Potrebbero piacerti anche
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDa EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeValutazione: 4 su 5 stelle4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDa EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreValutazione: 4 su 5 stelle4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDa EverandNever Split the Difference: Negotiating As If Your Life Depended On ItValutazione: 4.5 su 5 stelle4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDa EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceValutazione: 4 su 5 stelle4/5 (895)
- Grit: The Power of Passion and PerseveranceDa EverandGrit: The Power of Passion and PerseveranceValutazione: 4 su 5 stelle4/5 (588)
- Shoe Dog: A Memoir by the Creator of NikeDa EverandShoe Dog: A Memoir by the Creator of NikeValutazione: 4.5 su 5 stelle4.5/5 (537)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDa EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersValutazione: 4.5 su 5 stelle4.5/5 (345)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDa EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureValutazione: 4.5 su 5 stelle4.5/5 (474)
- Her Body and Other Parties: StoriesDa EverandHer Body and Other Parties: StoriesValutazione: 4 su 5 stelle4/5 (821)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Da EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Valutazione: 4.5 su 5 stelle4.5/5 (121)
- The Emperor of All Maladies: A Biography of CancerDa EverandThe Emperor of All Maladies: A Biography of CancerValutazione: 4.5 su 5 stelle4.5/5 (271)
- Cobit 2019 Design Toolkit With Description - Group x.20201130165617871Documento46 pagineCobit 2019 Design Toolkit With Description - Group x.20201130165617871Izha Mahendra75% (4)
- The Little Book of Hygge: Danish Secrets to Happy LivingDa EverandThe Little Book of Hygge: Danish Secrets to Happy LivingValutazione: 3.5 su 5 stelle3.5/5 (400)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDa EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyValutazione: 3.5 su 5 stelle3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)Da EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Valutazione: 4 su 5 stelle4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDa EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaValutazione: 4.5 su 5 stelle4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDa EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryValutazione: 3.5 su 5 stelle3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnDa EverandTeam of Rivals: The Political Genius of Abraham LincolnValutazione: 4.5 su 5 stelle4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealDa EverandOn Fire: The (Burning) Case for a Green New DealValutazione: 4 su 5 stelle4/5 (74)
- The Unwinding: An Inner History of the New AmericaDa EverandThe Unwinding: An Inner History of the New AmericaValutazione: 4 su 5 stelle4/5 (45)
- KSLCDocumento52 pagineKSLCzacklawsNessuna valutazione finora
- Pressure-Controlled Pumps CascadeDocumento2 paginePressure-Controlled Pumps Cascadecc_bauNessuna valutazione finora
- A330-200 CommunicationsDocumento42 pagineA330-200 CommunicationsTarik BenzinebNessuna valutazione finora
- Exam Az 400 Designing and Implementing Microsoft Devops Solutions Skills MeasuredDocumento14 pagineExam Az 400 Designing and Implementing Microsoft Devops Solutions Skills Measuredgannoju423Nessuna valutazione finora
- Project Title Selection Letter: PlaceDocumento1 paginaProject Title Selection Letter: Placegannoju423Nessuna valutazione finora
- Awesome Countries: AustraliaDocumento2 pagineAwesome Countries: Australiagannoju423Nessuna valutazione finora
- C Library Function - Memmove : DescriptionDocumento1 paginaC Library Function - Memmove : Descriptiongannoju423Nessuna valutazione finora
- Biggest Countries: GermanyDocumento2 pagineBiggest Countries: Germanygannoju423Nessuna valutazione finora
