Potrebbero piacerti anche
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDa EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeValutazione: 4 su 5 stelle4/5 (5794)
- 2 - New Title & New PaperDocumento5 pagine2 - New Title & New PaperNagabhushanamDonthineniNessuna valutazione finora
- The Little Book of Hygge: Danish Secrets to Happy LivingDa EverandThe Little Book of Hygge: Danish Secrets to Happy LivingValutazione: 3.5 su 5 stelle3.5/5 (399)
- V4i6 0126 PDFDocumento3 pagineV4i6 0126 PDFNagabhushanamDonthineniNessuna valutazione finora
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDa EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryValutazione: 3.5 su 5 stelle3.5/5 (231)
- LSJ1360 Anomaly Detection Via Online OversamplingDocumento5 pagineLSJ1360 Anomaly Detection Via Online OversamplingNagabhushanamDonthineniNessuna valutazione finora
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDa EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceValutazione: 4 su 5 stelle4/5 (894)
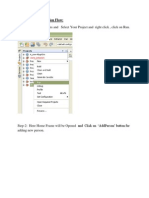
- Procedure For Execution FlowDocumento8 pagineProcedure For Execution FlowNagabhushanamDonthineniNessuna valutazione finora
- The Yellow House: A Memoir (2019 National Book Award Winner)Da EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Valutazione: 4 su 5 stelle4/5 (98)
- Ford Motor Credit Company343 PDFDocumento100 pagineFord Motor Credit Company343 PDFNagabhushanamDonthineniNessuna valutazione finora
- Shoe Dog: A Memoir by the Creator of NikeDa EverandShoe Dog: A Memoir by the Creator of NikeValutazione: 4.5 su 5 stelle4.5/5 (537)
- Smart Screen Layout For Knowledge EvaluationDocumento10 pagineSmart Screen Layout For Knowledge EvaluationNagabhushanamDonthineniNessuna valutazione finora
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDa EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureValutazione: 4.5 su 5 stelle4.5/5 (474)
- Credit Finances For Fortune Ford Company Review of LiteratureDocumento1 paginaCredit Finances For Fortune Ford Company Review of LiteratureNagabhushanamDonthineniNessuna valutazione finora
- Never Split the Difference: Negotiating As If Your Life Depended On ItDa EverandNever Split the Difference: Negotiating As If Your Life Depended On ItValutazione: 4.5 su 5 stelle4.5/5 (838)
- Project 3 Chapters GuidelinesDocumento5 pagineProject 3 Chapters GuidelinesNagabhushanamDonthineniNessuna valutazione finora
- Grit: The Power of Passion and PerseveranceDa EverandGrit: The Power of Passion and PerseveranceValutazione: 4 su 5 stelle4/5 (587)
- Sentiment Analysis (SCREEN SHOTS)Documento5 pagineSentiment Analysis (SCREEN SHOTS)NagabhushanamDonthineniNessuna valutazione finora
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDa EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaValutazione: 4.5 su 5 stelle4.5/5 (265)
- OwnerDocumento5 pagineOwnerNagabhushanamDonthineniNessuna valutazione finora
- Neighbor PositionsDocumento6 pagineNeighbor PositionsNagabhushanamDonthineniNessuna valutazione finora
- A Better Techinque To Identify User Avilability in OSNDocumento1 paginaA Better Techinque To Identify User Avilability in OSNNagabhushanamDonthineniNessuna valutazione finora
- The Emperor of All Maladies: A Biography of CancerDa EverandThe Emperor of All Maladies: A Biography of CancerValutazione: 4.5 su 5 stelle4.5/5 (271)
- Class DiagramDocumento4 pagineClass DiagramNagabhushanamDonthineniNessuna valutazione finora
