Potrebbero piacerti anche
- Shoe Dog: A Memoir by the Creator of NikeDa EverandShoe Dog: A Memoir by the Creator of NikeValutazione: 4.5 su 5 stelle4.5/5 (537)
- The Yellow House: A Memoir (2019 National Book Award Winner)Da EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Valutazione: 4 su 5 stelle4/5 (98)
- Data Model and DescriptionDocumento1 paginaData Model and DescriptionVinod TheteNessuna valutazione finora
- Comment Evaluation Using Mutual Method, LSTM, Bootstrap and Co-Occurrence Word in Lecture QuestionnaireDocumento7 pagineComment Evaluation Using Mutual Method, LSTM, Bootstrap and Co-Occurrence Word in Lecture QuestionnaireVinod TheteNessuna valutazione finora
- Vidi: Virtual Director of Video Lectures: Marco FuriniDocumento4 pagineVidi: Virtual Director of Video Lectures: Marco FuriniVinod TheteNessuna valutazione finora
- Design An Eye Tracking Mouse: Minal Nehete, Madhuri Lokhande, Kranti AhireDocumento4 pagineDesign An Eye Tracking Mouse: Minal Nehete, Madhuri Lokhande, Kranti AhireVinod TheteNessuna valutazione finora
- FinalfaceDocumento19 pagineFinalfaceVinod TheteNessuna valutazione finora
- Data Design 1 Internal Software Data StructureDocumento1 paginaData Design 1 Internal Software Data StructureVinod TheteNessuna valutazione finora
- Privacy Data Flow DiagramsDocumento6 paginePrivacy Data Flow DiagramsVinod TheteNessuna valutazione finora
- A Robust Region-Adaptive Dual Image Watermarking TechniqueDocumento1 paginaA Robust Region-Adaptive Dual Image Watermarking TechniqueVinod TheteNessuna valutazione finora
- Uml SynopsisDocumento9 pagineUml SynopsisVinod TheteNessuna valutazione finora
- Robust Watermarking Scheme Against Multiple AttacksDocumento7 pagineRobust Watermarking Scheme Against Multiple AttacksVinod TheteNessuna valutazione finora
- Online C, C++, Java Compiler Using Cloud Computing - A SurveyDocumento6 pagineOnline C, C++, Java Compiler Using Cloud Computing - A SurveyVinod TheteNessuna valutazione finora
- Android Suburban Railway Ticketing With GPS As Ticket CheckerDocumento4 pagineAndroid Suburban Railway Ticketing With GPS As Ticket CheckerVinod TheteNessuna valutazione finora
- Abstract:: Networks and Lots of People Using Them As Per Their Own Needs, in Such Scenarios We HaveDocumento4 pagineAbstract:: Networks and Lots of People Using Them As Per Their Own Needs, in Such Scenarios We HaveVinod TheteNessuna valutazione finora
- Blob Detection PDFDocumento6 pagineBlob Detection PDFVinod TheteNessuna valutazione finora
- Programming: Introduction To C++Documento15 pagineProgramming: Introduction To C++Vinod TheteNessuna valutazione finora
- System Architecture Challenges in The Home M2M Network: Michael Starsinic, Member IEEEDocumento7 pagineSystem Architecture Challenges in The Home M2M Network: Michael Starsinic, Member IEEEVinod TheteNessuna valutazione finora
- Gbus - Route Geotracer: AbstractDocumento1 paginaGbus - Route Geotracer: AbstractVinod TheteNessuna valutazione finora
- Smart Lab Using Saas TechnologyDocumento4 pagineSmart Lab Using Saas TechnologyVinod TheteNessuna valutazione finora
- Data Security Using Armstrong Numbers 1Documento4 pagineData Security Using Armstrong Numbers 1Vinod TheteNessuna valutazione finora
- Android Suburban Railway Ticketing With GPS As Ticket CheckerDocumento4 pagineAndroid Suburban Railway Ticketing With GPS As Ticket CheckerVinod TheteNessuna valutazione finora
- 2013 Ieee PaperDocumento5 pagine2013 Ieee PaperVinod TheteNessuna valutazione finora
