Potrebbero piacerti anche
- Factor Analysis (FA)Documento61 pagineFactor Analysis (FA)SomyaVermaNessuna valutazione finora
- Quality of Work LifeDocumento1 paginaQuality of Work LifeIndranil SarkarNessuna valutazione finora
- Factorial DesignDocumento4 pagineFactorial DesignPatriciaIvanaAbiogNessuna valutazione finora
- Marketing Notes: Consumer BehaviourDocumento7 pagineMarketing Notes: Consumer BehaviourPriya SrinivasanNessuna valutazione finora
- An Introduction To Factor Analysis: Philip HylandDocumento34 pagineAn Introduction To Factor Analysis: Philip HylandAtiqah NizamNessuna valutazione finora
- Effect of Capital Structure, Size and Profitability on Mining Firm ValueDocumento18 pagineEffect of Capital Structure, Size and Profitability on Mining Firm Valuerahmat fajarNessuna valutazione finora
- Factor Analysis - SpssDocumento15 pagineFactor Analysis - Spssmanjunatha tNessuna valutazione finora
- Business Enviornment: PREPARED BY:alokvyas SemDocumento15 pagineBusiness Enviornment: PREPARED BY:alokvyas SemAlok VyasNessuna valutazione finora
- Consumer Behavior Towards Ayurvedic ProductsDocumento5 pagineConsumer Behavior Towards Ayurvedic ProductsVikrant AryaNessuna valutazione finora
- Factor Analysis T. RamayahDocumento29 pagineFactor Analysis T. RamayahAmir AlazhariyNessuna valutazione finora
- Type and TraitDocumento12 pagineType and TraitSajid AnsariNessuna valutazione finora
- Case - Kumar Soft Drink Bottling Company: Marketing Analytics Dr. Kalim KhanDocumento1 paginaCase - Kumar Soft Drink Bottling Company: Marketing Analytics Dr. Kalim KhanDipinderNessuna valutazione finora
- Macroeconomic Analysis and Policies PDFDocumento3 pagineMacroeconomic Analysis and Policies PDFRKNessuna valutazione finora
- First-mover advantage mechanismsDocumento8 pagineFirst-mover advantage mechanismsHabib EjazNessuna valutazione finora
- 10 PPT Factorial DesignDocumento20 pagine10 PPT Factorial Designavijitf100% (2)
- Macroeconomics: National Income AccountingDocumento10 pagineMacroeconomics: National Income AccountingPARUL SINGH MBA 2019-21 (Delhi)Nessuna valutazione finora
- Factor Analysis of Labor Policies in EU CountriesDocumento5 pagineFactor Analysis of Labor Policies in EU CountriesaidaNessuna valutazione finora
- 1915105-Organisational Behaviour PDFDocumento13 pagine1915105-Organisational Behaviour PDFThirumal AzhaganNessuna valutazione finora
- Analysing Consumer MarketDocumento24 pagineAnalysing Consumer Marketabhi4u.kumarNessuna valutazione finora
- The key is to look at multiple measures over time to understand productivity trends and changes in operations that may be driving improvements. No single measure tells the full storyDocumento27 pagineThe key is to look at multiple measures over time to understand productivity trends and changes in operations that may be driving improvements. No single measure tells the full storySaloni BishnoiNessuna valutazione finora
- Organizational Development Interventions for Improving ProductivityDocumento1 paginaOrganizational Development Interventions for Improving ProductivityAaron Wallace0% (1)
- Factor & Cluster Analysis ExplainedDocumento14 pagineFactor & Cluster Analysis Explainedbodhraj91Nessuna valutazione finora
- Locus of Control and Its Influence On Health Related Help Seeking Behavior in NepalDocumento8 pagineLocus of Control and Its Influence On Health Related Help Seeking Behavior in NepalDristy GurungNessuna valutazione finora
- 2 Puffery-in-AdvertisementDocumento9 pagine2 Puffery-in-AdvertisementHarmeet KaurNessuna valutazione finora
- Factor AnalysisDocumento11 pagineFactor AnalysisGeetika VermaNessuna valutazione finora
- Exploratory Factor AnalysisDocumento9 pagineExploratory Factor AnalysisNagatoOzomakiNessuna valutazione finora
- Introduction To Factor Analysis (Compatibility Mode) PDFDocumento20 pagineIntroduction To Factor Analysis (Compatibility Mode) PDFchaitukmrNessuna valutazione finora