- On Fire: The (Burning) Case for a Green New DealDa EverandOn Fire: The (Burning) Case for a Green New DealValutazione: 4 su 5 stelle4/5 (73)
- Class DiagramDocumento4 pagineClass DiagramNagabhushanamDonthineniNessuna valutazione finora
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDa EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersValutazione: 4.5 su 5 stelle4.5/5 (344)
- LGE 2010 4Q SeparateDocumento273 pagineLGE 2010 4Q SeparateNagabhushanamDonthineniNessuna valutazione finora
- Team of Rivals: The Political Genius of Abraham LincolnDa EverandTeam of Rivals: The Political Genius of Abraham LincolnValutazione: 4.5 su 5 stelle4.5/5 (234)
- Company Profile: Red FMDocumento5 pagineCompany Profile: Red FMNagabhushanamDonthineniNessuna valutazione finora
- Hyundai Snaps Up Prestigious Motor Trader AwardsDocumento3 pagineHyundai Snaps Up Prestigious Motor Trader AwardsNagabhushanamDonthineniNessuna valutazione finora
- Customer Satisfaction and Needs Assessment StudiesDocumento12 pagineCustomer Satisfaction and Needs Assessment StudiesArul BalajiNessuna valutazione finora
- Customer Satisfaction and Needs Assessment StudiesDocumento12 pagineCustomer Satisfaction and Needs Assessment StudiesArul BalajiNessuna valutazione finora
- 10 Appendix RS Means Assemblies Cost EstimationDocumento12 pagine10 Appendix RS Means Assemblies Cost Estimationshahbazi.amir15Nessuna valutazione finora
- The Unwinding: An Inner History of the New AmericaDa EverandThe Unwinding: An Inner History of the New AmericaValutazione: 4 su 5 stelle4/5 (45)
- Cantilever Retaining Wall AnalysisDocumento7 pagineCantilever Retaining Wall AnalysisChub BokingoNessuna valutazione finora
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDa EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyValutazione: 3.5 su 5 stelle3.5/5 (2219)
- Farmers InterviewDocumento5 pagineFarmers Interviewjay jariwalaNessuna valutazione finora
- Huawei 9000aDocumento27 pagineHuawei 9000aAristideKonanNessuna valutazione finora
- Ultrasonic Examination of Heavy Steel Forgings: Standard Practice ForDocumento7 pagineUltrasonic Examination of Heavy Steel Forgings: Standard Practice ForbatataNessuna valutazione finora
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDa EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreValutazione: 4 su 5 stelle4/5 (1090)
- The Essence of Success - Earl NightingaleDocumento2 pagineThe Essence of Success - Earl NightingaleDegrace Ns40% (15)
- United States Court of Appeals, Third CircuitDocumento3 pagineUnited States Court of Appeals, Third CircuitScribd Government DocsNessuna valutazione finora
- Converting An XML File With Many Hierarchy Levels To ABAP FormatDocumento8 pagineConverting An XML File With Many Hierarchy Levels To ABAP FormatGisele Cristina Betencourt de OliveiraNessuna valutazione finora
- Mosaic Maker - Instructions PDFDocumento4 pagineMosaic Maker - Instructions PDFRoderickHenryNessuna valutazione finora
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Da EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Valutazione: 4.5 su 5 stelle4.5/5 (119)
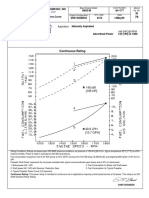
- fr1177e-MOTOR CUMMINS 195HPDocumento2 paginefr1177e-MOTOR CUMMINS 195HPwilfredo rodriguezNessuna valutazione finora
- Factory Hygiene ProcedureDocumento5 pagineFactory Hygiene ProcedureGsr MurthyNessuna valutazione finora
- StrutsDocumento7 pagineStrutsBatrisyialya RusliNessuna valutazione finora
