Potrebbero piacerti anche
- Multicore Software Development Techniques: Applications, Tips, and TricksDa EverandMulticore Software Development Techniques: Applications, Tips, and TricksValutazione: 2.5 su 5 stelle2.5/5 (2)
- ParallelDBs PDFDocumento23 pagineParallelDBs PDFheyramzzNessuna valutazione finora
- Parallel Query1Documento33 pagineParallel Query1KIRUTHIKA KNessuna valutazione finora
- Introduction To DBMSDocumento37 pagineIntroduction To DBMSKIRUTHIKA KNessuna valutazione finora
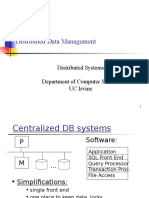
- ADBMS Parallel and Distributed DatabasesDocumento98 pagineADBMS Parallel and Distributed DatabasesTulipNessuna valutazione finora
- Parallelisation CommentDocumento3 pagineParallelisation CommentPrajwal AradhyaNessuna valutazione finora
- Enterprise Systems: Distributed Databases and Systems - DT211 4Documento25 pagineEnterprise Systems: Distributed Databases and Systems - DT211 4Stef ShiNessuna valutazione finora
- Aws (S3, Iam, Ec2, Emr and Redshift)Documento16 pagineAws (S3, Iam, Ec2, Emr and Redshift)AkashRai100% (1)
- Parallel DatabasesDocumento19 pagineParallel DatabasesPrem KumarNessuna valutazione finora
- Impala Presentation - Orlando PDFDocumento60 pagineImpala Presentation - Orlando PDFVinkeyChenNessuna valutazione finora
- Bigtable: A Distributed Storage System For Structured DataDocumento23 pagineBigtable: A Distributed Storage System For Structured DataPetter PNessuna valutazione finora
- Parallel Hashing: John Erol EvangelistaDocumento42 pagineParallel Hashing: John Erol EvangelistaJohn Erol EvangelistaNessuna valutazione finora
- AdbmsDocumento70 pagineAdbmsvarunendraNessuna valutazione finora
- Lecture 1 Parallel DatabasesDocumento30 pagineLecture 1 Parallel DatabasesKumkumo Kussia KossaNessuna valutazione finora
- Programação Paralela e DistribuídaDocumento39 pagineProgramação Paralela e DistribuídaMarcelo AzevedoNessuna valutazione finora
- Lecture 4 Network Topologies For Parallel ArchitectureDocumento34 pagineLecture 4 Network Topologies For Parallel Architecturenimranoor137Nessuna valutazione finora
- Big Data Storage ConceptsDocumento31 pagineBig Data Storage ConceptsraghdoooshNessuna valutazione finora
- Unit No.4 Parallel DatabaseDocumento32 pagineUnit No.4 Parallel DatabasePadre BhojNessuna valutazione finora
- Explicitly Parallel PlatformsDocumento90 pagineExplicitly Parallel PlatformswmanjonjoNessuna valutazione finora
- Introduction To Map ReduceDocumento50 pagineIntroduction To Map ReduceKhAn ZainabNessuna valutazione finora
- Parallel ProcessingDocumento35 pagineParallel ProcessingGetu GeneneNessuna valutazione finora
- 25 - Map Reduce RecapDocumento12 pagine25 - Map Reduce RecapgpswainNessuna valutazione finora
- Parallel Computing in CFD: Milovan PerićDocumento25 pagineParallel Computing in CFD: Milovan PerićMohamed OudaNessuna valutazione finora
- Technical Seminar Report On: "High Performance Computing"Documento14 pagineTechnical Seminar Report On: "High Performance Computing"mit_thakkar_2Nessuna valutazione finora
- HPC Lectures 1 5Documento18 pagineHPC Lectures 1 5mohamed samyNessuna valutazione finora
- Parallel Computation Models: Slide 1Documento28 pagineParallel Computation Models: Slide 1jyotiNessuna valutazione finora