- Synopsis of KasifDocumento7 pagineSynopsis of KasifAjeej ShaikNessuna valutazione finora
- PerceptionDocumento33 paginePerceptionapi-3803716100% (3)
- Monitor Company Case AnalysisDocumento6 pagineMonitor Company Case AnalysisNeel JadhavNessuna valutazione finora
- On Organistaion BehaviourDocumento31 pagineOn Organistaion Behaviourvanishachhabra5008100% (1)
- OB Personality & AttitudeDocumento51 pagineOB Personality & AttitudeRUSHI MISTARINessuna valutazione finora
- Quality of Work LifeDocumento13 pagineQuality of Work LifeMarc Eric RedondoNessuna valutazione finora
- Assesment Centre For SelectionDocumento4 pagineAssesment Centre For SelectionVinod Singh BishtNessuna valutazione finora
- Zeus Asset Management SubmissionDocumento5 pagineZeus Asset Management Submissionxirfej100% (1)
- M.Com 2nd Sem Corporate Legal Framework SyllabusDocumento66 pagineM.Com 2nd Sem Corporate Legal Framework SyllabusAashi PatelNessuna valutazione finora
- Personality TypesDocumento20 paginePersonality TypesGURNEESHNessuna valutazione finora
- Amity - Business Communication 2Documento27 pagineAmity - Business Communication 2Raghav MarwahNessuna valutazione finora
- BCG MatrixDocumento7 pagineBCG MatrixWajiha RezaNessuna valutazione finora
- Unit 2 Consumer As An IndividualDocumento17 pagineUnit 2 Consumer As An IndividualRuhit SKNessuna valutazione finora
- Creative Problem SolvingDocumento36 pagineCreative Problem Solvingwaznee100% (2)
- Mahindra & Mahindra - PGDM 39Documento4 pagineMahindra & Mahindra - PGDM 39jagdish_tNessuna valutazione finora
- Business Ethics by Ravinder TulsianiDocumento29 pagineBusiness Ethics by Ravinder TulsianiDeepika AhujaNessuna valutazione finora
- The Parable of the Sadhu and the Larger Purpose of OrganisationsDocumento11 pagineThe Parable of the Sadhu and the Larger Purpose of OrganisationsHimesh AnandNessuna valutazione finora
- What do you see? Individual psychological variablesDocumento30 pagineWhat do you see? Individual psychological variablesMarc David AchacosoNessuna valutazione finora
- Professional Ethics and Human Values NotDocumento116 pagineProfessional Ethics and Human Values Notluis mendozaNessuna valutazione finora
- NAAC Report SSR CollegeDocumento291 pagineNAAC Report SSR CollegeKaruppannanmariappancollege Kmc100% (1)
- Research Assistant: Passbooks Study GuideDa EverandResearch Assistant: Passbooks Study GuideNessuna valutazione finora
- Indian Retail BankingDocumento17 pagineIndian Retail BankingNeelam KarpeNessuna valutazione finora
- Light Electrical Industry Case Studies ReportDocumento70 pagineLight Electrical Industry Case Studies Reporthvactrg1Nessuna valutazione finora
- Motivation TheoriesDocumento40 pagineMotivation TheoriesRadhika GuptaNessuna valutazione finora
- IIMBx BusMgmtMM AAMP FAQ v3 PDFDocumento2 pagineIIMBx BusMgmtMM AAMP FAQ v3 PDFAnirudh AgarwallaNessuna valutazione finora
- Mergers and AmalgmationsDocumento38 pagineMergers and AmalgmationsShweta SawantNessuna valutazione finora
- Evolution of Banking SectorDocumento16 pagineEvolution of Banking SectorNaishrati SoniNessuna valutazione finora
- Presented by Group 18: Neha Srivastava Sneha Shivam Garg TarunaDocumento41 paginePresented by Group 18: Neha Srivastava Sneha Shivam Garg TarunaNeha SrivastavaNessuna valutazione finora
- A Model of Effective Leadership Styles in IndiaDocumento14 pagineA Model of Effective Leadership Styles in IndiaDunes Basher100% (1)
- Case Studies Solutions CHP 5,8Documento2 pagineCase Studies Solutions CHP 5,8Kaleem MiraniNessuna valutazione finora
- Nomothetic Vs IdiographicDocumento9 pagineNomothetic Vs IdiographicBhupesh ManoharanNessuna valutazione finora
- Brake Design ReportDocumento27 pagineBrake Design ReportK.Kiran KumarNessuna valutazione finora
- Module 6 RM: Advanced Data Analysis TechniquesDocumento23 pagineModule 6 RM: Advanced Data Analysis TechniquesEm JayNessuna valutazione finora
- GooglepreviewDocumento24 pagineGooglepreviewwaldemarclausNessuna valutazione finora