- Amended ComplaintDocumento38 pagineAmended ComplaintDeadspinNessuna valutazione finora
- RoboticsDocumento2 pagineRoboticsCharice AlfaroNessuna valutazione finora
- Storage Reservior and Balancing ReservoirDocumento19 pagineStorage Reservior and Balancing ReservoirNeel Kurrey0% (1)
- S4H - 885 How To Approach Fit To Standard Analysis - S4HANA CloudDocumento16 pagineS4H - 885 How To Approach Fit To Standard Analysis - S4HANA Cloudwai waiNessuna valutazione finora
- HPE Alletra 6000-PSN1013540188USENDocumento4 pagineHPE Alletra 6000-PSN1013540188USENMauricio Pérez CortésNessuna valutazione finora
- GSM Multi-Mode Feature DescriptionDocumento39 pagineGSM Multi-Mode Feature DescriptionDiyas KazhiyevNessuna valutazione finora
- Chi Square LessonDocumento11 pagineChi Square LessonKaia HamadaNessuna valutazione finora
- Czar Alexander IIDocumento11 pagineCzar Alexander IIMalachy ChinweokwuNessuna valutazione finora
- C - Official Coast HandbookDocumento15 pagineC - Official Coast HandbookSofia FreundNessuna valutazione finora
- Her Body and Other Parties: StoriesDa EverandHer Body and Other Parties: StoriesValutazione: 4 su 5 stelle4/5 (821)
- Curriculum Vitae 2010Documento11 pagineCurriculum Vitae 2010ajombileNessuna valutazione finora
- Difference Between Knowledge and SkillDocumento2 pagineDifference Between Knowledge and SkilljmNessuna valutazione finora
- Role Played by Digitalization During Pandemic: A Journey of Digital India Via Digital PaymentDocumento11 pagineRole Played by Digitalization During Pandemic: A Journey of Digital India Via Digital PaymentIAEME PublicationNessuna valutazione finora
- Philippines Taxation Scope and ReformsDocumento4 paginePhilippines Taxation Scope and ReformsAngie Olpos Boreros BaritugoNessuna valutazione finora
- CMTD42M FDocumento3 pagineCMTD42M FagengfirstyanNessuna valutazione finora
- Activate Adobe Photoshop CS5 Free Using Serial KeyDocumento3 pagineActivate Adobe Photoshop CS5 Free Using Serial KeyLukmanto68% (28)
- A Dream Takes FlightDocumento3 pagineA Dream Takes FlightHafiq AmsyarNessuna valutazione finora
- Road Safety GOs & CircularsDocumento39 pagineRoad Safety GOs & CircularsVizag Roads100% (1)
- QDA Miner 3.2 (With WordStat & Simstat)Documento6 pagineQDA Miner 3.2 (With WordStat & Simstat)ztanga7@yahoo.comNessuna valutazione finora
- ChatGPT Side Hustles 2024 - Unlock the Digital Goldmine and Get AI Working for You Fast with More Than 85 Side Hustle Ideas to Boost Passive Income, Create New Cash Flow, and Get Ahead of the CurveDa EverandChatGPT Side Hustles 2024 - Unlock the Digital Goldmine and Get AI Working for You Fast with More Than 85 Side Hustle Ideas to Boost Passive Income, Create New Cash Flow, and Get Ahead of the CurveNessuna valutazione finora
- ChatGPT Millionaire 2024 - Bot-Driven Side Hustles, Prompt Engineering Shortcut Secrets, and Automated Income Streams that Print Money While You Sleep. The Ultimate Beginner’s Guide for AI BusinessDa EverandChatGPT Millionaire 2024 - Bot-Driven Side Hustles, Prompt Engineering Shortcut Secrets, and Automated Income Streams that Print Money While You Sleep. The Ultimate Beginner’s Guide for AI BusinessNessuna valutazione finora
- Change Management for Beginners: Understanding Change Processes and Actively Shaping ThemDa EverandChange Management for Beginners: Understanding Change Processes and Actively Shaping ThemValutazione: 4.5 su 5 stelle4.5/5 (3)