Potrebbero piacerti anche
- WARM SRAM - A Novel Scheme To Reduce Static Leakage Energy in SRAMDocumento8 pagineWARM SRAM - A Novel Scheme To Reduce Static Leakage Energy in SRAMapi-19668941Nessuna valutazione finora
- SRAM Leakage Suppression by Minimizing Standby Supply VoltageDocumento19 pagineSRAM Leakage Suppression by Minimizing Standby Supply Voltageapi-19668941Nessuna valutazione finora
- Ultra-Low Power 90nm 6T SRAM Cell For Wireless Sensor Network ApplicationsDocumento4 pagineUltra-Low Power 90nm 6T SRAM Cell For Wireless Sensor Network Applicationsapi-19668941Nessuna valutazione finora
- Statistically-Aware SRAM Memory Array DesignDocumento17 pagineStatistically-Aware SRAM Memory Array Designapi-19668941Nessuna valutazione finora
- #Reducing The Sub-Threshold and Gate-Tunneling Leakage of SRAMDocumento6 pagine#Reducing The Sub-Threshold and Gate-Tunneling Leakage of SRAMapi-19668941Nessuna valutazione finora
- Low-Leakage Asymmetric-Cell SRAM1Documento4 pagineLow-Leakage Asymmetric-Cell SRAM1api-19668941Nessuna valutazione finora
- Memories I: Dr. T.Y. Chang Nthu Ee 2007.11.20 - 22 - 27Documento38 pagineMemories I: Dr. T.Y. Chang Nthu Ee 2007.11.20 - 22 - 27api-19668941Nessuna valutazione finora
- Radiation Effects Challenges in 90nm Commercial-Density SRAMsDocumento20 pagineRadiation Effects Challenges in 90nm Commercial-Density SRAMsapi-19668941Nessuna valutazione finora
- Direct Tunneling Current Model For Circuit SimulationDocumento4 pagineDirect Tunneling Current Model For Circuit Simulationapi-19668941Nessuna valutazione finora
- Designing For Power BrochureDocumento8 pagineDesigning For Power Brochureapi-19668941Nessuna valutazione finora
- Computing Elements From Carbon NanotubesDocumento6 pagineComputing Elements From Carbon Nanotubesapi-19668941Nessuna valutazione finora
- Grit: The Power of Passion and PerseveranceDa EverandGrit: The Power of Passion and PerseveranceValutazione: 4 su 5 stelle4/5 (588)
- The Yellow House: A Memoir (2019 National Book Award Winner)Da EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Valutazione: 4 su 5 stelle4/5 (98)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDa EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeValutazione: 4 su 5 stelle4/5 (5795)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDa EverandNever Split the Difference: Negotiating As If Your Life Depended On ItValutazione: 4.5 su 5 stelle4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDa EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceValutazione: 4 su 5 stelle4/5 (895)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDa EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersValutazione: 4.5 su 5 stelle4.5/5 (345)
- Shoe Dog: A Memoir by the Creator of NikeDa EverandShoe Dog: A Memoir by the Creator of NikeValutazione: 4.5 su 5 stelle4.5/5 (537)
- The Little Book of Hygge: Danish Secrets to Happy LivingDa EverandThe Little Book of Hygge: Danish Secrets to Happy LivingValutazione: 3.5 su 5 stelle3.5/5 (400)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDa EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureValutazione: 4.5 su 5 stelle4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDa EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryValutazione: 3.5 su 5 stelle3.5/5 (231)
- On Fire: The (Burning) Case for a Green New DealDa EverandOn Fire: The (Burning) Case for a Green New DealValutazione: 4 su 5 stelle4/5 (74)
- The Emperor of All Maladies: A Biography of CancerDa EverandThe Emperor of All Maladies: A Biography of CancerValutazione: 4.5 su 5 stelle4.5/5 (271)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDa EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaValutazione: 4.5 su 5 stelle4.5/5 (266)
- The Unwinding: An Inner History of the New AmericaDa EverandThe Unwinding: An Inner History of the New AmericaValutazione: 4 su 5 stelle4/5 (45)
- Team of Rivals: The Political Genius of Abraham LincolnDa EverandTeam of Rivals: The Political Genius of Abraham LincolnValutazione: 4.5 su 5 stelle4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDa EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyValutazione: 3.5 su 5 stelle3.5/5 (2259)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDa EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreValutazione: 4 su 5 stelle4/5 (1091)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Da EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Valutazione: 4.5 su 5 stelle4.5/5 (121)