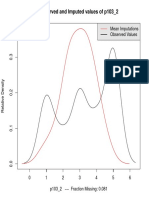
- Observed and Imputed Values of p103 - 2Documento1 paginaObserved and Imputed Values of p103 - 2waldemarclausNessuna valutazione finora
- Banyay, Irene Kardos-The History of The Hungarian MusicDocumento301 pagineBanyay, Irene Kardos-The History of The Hungarian MusicwaldemarclausNessuna valutazione finora
- BibliografíaDocumento1 paginaBibliografíawaldemarclausNessuna valutazione finora
- Call For Papers Coruña 2013 - 2 PDFDocumento2 pagineCall For Papers Coruña 2013 - 2 PDFwaldemarclausNessuna valutazione finora
- Claus LetterDocumento1 paginaClaus LetterwaldemarclausNessuna valutazione finora
- Handbook On Prisons. Willan Publishing, Collumpton: 471-495Documento2 pagineHandbook On Prisons. Willan Publishing, Collumpton: 471-495waldemarclausNessuna valutazione finora
- Chambliss StateorgcrimeDocumento26 pagineChambliss StateorgcrimewaldemarclausNessuna valutazione finora
- Illegal markets, protection rackets and organized crime in RioDocumento19 pagineIllegal markets, protection rackets and organized crime in RiowaldemarclausNessuna valutazione finora
- Bagley Drugs and Violence Final3Documento31 pagineBagley Drugs and Violence Final3waldemarclausNessuna valutazione finora
- Sociology Matters Sample CH1Documento35 pagineSociology Matters Sample CH1Roneil Quban WalkerNessuna valutazione finora
- Within Subjects ANOVADocumento4 pagineWithin Subjects ANOVAwaldemarclaus100% (1)
- Sain M.Documento72 pagineSain M.waldemarclausNessuna valutazione finora
- Unidimensional ScalingDocumento8 pagineUnidimensional ScalingwaldemarclausNessuna valutazione finora
- Sykes y Messinger - The Inmate Social System PDFDocumento9 pagineSykes y Messinger - The Inmate Social System PDFwaldemarclaus0% (1)
- Schrock Identity WorkDocumento18 pagineSchrock Identity WorkwaldemarclausNessuna valutazione finora
- Crime Handbook Final PDFDocumento62 pagineCrime Handbook Final PDFwaldemarclausNessuna valutazione finora
- 02 Ferrel CH 02Documento31 pagine02 Ferrel CH 02waldemarclausNessuna valutazione finora
- Ethno MethodologyDocumento31 pagineEthno MethodologywaldemarclausNessuna valutazione finora
- Moe-The Positive Theory of Public BureaucracyDocumento14 pagineMoe-The Positive Theory of Public BureaucracywaldemarclausNessuna valutazione finora
- Staff Prisoner Relations WhitemoorDocumento201 pagineStaff Prisoner Relations WhitemoorwaldemarclausNessuna valutazione finora
- Going The Distance - Foreign National PrisonersDocumento64 pagineGoing The Distance - Foreign National PrisonerswaldemarclausNessuna valutazione finora
- Moe-The Positive Theory of Public BureaucracyDocumento14 pagineMoe-The Positive Theory of Public BureaucracywaldemarclausNessuna valutazione finora
- Van Maanen, 2010Documento48 pagineVan Maanen, 2010waldemarclausNessuna valutazione finora
- Staff Prisoner Relations WhitemoorDocumento201 pagineStaff Prisoner Relations WhitemoorwaldemarclausNessuna valutazione finora
- Managing The Dilemma: Occupational Culture and Identity Among Prison OfficersDocumento1 paginaManaging The Dilemma: Occupational Culture and Identity Among Prison OfficerswaldemarclausNessuna valutazione finora
- Tait CareandtheprisonDocumento9 pagineTait CareandtheprisonwaldemarclausNessuna valutazione finora
- 6 F608 D 01Documento64 pagine6 F608 D 01waldemarclausNessuna valutazione finora
- 6 F608 D 01Documento64 pagine6 F608 D 01waldemarclausNessuna valutazione finora
- Solving Nonlinear Equations With Newton's MethodDocumento119 pagineSolving Nonlinear Equations With Newton's MethodTMaxtor100% (2)
- Fitri Anjaini Sinaga - 1906113279 - Laporan EVSONDocumento7 pagineFitri Anjaini Sinaga - 1906113279 - Laporan EVSONFitri Anjaini SinagaNessuna valutazione finora
- 6 Bromo Cresol GreenDocumento7 pagine6 Bromo Cresol GreenVincent KwofieNessuna valutazione finora