- Gecassets - Co.in - 8085 Microprocessor - Ramesh GaonkarDocumento330 pagineGecassets - Co.in - 8085 Microprocessor - Ramesh Gaonkargannoju423Nessuna valutazione finora
- Viterbi ImplementationDocumento19 pagineViterbi Implementationgannoju423Nessuna valutazione finora
- Verilog SolnDocumento15 pagineVerilog Solngannoju423100% (1)
- May 4, 2007 9:12 World Scientific Book - 9in X 6in Book-MainDocumento19 pagineMay 4, 2007 9:12 World Scientific Book - 9in X 6in Book-Maingannoju423Nessuna valutazione finora
- Summary of The Types of FlipDocumento2 pagineSummary of The Types of Flipgannoju42350% (2)
- MUDPRO Plus Advanced Mud ReportingDocumento2 pagineMUDPRO Plus Advanced Mud ReportinglarasNessuna valutazione finora
- Rcfe Contract SSHDocumento240 pagineRcfe Contract SSHJeanne MarshNessuna valutazione finora
- Harga Jual Genset Deutz GermanyDocumento2 pagineHarga Jual Genset Deutz GermanyAgung SetiawanNessuna valutazione finora
- MDLink User Manual PDFDocumento41 pagineMDLink User Manual PDFkulov1592Nessuna valutazione finora
- Broch 6700 New 1Documento2 pagineBroch 6700 New 1rumboherbalNessuna valutazione finora
- Prof. Herkutanto-JKN - Patient Safety Dan Etika 2016Documento30 pagineProf. Herkutanto-JKN - Patient Safety Dan Etika 2016galih wicaksonoNessuna valutazione finora
- Durability of Culvert PipeDocumento21 pagineDurability of Culvert PipeIftiNessuna valutazione finora
- T-Spice User's Guide: Release 16.3 June 2015Documento579 pagineT-Spice User's Guide: Release 16.3 June 2015Laxmi GuptaNessuna valutazione finora
- Scooptram ST14 Battery: Fully Battery Electric Loader With 14-Tonne CapacityDocumento8 pagineScooptram ST14 Battery: Fully Battery Electric Loader With 14-Tonne CapacityAnonymous Mdw6y7Q1Nessuna valutazione finora
- Blank Irf - 2023-03-22T001455.667Documento2 pagineBlank Irf - 2023-03-22T001455.667mar asepmalNessuna valutazione finora
- Trial On CompresorDocumento3 pagineTrial On CompresorA JNessuna valutazione finora
- 3D - Quick Start - OptitexHelpEnDocumento26 pagine3D - Quick Start - OptitexHelpEnpanzon_villaNessuna valutazione finora
- Alexandria University Faculty of Engineering: Electromechanical Engineering Sheet 1 (Synchronous Machine)Documento5 pagineAlexandria University Faculty of Engineering: Electromechanical Engineering Sheet 1 (Synchronous Machine)Mahmoud EltawabNessuna valutazione finora
- Sixthsense: - Sanjana Sukumar 3Rd YearDocumento2 pagineSixthsense: - Sanjana Sukumar 3Rd YearSanjana SukumarNessuna valutazione finora
- SBI Clerk Mains Bolt 2023 OliveboardDocumento160 pagineSBI Clerk Mains Bolt 2023 OliveboardMaahi ThakorNessuna valutazione finora
- Building 101 - 25 Tips For A Tropical HomeDocumento11 pagineBuilding 101 - 25 Tips For A Tropical HomeMelanie CabforoNessuna valutazione finora
- 7ML19981GC61 1Documento59 pagine7ML19981GC61 1Andres ColladoNessuna valutazione finora
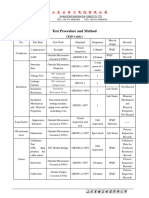
- Test Procedure and MethodDocumento1 paginaTest Procedure and MethodkmiqdNessuna valutazione finora
- Database AssignmentDocumento29 pagineDatabase AssignmentAdasa EdwardsNessuna valutazione finora
- Pre - FabricationDocumento23 paginePre - FabricationMahaveer Singh100% (1)
- 220 Cipher TechniqueDocumento10 pagine220 Cipher Techniquecagedraptor100% (1)
- Family Surveyed 2017 - TimberDocumento26 pagineFamily Surveyed 2017 - TimberAlibasher Macalnas0% (1)
- Assessment of Reinforcement CorrosionDocumento5 pagineAssessment of Reinforcement CorrosionClethHirenNessuna valutazione finora
- Process Hazard Analysis DM Plant - 25.01.18Documento51 pagineProcess Hazard Analysis DM Plant - 25.01.18Debabrata TantubaiNessuna valutazione finora
- Handheld YokogawaDocumento38 pagineHandheld YokogawaArturo Gasperin BarrigaNessuna valutazione finora
- A330 Tire Inspn PDFDocumento21 pagineA330 Tire Inspn PDFRithesh Ram NambiarNessuna valutazione finora