- Her Body and Other Parties: StoriesDa EverandHer Body and Other Parties: StoriesValutazione: 4 su 5 stelle4/5 (821)
- CircuitiKz ManualDocumento62 pagineCircuitiKz ManualnospherathusNessuna valutazione finora
- SA-HT940PDocumento114 pagineSA-HT940PAnonymous VEpCQPTUNessuna valutazione finora
- Fault Codes, Scania Engine: SectionDocumento8 pagineFault Codes, Scania Engine: Sectionmirko coppini100% (1)
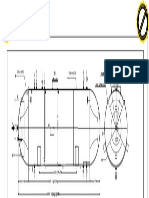
- LPG VesselDocumento1 paginaLPG VesselMarakanaMaheshNessuna valutazione finora
- Scissor LiftDocumento27 pagineScissor LiftKalai100% (1)
- Lesson 1 (Basic Principles of Protective Relays and Circuit Breaker Operations)Documento11 pagineLesson 1 (Basic Principles of Protective Relays and Circuit Breaker Operations)kelotvNessuna valutazione finora
- Pro Forma Invoice For HOWO Tractor Truck and Dump Truck (CIF) CorrigéDocumento2 paginePro Forma Invoice For HOWO Tractor Truck and Dump Truck (CIF) CorrigéFAOUZI100% (1)
- Arnu18Gtq B4: Btu/h Indoor UnitDocumento2 pagineArnu18Gtq B4: Btu/h Indoor UnitCristian monsalve mendozaNessuna valutazione finora
- Job Card ManualDocumento20 pagineJob Card ManualAngga WaeNessuna valutazione finora
- Teslas Electric Car No2Documento5 pagineTeslas Electric Car No2bman0051401Nessuna valutazione finora
- Tier 4 Final Engine: Motor GraderDocumento16 pagineTier 4 Final Engine: Motor Gradergoonzaalo_22Nessuna valutazione finora
- Daihatsu Sirion Model m300 Series Service Manual No9890 MeterDocumento32 pagineDaihatsu Sirion Model m300 Series Service Manual No9890 MeterMarx RedzNessuna valutazione finora
- Konica Minolta Bizhub 360 420 500 ToDocumento302 pagineKonica Minolta Bizhub 360 420 500 ToIulian_DNessuna valutazione finora
- Samsung GT-M2310 11 Disassembly and Assembly InstructionsDocumento6 pagineSamsung GT-M2310 11 Disassembly and Assembly InstructionsmatupaNessuna valutazione finora
- Triple-Sealed Bearings For Ball Bearing Units PDFDocumento5 pagineTriple-Sealed Bearings For Ball Bearing Units PDFGreens MacNessuna valutazione finora
- Types of Vacuum CleanersDocumento2 pagineTypes of Vacuum CleanersAlex DA CostaNessuna valutazione finora
- Technical Service Manual: Heavy-Duty Bracket Mounted Pumps Series 124 Models J, K, KK, L, LQ, LL and LMDocumento16 pagineTechnical Service Manual: Heavy-Duty Bracket Mounted Pumps Series 124 Models J, K, KK, L, LQ, LL and LMryanNessuna valutazione finora
- 01 Vesda Vlc-Ex Tds A4 Ie LoresDocumento2 pagine01 Vesda Vlc-Ex Tds A4 Ie LoresVladimir BukaricaNessuna valutazione finora
- Acer Aspire V5-531-V5-571-V5-431Husk - Petra - UMA - None - Touch - CSDDocumento103 pagineAcer Aspire V5-531-V5-571-V5-431Husk - Petra - UMA - None - Touch - CSDImam WahyuNessuna valutazione finora
- NGR Installation GuideDocumento10 pagineNGR Installation Guidemartins73100% (1)
- BrakesDocumento180 pagineBrakesAdam BonsallNessuna valutazione finora
- 12 Volt 30 Amp PSUDocumento4 pagine12 Volt 30 Amp PSUJefri ErlanggaNessuna valutazione finora
- Aux Valve Brakes ST710Documento16 pagineAux Valve Brakes ST710Jose VegaNessuna valutazione finora
- BANSHEE EXCEL LITE IP66 SpecificationDocumento1 paginaBANSHEE EXCEL LITE IP66 SpecificationVladimir BukaricaNessuna valutazione finora
- SL Manual Lock 13 58 SHAFFER RAM BOP Page-6-10Documento5 pagineSL Manual Lock 13 58 SHAFFER RAM BOP Page-6-10Richard EVNessuna valutazione finora
- GT Seal Oil System StartupDocumento5 pagineGT Seal Oil System StartupHamid AliNessuna valutazione finora
- 988h Lift and Tilt Sensor Cat - Cis.sis - PcontrollerDocumento2 pagine988h Lift and Tilt Sensor Cat - Cis.sis - Pcontrollerrao abdul bariNessuna valutazione finora
- XH240L-V GB r1.0 12.01.2004Documento4 pagineXH240L-V GB r1.0 12.01.2004Jennifer Eszter SárközyNessuna valutazione finora
- Contactors (18AF) : DescriptionDocumento32 pagineContactors (18AF) : DescriptionRobiNessuna valutazione finora
- AS7100Documento52 pagineAS7100Abubakar SidikNessuna valutazione finora