Potrebbero piacerti anche
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDa EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeValutazione: 4 su 5 stelle4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDa EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreValutazione: 4 su 5 stelle4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDa EverandNever Split the Difference: Negotiating As If Your Life Depended On ItValutazione: 4.5 su 5 stelle4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDa EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceValutazione: 4 su 5 stelle4/5 (895)
- Grit: The Power of Passion and PerseveranceDa EverandGrit: The Power of Passion and PerseveranceValutazione: 4 su 5 stelle4/5 (588)
- Shoe Dog: A Memoir by the Creator of NikeDa EverandShoe Dog: A Memoir by the Creator of NikeValutazione: 4.5 su 5 stelle4.5/5 (537)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDa EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersValutazione: 4.5 su 5 stelle4.5/5 (344)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDa EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureValutazione: 4.5 su 5 stelle4.5/5 (474)
- Her Body and Other Parties: StoriesDa EverandHer Body and Other Parties: StoriesValutazione: 4 su 5 stelle4/5 (821)
- Computer Organization and Design SolutionsDocumento228 pagineComputer Organization and Design SolutionsJonathan Cui58% (12)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Da EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Valutazione: 4.5 su 5 stelle4.5/5 (120)
- The Emperor of All Maladies: A Biography of CancerDa EverandThe Emperor of All Maladies: A Biography of CancerValutazione: 4.5 su 5 stelle4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingDa EverandThe Little Book of Hygge: Danish Secrets to Happy LivingValutazione: 3.5 su 5 stelle3.5/5 (399)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDa EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyValutazione: 3.5 su 5 stelle3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)Da EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Valutazione: 4 su 5 stelle4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDa EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaValutazione: 4.5 su 5 stelle4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDa EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryValutazione: 3.5 su 5 stelle3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnDa EverandTeam of Rivals: The Political Genius of Abraham LincolnValutazione: 4.5 su 5 stelle4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealDa EverandOn Fire: The (Burning) Case for a Green New DealValutazione: 4 su 5 stelle4/5 (73)
- The Unwinding: An Inner History of the New AmericaDa EverandThe Unwinding: An Inner History of the New AmericaValutazione: 4 su 5 stelle4/5 (45)
- Chapter 6 Strategy Analysis and Choice: Strategic Management: A Competitive Advantage Approach, 16e (David)Documento27 pagineChapter 6 Strategy Analysis and Choice: Strategic Management: A Competitive Advantage Approach, 16e (David)Masum ZamanNessuna valutazione finora
- The Perception of Luxury Cars MA Thesis 25 03Documento60 pagineThe Perception of Luxury Cars MA Thesis 25 03Quaxi1954Nessuna valutazione finora
- Literature Review - Part Time Job Among StudentDocumento3 pagineLiterature Review - Part Time Job Among StudentMarria65% (20)
- Ferrero A.M. Et Al. (2015) - Experimental Tests For The Application of An Analytical Model For Flexible Debris Flow Barrier Design PDFDocumento10 pagineFerrero A.M. Et Al. (2015) - Experimental Tests For The Application of An Analytical Model For Flexible Debris Flow Barrier Design PDFEnrico MassaNessuna valutazione finora
- Final LUS EvaluationDocumento36 pagineFinal LUS EvaluationNextgenNessuna valutazione finora
- Notes On Work System Concepts1Documento12 pagineNotes On Work System Concepts1Abraham JyothimonNessuna valutazione finora
- GDL Louvre CalculatorDocumento1 paginaGDL Louvre CalculatorAbraham JyothimonNessuna valutazione finora