- JEE Main Sets Relations and Functions Important Questions (2022)Documento16 pagineJEE Main Sets Relations and Functions Important Questions (2022)shreenath gajalwarNessuna valutazione finora
- Lectures #1+2+3Documento10 pagineLectures #1+2+3Long NguyễnNessuna valutazione finora
- Cracking The GRE Chemistry Test, 3rd Edition (Graduate School Test Preparation) 2Documento7.455 pagineCracking The GRE Chemistry Test, 3rd Edition (Graduate School Test Preparation) 2icedjesuschrist0% (21)
- The Role of N H P P Models in The Practical Analysis of Maintenance Failure DataDocumento8 pagineThe Role of N H P P Models in The Practical Analysis of Maintenance Failure DataRoberto Cepeda CastelloNessuna valutazione finora
- MMGT6012 - Topic 7 - Time Series ForecastingDocumento46 pagineMMGT6012 - Topic 7 - Time Series ForecastingHuayu YangNessuna valutazione finora
- M3001 Cheat SheetDocumento4 pagineM3001 Cheat SheetVincent KohNessuna valutazione finora
- Universidad de Las Fuerzas Armadas Espe: Fausto Granda GDocumento13 pagineUniversidad de Las Fuerzas Armadas Espe: Fausto Granda GLuis Adrian CamachoNessuna valutazione finora
- Santander Customer Transaction Prediction Using R - PDFDocumento171 pagineSantander Customer Transaction Prediction Using R - PDFShubham RajNessuna valutazione finora
- Initial ValueDocumento10 pagineInitial ValuemeeranathtNessuna valutazione finora
- Binomial Series QuestionsDocumento2 pagineBinomial Series QuestionsDave WooldridgeNessuna valutazione finora
- AP Practice Exam 1Documento52 pagineAP Practice Exam 1kunichiwaNessuna valutazione finora
- Curl Noise SlidesDocumento52 pagineCurl Noise Slidesregistered99Nessuna valutazione finora
- Find Maximum Element Index in ArrayDocumento6 pagineFind Maximum Element Index in Arraysiddharth1kNessuna valutazione finora
- Literature ReviewDocumento6 pagineLiterature ReviewSiddhi SharmaNessuna valutazione finora
- E180 Standard Practice For Determining The Precision of ASTM Methods For Analysis and Testing of Industrial and Specialty Chemicals PDFDocumento14 pagineE180 Standard Practice For Determining The Precision of ASTM Methods For Analysis and Testing of Industrial and Specialty Chemicals PDFBryan Mesala Rhodas Garcia0% (1)
- Mathematical Inequalities Volume 5 Other Recent Methods For Creating and Solving InequalitiesDocumento554 pagineMathematical Inequalities Volume 5 Other Recent Methods For Creating and Solving InequalitiesNadiaNessuna valutazione finora
- 3D Solid and Axisymmetric Finite ElementsDocumento10 pagine3D Solid and Axisymmetric Finite ElementsQamar Uz ZamanNessuna valutazione finora
- Thomas Calculus SolutionDocumento13 pagineThomas Calculus Solutionong062550% (6)
- Linear Equation in One Variable Part 1 AssignmentDocumento3 pagineLinear Equation in One Variable Part 1 Assignmentgobinda prasad barmanNessuna valutazione finora
- NEXT CHAPTER MYP UP 9 Linear RelationshipsDocumento7 pagineNEXT CHAPTER MYP UP 9 Linear RelationshipsAmos D'Shalom Irush100% (1)
- Course Outline, MATH 101-Calculus-I Sec 1-2 - Fall2021 - Imran NaeemDocumento4 pagineCourse Outline, MATH 101-Calculus-I Sec 1-2 - Fall2021 - Imran Naeemsumbel123Nessuna valutazione finora
- Least CostDocumento4 pagineLeast CostSrikanth Kumar KNessuna valutazione finora
- Example of CGPA & SGPA CalculationsDocumento2 pagineExample of CGPA & SGPA CalculationsGrim Reaper Kuro OnihimeNessuna valutazione finora
- Icomos Iscarsah RecommendationsDocumento39 pagineIcomos Iscarsah RecommendationsGibson 'Gibby' CraigNessuna valutazione finora
- New Normal MPA Statistics Chapter 2Documento15 pagineNew Normal MPA Statistics Chapter 2Mae Ann GonzalesNessuna valutazione finora
- Chapter 4.0 Buffer SolutionDocumento28 pagineChapter 4.0 Buffer SolutionMuhd Mirza HizamiNessuna valutazione finora
- Exploring The Role of Stakeholders in Place Branding - A Case Analysis of The 'City of Liverpool'Documento19 pagineExploring The Role of Stakeholders in Place Branding - A Case Analysis of The 'City of Liverpool'Hasnain AbbasNessuna valutazione finora