Reportssrotenstein3114Nessuna valutazione finora
- The Little Book of Hygge: Danish Secrets to Happy LivingDa EverandThe Little Book of Hygge: Danish Secrets to Happy LivingValutazione: 3.5 su 5 stelle3.5/5 (400)
- Reference Guide OTNDocumento60 pagineReference Guide OTNjoaquic100% (1)
- The Emperor of All Maladies: A Biography of CancerDa EverandThe Emperor of All Maladies: A Biography of CancerValutazione: 4.5 su 5 stelle4.5/5 (271)
- Adtran - Packet Optical 2.0 - Supporting Video and Gigabit ServicesDocumento36 pagineAdtran - Packet Optical 2.0 - Supporting Video and Gigabit Servicessrotenstein3114Nessuna valutazione finora
- Never Split the Difference: Negotiating As If Your Life Depended On ItDa EverandNever Split the Difference: Negotiating As If Your Life Depended On ItValutazione: 4.5 su 5 stelle4.5/5 (838)
- Cisco The Future of OT - March 2012Documento14 pagineCisco The Future of OT - March 2012srotenstein3114Nessuna valutazione finora
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDa EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyValutazione: 3.5 su 5 stelle3.5/5 (2259)
- 100G Client Interface Evolution: Guylain Barlow JDSU Network & Service EnablementDocumento31 pagine100G Client Interface Evolution: Guylain Barlow JDSU Network & Service Enablementsrotenstein3114Nessuna valutazione finora
- On Fire: The (Burning) Case for a Green New DealDa EverandOn Fire: The (Burning) Case for a Green New DealValutazione: 4 su 5 stelle4/5 (74)
- Ciena Encryptor ManualDocumento46 pagineCiena Encryptor Manualsrotenstein3114Nessuna valutazione finora
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDa EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureValutazione: 4.5 su 5 stelle4.5/5 (474)
- Chapter9 Wavelength Routing Optical NetworksDocumento150 pagineChapter9 Wavelength Routing Optical Networkssrotenstein3114Nessuna valutazione finora
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDa EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryValutazione: 3.5 su 5 stelle3.5/5 (231)
- ASON GMPLS Optical Control Plane TutorialDocumento162 pagineASON GMPLS Optical Control Plane Tutorialsrotenstein3114100% (1)
- Team of Rivals: The Political Genius of Abraham LincolnDa EverandTeam of Rivals: The Political Genius of Abraham LincolnValutazione: 4.5 su 5 stelle4.5/5 (234)
- Emerging Optical Transport Technology and Architecture: Suhas MansinghDocumento12 pagineEmerging Optical Transport Technology and Architecture: Suhas Mansinghsrotenstein3114Nessuna valutazione finora
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDa EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaValutazione: 4.5 su 5 stelle4.5/5 (266)
- DWDM Technologie Pro Trasnportni Site I B PDFDocumento39 pagineDWDM Technologie Pro Trasnportni Site I B PDFWalter FloresNessuna valutazione finora
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDa EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersValutazione: 4.5 su 5 stelle4.5/5 (345)
- David Welch in Finer ADocumento27 pagineDavid Welch in Finer Asrotenstein3114Nessuna valutazione finora
- Astn/Ason and Gmpls Overview and Comparison: By, Kishore Kasi Udayashankar Kaveriappa Muddiyada KDocumento44 pagineAstn/Ason and Gmpls Overview and Comparison: By, Kishore Kasi Udayashankar Kaveriappa Muddiyada Ksrotenstein3114Nessuna valutazione finora
- The Unwinding: An Inner History of the New AmericaDa EverandThe Unwinding: An Inner History of the New AmericaValutazione: 4 su 5 stelle4/5 (45)
- TTM 1: Access and Core Networks, Advanced: "Optical Access and Transport Networks"Documento16 pagineTTM 1: Access and Core Networks, Advanced: "Optical Access and Transport Networks"srotenstein3114Nessuna valutazione finora
- Adva Cloud Computing FinalDocumento3 pagineAdva Cloud Computing Finalsrotenstein3114Nessuna valutazione finora
- Volcanic SoilsDocumento14 pagineVolcanic SoilsVictor Hugo BarbosaNessuna valutazione finora
- FORM Module IpsDocumento10 pagineFORM Module IpsRizalNessuna valutazione finora
- Tom Rockmore - Hegel's Circular EpistemologyDocumento213 pagineTom Rockmore - Hegel's Circular Epistemologyluiz100% (1)
- Module 11 Activity Based CostingDocumento13 pagineModule 11 Activity Based CostingMarjorie NepomucenoNessuna valutazione finora
- STRESS HealthDocumento40 pagineSTRESS HealthHajra KhanNessuna valutazione finora
