Potrebbero piacerti anche
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDa EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeValutazione: 4 su 5 stelle4/5 (5794)
- Shoe Dog: A Memoir by the Creator of NikeDa EverandShoe Dog: A Memoir by the Creator of NikeValutazione: 4.5 su 5 stelle4.5/5 (537)
- FmcsDocumento25 pagineFmcsHKCHETHANNessuna valutazione finora
- Thesis2005 Fmendoza Uc-ChileDocumento123 pagineThesis2005 Fmendoza Uc-ChileHKCHETHANNessuna valutazione finora
- We ContentDocumento62 pagineWe ContentHKCHETHANNessuna valutazione finora
- Wise2009 6a2 PaperDocumento9 pagineWise2009 6a2 PaperAdnan AkhtarNessuna valutazione finora
- Wise2009 6a2 PaperDocumento9 pagineWise2009 6a2 PaperAdnan AkhtarNessuna valutazione finora
- A Novel Technique To Determine DifferenceDocumento16 pagineA Novel Technique To Determine DifferenceHKCHETHANNessuna valutazione finora
- Docu IPDocumento38 pagineDocu IPHKCHETHANNessuna valutazione finora
- The Yellow House: A Memoir (2019 National Book Award Winner)Da EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Valutazione: 4 su 5 stelle4/5 (98)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDa EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceValutazione: 4 su 5 stelle4/5 (895)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDa EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersValutazione: 4.5 su 5 stelle4.5/5 (344)
- The Little Book of Hygge: Danish Secrets to Happy LivingDa EverandThe Little Book of Hygge: Danish Secrets to Happy LivingValutazione: 3.5 su 5 stelle3.5/5 (399)
- Grit: The Power of Passion and PerseveranceDa EverandGrit: The Power of Passion and PerseveranceValutazione: 4 su 5 stelle4/5 (588)
- The Emperor of All Maladies: A Biography of CancerDa EverandThe Emperor of All Maladies: A Biography of CancerValutazione: 4.5 su 5 stelle4.5/5 (271)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDa EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaValutazione: 4.5 su 5 stelle4.5/5 (266)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDa EverandNever Split the Difference: Negotiating As If Your Life Depended On ItValutazione: 4.5 su 5 stelle4.5/5 (838)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDa EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryValutazione: 3.5 su 5 stelle3.5/5 (231)
- On Fire: The (Burning) Case for a Green New DealDa EverandOn Fire: The (Burning) Case for a Green New DealValutazione: 4 su 5 stelle4/5 (73)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDa EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureValutazione: 4.5 su 5 stelle4.5/5 (474)
- Team of Rivals: The Political Genius of Abraham LincolnDa EverandTeam of Rivals: The Political Genius of Abraham LincolnValutazione: 4.5 su 5 stelle4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDa EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyValutazione: 3.5 su 5 stelle3.5/5 (2259)
- The Unwinding: An Inner History of the New AmericaDa EverandThe Unwinding: An Inner History of the New AmericaValutazione: 4 su 5 stelle4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDa EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreValutazione: 4 su 5 stelle4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Da EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Valutazione: 4.5 su 5 stelle4.5/5 (120)
- Her Body and Other Parties: StoriesDa EverandHer Body and Other Parties: StoriesValutazione: 4 su 5 stelle4/5 (821)
- Associate Cloud Engineer - Study NotesDocumento14 pagineAssociate Cloud Engineer - Study Notesabhi16101Nessuna valutazione finora