- Lecture 5Documento72 pagineLecture 5Lets clear Jee mathsNessuna valutazione finora
- Lecture 2Documento19 pagineLecture 2HasnainNessuna valutazione finora
- Parallel and Distributed ComputingDocumento90 pagineParallel and Distributed ComputingWell WisherNessuna valutazione finora
- The Earth Simulator: Presented by Jin Soon Lim For CS 566Documento29 pagineThe Earth Simulator: Presented by Jin Soon Lim For CS 566swapnanshahNessuna valutazione finora
- Unit 1Documento25 pagineUnit 1rishisharma4201Nessuna valutazione finora
- DDB SlidesDocumento67 pagineDDB SlidesyNessuna valutazione finora
- Parallel, Cluster and Grid Computing: by P.S.Dhekne, BARC Dhekne@barc - Gov.inDocumento92 pagineParallel, Cluster and Grid Computing: by P.S.Dhekne, BARC Dhekne@barc - Gov.inMohamed TallmanNessuna valutazione finora
- Infrastructure of Data Warehouse: Ms. Ashwini Rao Asst - Prof.ITDocumento32 pagineInfrastructure of Data Warehouse: Ms. Ashwini Rao Asst - Prof.ITTanushree ShenviNessuna valutazione finora
- Parallel Programming Platforms (Part 1) : CSE3057Y Parallel and Distributed SystemsDocumento38 pagineParallel Programming Platforms (Part 1) : CSE3057Y Parallel and Distributed SystemssplokbovNessuna valutazione finora
- Parallel Computing: Overview: John Urbanic Urbanic@psc - EduDocumento34 pagineParallel Computing: Overview: John Urbanic Urbanic@psc - EduanjnasharmaNessuna valutazione finora
- Week 02Documento115 pagineWeek 02muhammad shoaibNessuna valutazione finora
- Slide 4Documento41 pagineSlide 4dejenedagime999Nessuna valutazione finora
- DBT Unit3 PDFDocumento94 pagineDBT Unit3 PDFChaitanya MadhavNessuna valutazione finora
- Parallel DFS and BFSDocumento35 pagineParallel DFS and BFSGeeta MeenaNessuna valutazione finora
- Lecture 1 - Parallel and Distributed ComputingDocumento25 pagineLecture 1 - Parallel and Distributed ComputingSibgha IsrarNessuna valutazione finora
- Applications of Data StructuresDocumento21 pagineApplications of Data StructuresshameenNessuna valutazione finora
- Slide 4Documento41 pagineSlide 4dejenedagime999Nessuna valutazione finora
- COA UNIT-III Parallel ProcessorsDocumento51 pagineCOA UNIT-III Parallel ProcessorsDevika csbsNessuna valutazione finora
- Networks of Workstations: (Distributed Memory)Documento19 pagineNetworks of Workstations: (Distributed Memory)aliha ghaffarNessuna valutazione finora
- Unit 6 Advanced DatabasesDocumento108 pagineUnit 6 Advanced DatabasesOmkarNessuna valutazione finora
- 26 Distributed Dbms NosqlDocumento45 pagine26 Distributed Dbms NosqlJam MuslimNessuna valutazione finora
- Distributed SystemDocumento26 pagineDistributed SystemSMARTELLIGENT100% (1)
- BCS 413 - Lecture5 - Replication - ConsistencyDocumento25 pagineBCS 413 - Lecture5 - Replication - ConsistencyDesmond KampoeNessuna valutazione finora
- UNIX Memory ManagementDocumento35 pagineUNIX Memory ManagementTech_MX100% (1)
- Overview of Parallel Computing: Shawn T. BrownDocumento46 pagineOverview of Parallel Computing: Shawn T. BrownKarthik KusumaNessuna valutazione finora
- CassandraTraining v3.3.4Documento183 pagineCassandraTraining v3.3.4Ratika Miglani Malhotra100% (1)
- Introduction To Parallel Processing: Unit-2Documento32 pagineIntroduction To Parallel Processing: Unit-2sushil@irdNessuna valutazione finora
