Potrebbero piacerti anche
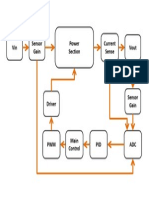
- Sensor Gain Vin Vout Current Sense Power SectionDocumento1 paginaSensor Gain Vin Vout Current Sense Power SectionArfiel Lorenz HerbonNessuna valutazione finora
- Ascott Location MapDocumento1 paginaAscott Location MapAlvin DizonNessuna valutazione finora
- Exp6 7thweek 9thweekDocumento2 pagineExp6 7thweek 9thweekArfiel Lorenz HerbonNessuna valutazione finora
- Acoustic SensorDocumento3 pagineAcoustic SensorArfiel Lorenz HerbonNessuna valutazione finora
- lm741 PDFDocumento9 paginelm741 PDFtry_nguyenNessuna valutazione finora
- Resume SampleDocumento1 paginaResume SampleArfiel Lorenz HerbonNessuna valutazione finora
- Resume SampleDocumento1 paginaResume SampleArfiel Lorenz HerbonNessuna valutazione finora
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDa EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeValutazione: 4 su 5 stelle4/5 (5794)
- The Little Book of Hygge: Danish Secrets to Happy LivingDa EverandThe Little Book of Hygge: Danish Secrets to Happy LivingValutazione: 3.5 su 5 stelle3.5/5 (399)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDa EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryValutazione: 3.5 su 5 stelle3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDa EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceValutazione: 4 su 5 stelle4/5 (894)
- The Yellow House: A Memoir (2019 National Book Award Winner)Da EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Valutazione: 4 su 5 stelle4/5 (98)
- Shoe Dog: A Memoir by the Creator of NikeDa EverandShoe Dog: A Memoir by the Creator of NikeValutazione: 4.5 su 5 stelle4.5/5 (537)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDa EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureValutazione: 4.5 su 5 stelle4.5/5 (474)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDa EverandNever Split the Difference: Negotiating As If Your Life Depended On ItValutazione: 4.5 su 5 stelle4.5/5 (838)
- Grit: The Power of Passion and PerseveranceDa EverandGrit: The Power of Passion and PerseveranceValutazione: 4 su 5 stelle4/5 (587)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDa EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaValutazione: 4.5 su 5 stelle4.5/5 (265)
- The Emperor of All Maladies: A Biography of CancerDa EverandThe Emperor of All Maladies: A Biography of CancerValutazione: 4.5 su 5 stelle4.5/5 (271)
- On Fire: The (Burning) Case for a Green New DealDa EverandOn Fire: The (Burning) Case for a Green New DealValutazione: 4 su 5 stelle4/5 (73)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDa EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersValutazione: 4.5 su 5 stelle4.5/5 (344)
- Team of Rivals: The Political Genius of Abraham LincolnDa EverandTeam of Rivals: The Political Genius of Abraham LincolnValutazione: 4.5 su 5 stelle4.5/5 (234)
- The Unwinding: An Inner History of the New AmericaDa EverandThe Unwinding: An Inner History of the New AmericaValutazione: 4 su 5 stelle4/5 (45)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDa EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyValutazione: 3.5 su 5 stelle3.5/5 (2219)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDa EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreValutazione: 4 su 5 stelle4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Da EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Valutazione: 4.5 su 5 stelle4.5/5 (119)
- Her Body and Other Parties: StoriesDa EverandHer Body and Other Parties: StoriesValutazione: 4 su 5 stelle4/5 (821)
- HTML Cheatsheet GuideDocumento6 pagineHTML Cheatsheet Guidearronstack100% (1)
- Computer Network Q - A Part-1Documento7 pagineComputer Network Q - A Part-1Avi DahiyaNessuna valutazione finora