- Smart Lab Using Saas TechnologyDocumento3 pagineSmart Lab Using Saas TechnologyVinod TheteNessuna valutazione finora
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDa EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeValutazione: 4 su 5 stelle4/5 (5794)
- The Little Book of Hygge: Danish Secrets to Happy LivingDa EverandThe Little Book of Hygge: Danish Secrets to Happy LivingValutazione: 3.5 su 5 stelle3.5/5 (400)
- Grit: The Power of Passion and PerseveranceDa EverandGrit: The Power of Passion and PerseveranceValutazione: 4 su 5 stelle4/5 (588)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDa EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureValutazione: 4.5 su 5 stelle4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDa EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryValutazione: 3.5 su 5 stelle3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDa EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceValutazione: 4 su 5 stelle4/5 (895)
- Team of Rivals: The Political Genius of Abraham LincolnDa EverandTeam of Rivals: The Political Genius of Abraham LincolnValutazione: 4.5 su 5 stelle4.5/5 (234)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDa EverandNever Split the Difference: Negotiating As If Your Life Depended On ItValutazione: 4.5 su 5 stelle4.5/5 (838)
- The Emperor of All Maladies: A Biography of CancerDa EverandThe Emperor of All Maladies: A Biography of CancerValutazione: 4.5 su 5 stelle4.5/5 (271)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDa EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaValutazione: 4.5 su 5 stelle4.5/5 (266)
- On Fire: The (Burning) Case for a Green New DealDa EverandOn Fire: The (Burning) Case for a Green New DealValutazione: 4 su 5 stelle4/5 (74)
- The Unwinding: An Inner History of the New AmericaDa EverandThe Unwinding: An Inner History of the New AmericaValutazione: 4 su 5 stelle4/5 (45)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDa EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersValutazione: 4.5 su 5 stelle4.5/5 (345)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDa EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyValutazione: 3.5 su 5 stelle3.5/5 (2259)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDa EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreValutazione: 4 su 5 stelle4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Da EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Valutazione: 4.5 su 5 stelle4.5/5 (121)
- Her Body and Other Parties: StoriesDa EverandHer Body and Other Parties: StoriesValutazione: 4 su 5 stelle4/5 (821)
- Assignm 3Documento3 pagineAssignm 3Luis Bellido C.Nessuna valutazione finora
- Stripe-Based Fragility Analysis of Multispan Concrete Bridge Classes Using Machine Learning TechniquesDocumento19 pagineStripe-Based Fragility Analysis of Multispan Concrete Bridge Classes Using Machine Learning TechniquesEmby BinoeNessuna valutazione finora
- Bandy - How To Build An Effective Trading SystemDocumento113 pagineBandy - How To Build An Effective Trading Systemderekhcw168100% (3)
- Cross Validation LN 12Documento11 pagineCross Validation LN 12M S PrasadNessuna valutazione finora
- Machine Learning: An Applied Econometric Approach: Sendhil Mullainathan and Jann SpiessDocumento38 pagineMachine Learning: An Applied Econometric Approach: Sendhil Mullainathan and Jann Spiessabdul salamNessuna valutazione finora
- Case Study - Flight DelayDocumento8 pagineCase Study - Flight DelayHarshit AroraNessuna valutazione finora
- MaliDocumento39 pagineMaliPavuluri MalleswariNessuna valutazione finora