- Parallel Arch 2Documento9 pagineParallel Arch 2manishbhardwaj8131Nessuna valutazione finora
- Introduction To Parallel ProcessingDocumento29 pagineIntroduction To Parallel ProcessingAzri Mohd KhanilNessuna valutazione finora
- Map Reduce: Simplified Processing On Large ClustersDocumento29 pagineMap Reduce: Simplified Processing On Large ClustersJoy BagdiNessuna valutazione finora
- 5 4 ParallelDocumento47 pagine5 4 ParallelUday ShubhrajNessuna valutazione finora
- Distributed Shared MemoryDocumento109 pagineDistributed Shared MemoryTulipNessuna valutazione finora
- Lecture 3 Flynn's Classical TaxonomyDocumento29 pagineLecture 3 Flynn's Classical Taxonomynimranoor137Nessuna valutazione finora
- Sistem Operasi 10Documento43 pagineSistem Operasi 10renggaslbonNessuna valutazione finora
- Introduction To Software Verification and Validation: SEI Curriculum Module SEI-CM-13-1.1 December 1988Documento25 pagineIntroduction To Software Verification and Validation: SEI Curriculum Module SEI-CM-13-1.1 December 1988Sid_6071100% (4)
- India General Knowledge 2013 For Competitive ExamsDocumento184 pagineIndia General Knowledge 2013 For Competitive Examsaekalaivan12100% (1)
- AMCAT Sample PaperDocumento14 pagineAMCAT Sample PaperHima Chandu KakiNessuna valutazione finora
- 2Documento16 pagine2Yosep HaryantoNessuna valutazione finora
- (James D. Foley, Andries Van Dam, Steven K. FeinerDocumento56 pagine(James D. Foley, Andries Van Dam, Steven K. FeinerDibas SilNessuna valutazione finora
- India General Knowledge 2013 For Competitive ExamsDocumento184 pagineIndia General Knowledge 2013 For Competitive Examsaekalaivan12100% (1)
- Advanced Database Techniques-FDocumento114 pagineAdvanced Database Techniques-Fsneha555Nessuna valutazione finora
- Oracle D2KDocumento8 pagineOracle D2KDibas SilNessuna valutazione finora
- The Boss Came To DinnerDocumento3 pagineThe Boss Came To DinnerDibas Sil100% (1)
- Lexicalanalyzer 110809102402 Phpapp02Documento79 pagineLexicalanalyzer 110809102402 Phpapp02Dibas SilNessuna valutazione finora
- S Q L - NotesDocumento25 pagineS Q L - Noteskumars_ddd78% (9)
- Lecture 03Documento20 pagineLecture 03Dibas SilNessuna valutazione finora
- DepartmentDocumento1 paginaDepartmentDibas SilNessuna valutazione finora
- MCQ m14Documento3 pagineMCQ m14gnanendra_eeeNessuna valutazione finora
- PG BrochureDocumento2 paginePG BrochuremeetalexNessuna valutazione finora
- I. Matching Type. Write Letters Only. (10pts) : Adamson University Computer Literacy 2 Prelim ExamDocumento2 pagineI. Matching Type. Write Letters Only. (10pts) : Adamson University Computer Literacy 2 Prelim ExamFerrolinoLouieNessuna valutazione finora
- Luigi Cherubini Requiem in C MinorDocumento8 pagineLuigi Cherubini Requiem in C MinorBen RutjesNessuna valutazione finora
- Portfolio Sandwich Game Lesson PlanDocumento2 paginePortfolio Sandwich Game Lesson Planapi-252005239Nessuna valutazione finora
- PDF RR Grade Sep ProjectsDocumento46 paginePDF RR Grade Sep ProjectsjunqiangdongNessuna valutazione finora
- LOMA FLMI CoursesDocumento4 pagineLOMA FLMI CoursesCeleste Joy C. LinsanganNessuna valutazione finora
- ASM NetworkingDocumento36 pagineASM NetworkingQuan TranNessuna valutazione finora
- Goodman Aula 1 e 2Documento17 pagineGoodman Aula 1 e 2Danilo TetNessuna valutazione finora