- Project Demo On Pet Shop: Group Members: Muhammad Talha Malik Shamook Saad Muhammad HamzaDocumento10 pagineProject Demo On Pet Shop: Group Members: Muhammad Talha Malik Shamook Saad Muhammad HamzaRaja Saad0% (1)
- Exalted Signs Sun in AriesDocumento6 pagineExalted Signs Sun in AriesGaurang PandyaNessuna valutazione finora
- Yoga Nidra - Text PDFDocumento265 pagineYoga Nidra - Text PDFVinod Kumar100% (1)
- Chapter I - Logic and Proofs: PropositionsDocumento18 pagineChapter I - Logic and Proofs: PropositionsNênđặttênngắnTêndàiAimàmuốnđọcNessuna valutazione finora
- NSF Science and Engineering Indicators 2014Documento600 pagineNSF Science and Engineering Indicators 2014Adrian ArizmendiNessuna valutazione finora
- Exalted 2e Sheet2 Mortal v0.1Documento2 pagineExalted 2e Sheet2 Mortal v0.1Lenice EscadaNessuna valutazione finora
- CV HuangfuDocumento5 pagineCV Huangfuapi-297997469Nessuna valutazione finora
- School of Education - Writing A Research Proposal - Durham UniversityDocumento2 pagineSchool of Education - Writing A Research Proposal - Durham UniversityRussasmita Sri PadmiNessuna valutazione finora
- UFO Files From The UK Government DEFE 24/1986Documento419 pagineUFO Files From The UK Government DEFE 24/1986Exit ExitNessuna valutazione finora
- F PortfolioDocumento63 pagineF PortfolioMartin SchmitzNessuna valutazione finora
- Sidereal TimeDocumento6 pagineSidereal TimeBruno LagetNessuna valutazione finora
- Costing of Oil and Gas Projects For Efficient Management and SustainabilityDocumento15 pagineCosting of Oil and Gas Projects For Efficient Management and SustainabilityMohammed M. Mohammed67% (3)
- Derrida, Declarations of Independence PDFDocumento7 pagineDerrida, Declarations of Independence PDFMichael Litwack100% (1)
- Sample Behavioral Interview QuestionsDocumento3 pagineSample Behavioral Interview QuestionssanthoshvNessuna valutazione finora
- Lab ManualDocumento69 pagineLab ManualPradeepNessuna valutazione finora
- About Karmic Debt Numbers in NumerologyDocumento3 pagineAbout Karmic Debt Numbers in NumerologyMarkMadMunki100% (2)
- Skripsi Tanpa Bab Pembahasan PDFDocumento67 pagineSkripsi Tanpa Bab Pembahasan PDFaaaaNessuna valutazione finora
- Probability Form 4Documento10 pagineProbability Form 4Deen ZakariaNessuna valutazione finora
- Forecasting The Return Volatility of The Exchange RateDocumento53 pagineForecasting The Return Volatility of The Exchange RateProdan IoanaNessuna valutazione finora
- Windows Steady State HandbookDocumento81 pagineWindows Steady State HandbookcapellaNessuna valutazione finora
- Director Engineering in Detroit MI Resume Shashank KarnikDocumento3 pagineDirector Engineering in Detroit MI Resume Shashank Karnikshashankkarnik100% (1)
- STIers Meeting Industry ProfessionalsDocumento4 pagineSTIers Meeting Industry ProfessionalsAdrian Reloj VillanuevaNessuna valutazione finora
- Ten Strategies For The Top ManagementDocumento19 pagineTen Strategies For The Top ManagementAQuh C Jhane67% (3)
- Airworthiness Officer QuestionDocumento1 paginaAirworthiness Officer QuestionnanthakumarmaniNessuna valutazione finora
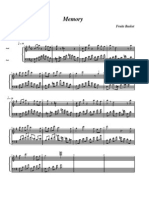
- Fruits Basket - MemoryDocumento1 paginaFruits Basket - Memorywane10132100% (1)
- ParallelDocumento4 pagineParallelShanntha JoshittaNessuna valutazione finora
- Physics Sample Problems With SolutionsDocumento10 paginePhysics Sample Problems With SolutionsMichaelAnthonyNessuna valutazione finora
- English II Homework Module 6Documento5 pagineEnglish II Homework Module 6Yojana DubonNessuna valutazione finora
- Carl Jung - CW 18 Symbolic Life AbstractsDocumento50 pagineCarl Jung - CW 18 Symbolic Life AbstractsReni DimitrovaNessuna valutazione finora