- Quantitative Methods (10 Chapters)Documento54 pagineQuantitative Methods (10 Chapters)Ravish Chandra67% (3)
- Note: Extra Spare Switches Need To Be Available As Backup Incase of FailuresDocumento21 pagineNote: Extra Spare Switches Need To Be Available As Backup Incase of Failuresrajugs_lgNessuna valutazione finora
- DX LogDocumento27 pagineDX LogCristian96TNessuna valutazione finora
- Class 12 CSC Practical File MysqlDocumento21 pagineClass 12 CSC Practical File MysqlS JAY ADHITYAA100% (1)
- Bcs 031Documento25 pagineBcs 031rsadgaNessuna valutazione finora
- Java MCQ-5Documento4 pagineJava MCQ-5Sri SriNessuna valutazione finora
- Android Ranch ProgrammingDocumento69 pagineAndroid Ranch ProgrammingReg Nullify100% (2)
- Ubuntu - An Absolute Beginner's Guide PDFDocumento32 pagineUbuntu - An Absolute Beginner's Guide PDFJoao CoelhoNessuna valutazione finora
- Data Access ObjectDocumento12 pagineData Access ObjectBurak BasaranNessuna valutazione finora
- DLL Ict 10 Week October 15-19, 2018Documento3 pagineDLL Ict 10 Week October 15-19, 2018Bernadeth Irma Sawal CaballaNessuna valutazione finora
- Explore Usage of Basic Linux Commands and System Calls For File, Directory and Process ManagementDocumento10 pagineExplore Usage of Basic Linux Commands and System Calls For File, Directory and Process ManagementAmruta PoojaryNessuna valutazione finora
- Migrating and Upgrading To Oracle Database 12c Quickly With Near-Zero DowntimeDocumento31 pagineMigrating and Upgrading To Oracle Database 12c Quickly With Near-Zero DowntimesellenduNessuna valutazione finora
- SQL and Xquery Tutorial For Ibm Db2, Part 5:: Data ComparisonDocumento26 pagineSQL and Xquery Tutorial For Ibm Db2, Part 5:: Data ComparisonprasanthnowNessuna valutazione finora
- Storage Area NetworkDocumento109 pagineStorage Area Networksunil kumarNessuna valutazione finora
- Solving math and logic problems from sample documentsDocumento16 pagineSolving math and logic problems from sample documentsSamarth PawaskarNessuna valutazione finora
- Elmalili Hamdi Yazir Hak Dini Kuran Dili TefsiriDocumento12 pagineElmalili Hamdi Yazir Hak Dini Kuran Dili TefsiriYilmaz AltunNessuna valutazione finora
- MET 205 - Cotter PinDocumento64 pagineMET 205 - Cotter Pintomtom9649Nessuna valutazione finora
- Social Media Marketing Overview: Benefits and StrategyDocumento3 pagineSocial Media Marketing Overview: Benefits and StrategyFarah TahirNessuna valutazione finora
- Manual Install Snort IpsDocumento5 pagineManual Install Snort Ipsandreas_kurniawan_26Nessuna valutazione finora
- Iris Case-StudyDocumento30 pagineIris Case-Studyapi-630620365Nessuna valutazione finora
- VACON-ADP-MCAA adapter guideDocumento10 pagineVACON-ADP-MCAA adapter guideSharad Soni0% (1)
- Modelling in Hydrogeology PDFDocumento260 pagineModelling in Hydrogeology PDFAnonymous LsTEoBoTKNessuna valutazione finora
- Fundamentals of Web Technology Unit - 1: Tcp/IpDocumento16 pagineFundamentals of Web Technology Unit - 1: Tcp/IpLone SomhelmeNessuna valutazione finora
- IFP-2100/ECS RFP-2100: Installation and Operation GuideDocumento264 pagineIFP-2100/ECS RFP-2100: Installation and Operation GuideMurali DaranNessuna valutazione finora
- DBS201: Entity Relationship DiagramDocumento17 pagineDBS201: Entity Relationship Diagramtoxic_angel_love958Nessuna valutazione finora
- Ch2 (3) Handouts 3e PDFDocumento10 pagineCh2 (3) Handouts 3e PDFAnonymous eiYUGFJZ3iNessuna valutazione finora
- Ficha Tecnica TermohigrometroDocumento1 paginaFicha Tecnica TermohigrometroRicardo Peña AraozNessuna valutazione finora
- DR 5000 Specifications: You Asked, We Delivered!Documento2 pagineDR 5000 Specifications: You Asked, We Delivered!Road BlasterNessuna valutazione finora