- Adore You - PDFDocumento290 pagineAdore You - PDFnbac0dNessuna valutazione finora
- Skin Care Creams, Lotions and Gels For Cosmetic Use - SpecificationDocumento33 pagineSkin Care Creams, Lotions and Gels For Cosmetic Use - SpecificationJona Phie Montero NdtcnursingNessuna valutazione finora
- Grade 10 LP Thin LensDocumento6 pagineGrade 10 LP Thin LensBrena PearlNessuna valutazione finora
- Mineral Claim Purchase and Sale Agreement FinalDocumento5 pagineMineral Claim Purchase and Sale Agreement Finaldaks4uNessuna valutazione finora
- Series R: 3 Piece Ball Valves With Integrated Handle DN8 - DN50 Butt Weld, Threaded, Socket Weld and Flanged VersionDocumento2 pagineSeries R: 3 Piece Ball Valves With Integrated Handle DN8 - DN50 Butt Weld, Threaded, Socket Weld and Flanged VersionАртем КосовNessuna valutazione finora
- Making Sense of The Future of Libraries: Dan Dorner, Jennifer Campbell-Meier and Iva SetoDocumento14 pagineMaking Sense of The Future of Libraries: Dan Dorner, Jennifer Campbell-Meier and Iva SetoBiblioteca IICENessuna valutazione finora
- Ram BookDocumento52 pagineRam BookRobson FletcherNessuna valutazione finora
- Shape It! SB 1Documento13 pagineShape It! SB 1Ass of Fire50% (6)
- Dimitris Achlioptas Ucsc Bsoe Baskin School of EngineeringDocumento22 pagineDimitris Achlioptas Ucsc Bsoe Baskin School of EngineeringUCSC Students100% (1)
- Consumer Price SummaryDocumento5 pagineConsumer Price SummaryKJ HiramotoNessuna valutazione finora
- Engineering Economics1Documento64 pagineEngineering Economics1bala saiNessuna valutazione finora
- Corporate Governance Guidelines GMDocumento15 pagineCorporate Governance Guidelines GMWaqas MahmoodNessuna valutazione finora
- Consumer PresentationDocumento30 pagineConsumer PresentationShafiqur Rahman KhanNessuna valutazione finora
- Belimo ARB24-SR Datasheet En-UsDocumento2 pagineBelimo ARB24-SR Datasheet En-Usian_gushepiNessuna valutazione finora
- 04 - Crystallogaphy III Miller Indices-Faces-Forms-EditedDocumento63 pagine04 - Crystallogaphy III Miller Indices-Faces-Forms-EditedMaisha MujibNessuna valutazione finora
- Week 1 Lab #2 - Microscopy & Microscopic Examination of Living MicroorganismsDocumento53 pagineWeek 1 Lab #2 - Microscopy & Microscopic Examination of Living MicroorganismsNgoc PhamNessuna valutazione finora
- ECDIS Presentation Library 4Documento16 pagineECDIS Presentation Library 4Orlando QuevedoNessuna valutazione finora
- (Guide) Supercharger V6 For Everyone, Make Your Phone Faster - Xda-DevelopersDocumento7 pagine(Guide) Supercharger V6 For Everyone, Make Your Phone Faster - Xda-Developersmantubabu6374Nessuna valutazione finora
- France 10-Day ItineraryDocumento3 pagineFrance 10-Day ItineraryYou goabroadNessuna valutazione finora
- Rated Operational Current: InstructionsDocumento12 pagineRated Operational Current: InstructionsJhon SanabriaNessuna valutazione finora
- 11 Stem P - Group 2 - CPT First GradingDocumento7 pagine11 Stem P - Group 2 - CPT First GradingZwen Zyronne Norico LumiwesNessuna valutazione finora
- Fabrication Daily Progress: No DescriptionDocumento4 pagineFabrication Daily Progress: No DescriptionAris PurniawanNessuna valutazione finora
- 2062 TSSR Site Sharing - Rev02Documento44 pagine2062 TSSR Site Sharing - Rev02Rio DefragNessuna valutazione finora