- Electrostatics Practice ProblemsDocumento4 pagineElectrostatics Practice ProblemsMohammed Aftab AhmedNessuna valutazione finora
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDa EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreValutazione: 4 su 5 stelle4/5 (1090)
- Ip TunnelingDocumento15 pagineIp TunnelingBon Tran HongNessuna valutazione finora
- Learning Activity No.2Documento1 paginaLearning Activity No.2Miki AntonNessuna valutazione finora
- Adolescents and Career DevelopmentDocumento10 pagineAdolescents and Career DevelopmentMasrijah MasirNessuna valutazione finora
- Data Abstraction and Problem Solving With C Walls and Mirrors 6th Edition Carrano Solutions ManualDocumento36 pagineData Abstraction and Problem Solving With C Walls and Mirrors 6th Edition Carrano Solutions Manualallocaturnonylgvtt100% (12)
- Enable Modern Authentication in Exchange OnlineDocumento2 pagineEnable Modern Authentication in Exchange Onlinedan.artimon2791Nessuna valutazione finora
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Da EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Valutazione: 4.5 su 5 stelle4.5/5 (121)
- Directorate of Technical Education, Maharashtra StateDocumento47 pagineDirectorate of Technical Education, Maharashtra StatePandurang GunjalNessuna valutazione finora
- AA-SM-010 Stress Due To Interference Fit Bushing Installation - Rev BDocumento3 pagineAA-SM-010 Stress Due To Interference Fit Bushing Installation - Rev BMaicon PiontcoskiNessuna valutazione finora
- Detailed Lesson Plan (DLP) Format: Learning Competency/iesDocumento1 paginaDetailed Lesson Plan (DLP) Format: Learning Competency/iesErma JalemNessuna valutazione finora
- Omega 900 InstructionsDocumento27 pagineOmega 900 InstructionsRA Dental LaboratoryNessuna valutazione finora
- DbmsDocumento5 pagineDbmsRohit KushwahaNessuna valutazione finora
- Masters Thesis Benyam 2011Documento156 pagineMasters Thesis Benyam 2011TechBoy65Nessuna valutazione finora
- Discover India, January 2018Documento51 pagineDiscover India, January 2018calebfriesenNessuna valutazione finora
- Her Body and Other Parties: StoriesDa EverandHer Body and Other Parties: StoriesValutazione: 4 su 5 stelle4/5 (821)
- Resume LittletonDocumento1 paginaResume Littletonapi-309466005Nessuna valutazione finora
- The Roti Canai StoryDocumento5 pagineThe Roti Canai StoryDr Bugs TanNessuna valutazione finora
- Differentiating Language Difference and Language Disorder - Information For Teachers Working With English Language Learners in The Schools PDFDocumento23 pagineDifferentiating Language Difference and Language Disorder - Information For Teachers Working With English Language Learners in The Schools PDFIqra HassanNessuna valutazione finora
- Roles of Community Health NursingDocumento2 pagineRoles of Community Health Nursingdy kimNessuna valutazione finora
- Et Iso 12543 4 2011Documento16 pagineEt Iso 12543 4 2011freddyguzman3471Nessuna valutazione finora
- Norman K. Denzin - The Cinematic Society - The Voyeur's Gaze (1995) PDFDocumento584 pagineNorman K. Denzin - The Cinematic Society - The Voyeur's Gaze (1995) PDFjuan guerra0% (1)
- Text Descriptive Tentang HewanDocumento15 pagineText Descriptive Tentang HewanHAPPY ARIFIANTONessuna valutazione finora
- Management Accounting/Series-4-2011 (Code3024)Documento18 pagineManagement Accounting/Series-4-2011 (Code3024)Hein Linn Kyaw100% (2)
- DesignDocumento402 pagineDesignEduard BoleaNessuna valutazione finora
- This Study Resource Was: MCV4U Exam ReviewDocumento9 pagineThis Study Resource Was: MCV4U Exam ReviewNathan WaltonNessuna valutazione finora
- Soal PTS Vii BigDocumento6 pagineSoal PTS Vii Bigdimas awe100% (1)
- Self-Actualization in Robert Luketic'S: Legally Blonde: A HumanisticDocumento10 pagineSelf-Actualization in Robert Luketic'S: Legally Blonde: A HumanisticAyeshia FréyNessuna valutazione finora
- iPhone 14 Guide for Seniors: Unlocking Seamless Simplicity for the Golden Generation with Step-by-Step ScreenshotsDa EverandiPhone 14 Guide for Seniors: Unlocking Seamless Simplicity for the Golden Generation with Step-by-Step ScreenshotsValutazione: 5 su 5 stelle5/5 (4)
- Chip War: The Fight for the World's Most Critical TechnologyDa EverandChip War: The Fight for the World's Most Critical TechnologyValutazione: 4.5 su 5 stelle4.5/5 (82)