- Data Science Interview QuestionsDocumento55 pagineData Science Interview QuestionsArunachalam Narayanan100% (2)
- Data Mining: Practical Machine Learning Tools and TechniquesDocumento73 pagineData Mining: Practical Machine Learning Tools and TechniquesArvindNessuna valutazione finora
- ModEco ManualDocumento44 pagineModEco Manualfriderikos100% (1)
- Data Science Course SyllabusDocumento37 pagineData Science Course SyllabusFabulousMaxxNessuna valutazione finora
- Sensors: Assessment of Mental, Emotional and Physical Stress Through Analysis of Physiological Signals Using SmartphonesDocumento21 pagineSensors: Assessment of Mental, Emotional and Physical Stress Through Analysis of Physiological Signals Using SmartphonesfebriNessuna valutazione finora
- R Package RecommendationDocumento4 pagineR Package RecommendationinoddyNessuna valutazione finora
- DW&M Unit 3 Part IDocumento101 pagineDW&M Unit 3 Part IUT DUNessuna valutazione finora
- Ni Laterite Mineralogy and Chemistry - A New Approach To Quantifi CationDocumento8 pagineNi Laterite Mineralogy and Chemistry - A New Approach To Quantifi CationAldoNessuna valutazione finora
- ML Tutorial Con EjemplosDocumento236 pagineML Tutorial Con EjemplosMiguel M SanchezNessuna valutazione finora
- Project Report 2022Documento27 pagineProject Report 2022Yogita PalNessuna valutazione finora
- Samatrix Assignment3Documento4 pagineSamatrix Assignment3Yash KumarNessuna valutazione finora
- CART v6.0Documento434 pagineCART v6.0segorin2Nessuna valutazione finora
- Lab ManualDocumento46 pagineLab ManualAnkur SinghNessuna valutazione finora
- Waste Management: Sama Azadi, Ayoub Karimi-JashniDocumento10 pagineWaste Management: Sama Azadi, Ayoub Karimi-JashnihawNessuna valutazione finora
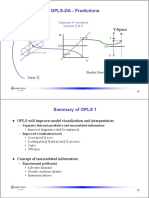
- OPLS-DA - Predictions: X-Space Y-Space U yDocumento44 pagineOPLS-DA - Predictions: X-Space Y-Space U yhomeNessuna valutazione finora
- Ijreas Volume 2, Issue 1 (January 2012) ISSN: 2249-3905 Indian Stock Market Trend Prediction Using Support Vector MachineDocumento19 pagineIjreas Volume 2, Issue 1 (January 2012) ISSN: 2249-3905 Indian Stock Market Trend Prediction Using Support Vector MachineRishi MaheshwariNessuna valutazione finora
- Kerntune: Self-Tuning Linux Kernel Performance Using Support Vector MachinesDocumento98 pagineKerntune: Self-Tuning Linux Kernel Performance Using Support Vector MachinesChinarNessuna valutazione finora
- ECR 2022 ProgrammeDocumento1.126 pagineECR 2022 ProgrammejbmbritoNessuna valutazione finora
- (Hedge Et Al. 2015) Using Trees, Bagging, and Random Forest To Predict ROP During DrillingDocumento12 pagine(Hedge Et Al. 2015) Using Trees, Bagging, and Random Forest To Predict ROP During DrillingKleberson CarvalhoNessuna valutazione finora
- Amit Kumar: Bigmart Sales Prediction A Project ReportDocumento47 pagineAmit Kumar: Bigmart Sales Prediction A Project ReportAmit KumarNessuna valutazione finora
- Towards Data Based Corrosion Analysis of Concrete With Supervised Machine LearningDocumento8 pagineTowards Data Based Corrosion Analysis of Concrete With Supervised Machine LearningEman SalehNessuna valutazione finora
- Artificial Intelligence-Based Lead Propensity PredictionDocumento10 pagineArtificial Intelligence-Based Lead Propensity PredictionIAES IJAINessuna valutazione finora
- 9 Intelligent Crop Recommendation System Using Machine LearningDocumento6 pagine9 Intelligent Crop Recommendation System Using Machine LearningBalasatyaappaji99 KurellaNessuna valutazione finora