- (Dewa-98%) Anova-Safety and Secuirty ScoreDocumento6 pagine(Dewa-98%) Anova-Safety and Secuirty ScoreAbraham JyothimonNessuna valutazione finora
- Risk Sharing in JVsDocumento162 pagineRisk Sharing in JVsAbraham JyothimonNessuna valutazione finora
- Consept Mind Mapping PDFDocumento23 pagineConsept Mind Mapping PDFDian FithriaNessuna valutazione finora
- How Einstein Formed RelativityDocumento2 pagineHow Einstein Formed RelativityAbraham JyothimonNessuna valutazione finora
- Selton's Horse (Posterior Lottery Model)Documento3 pagineSelton's Horse (Posterior Lottery Model)Abraham JyothimonNessuna valutazione finora
- Iso 12944 PDFDocumento4 pagineIso 12944 PDFAdana100% (1)
- Permit Process FOR PV sYSTEMS PDFDocumento82 paginePermit Process FOR PV sYSTEMS PDFAbraham Jyothimon100% (1)
- Inequalities A Journey Into Linear Analysis - D. J. H. Garling, CUP 2007Documento348 pagineInequalities A Journey Into Linear Analysis - D. J. H. Garling, CUP 2007mago622100% (2)
- E-Dilation (Prohorov Metric)Documento19 pagineE-Dilation (Prohorov Metric)Abraham JyothimonNessuna valutazione finora
- Economicsproofseparating WeitzmanDocumento6 pagineEconomicsproofseparating WeitzmanAbraham JyothimonNessuna valutazione finora
- Corrosion PDFDocumento5 pagineCorrosion PDFAntonio MartinNessuna valutazione finora
- Complex Measure &positive MeasureDocumento1 paginaComplex Measure &positive MeasureAbraham JyothimonNessuna valutazione finora
- Importance of Loop Impedance TesterDocumento4 pagineImportance of Loop Impedance TesterAbraham JyothimonNessuna valutazione finora
- Planning by Minkowiski MetricDocumento22 paginePlanning by Minkowiski MetricAbraham JyothimonNessuna valutazione finora
- BEST Sperners Lemma PPADDocumento23 pagineBEST Sperners Lemma PPADAbraham JyothimonNessuna valutazione finora
- Survey Works Rev 1Documento12 pagineSurvey Works Rev 1Abraham JyothimonNessuna valutazione finora
- Resource Allocation Mechanism-Detailed ProgtammingDocumento27 pagineResource Allocation Mechanism-Detailed ProgtammingAbraham JyothimonNessuna valutazione finora
- Arc Flash - Enclosure-Reducing FactorDocumento7 pagineArc Flash - Enclosure-Reducing FactorAbraham JyothimonNessuna valutazione finora
- Examples Done On Orthogonal ProjectionDocumento79 pagineExamples Done On Orthogonal ProjectionAbraham JyothimonNessuna valutazione finora
- Short Guide On UAE Labour LawDocumento5 pagineShort Guide On UAE Labour LawPc SubramaniNessuna valutazione finora
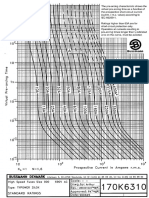
- Bussman CurvesDocumento2 pagineBussman CurvesAbraham JyothimonNessuna valutazione finora
- Lecture Notes On Differential GamesDocumento77 pagineLecture Notes On Differential GamesOctavio MartinezNessuna valutazione finora
- 6handle Rule NecDocumento95 pagine6handle Rule NecAbraham Jyothimon100% (1)
- Bosch PaDocumento498 pagineBosch PaAbraham JyothimonNessuna valutazione finora
- Upper & Lower Contour SetsDocumento12 pagineUpper & Lower Contour SetsAbraham JyothimonNessuna valutazione finora
- Riemann SurfaceDocumento71 pagineRiemann SurfaceAbir DeyNessuna valutazione finora
- Flood DetectorDocumento20 pagineFlood DetectorAbraham JyothimonNessuna valutazione finora
- Handout Waste Catch BasinDocumento2 pagineHandout Waste Catch BasinJonniel De GuzmanNessuna valutazione finora
- Performance Task 2Documento3 paginePerformance Task 2Edrose WycocoNessuna valutazione finora
- The Teacher Research Movement: A Decade Later: Cite This PaperDocumento13 pagineThe Teacher Research Movement: A Decade Later: Cite This PaperAlexandre NecromanteionNessuna valutazione finora
- Lesson Plan Letter SDocumento4 pagineLesson Plan Letter Sapi-317303624100% (1)
- Lesson Plan 1Documento3 pagineLesson Plan 1api-311983208Nessuna valutazione finora
- Present Perfect Simp ContDocumento14 paginePresent Perfect Simp ContLauGalindo100% (1)
- S3 U4 MiniTestDocumento3 pagineS3 U4 MiniTestĐinh Thị Thu HàNessuna valutazione finora
- Essay On Stem CellsDocumento4 pagineEssay On Stem CellsAdrien G. S. WaldNessuna valutazione finora
- MSDS Leadframe (16 Items)Documento8 pagineMSDS Leadframe (16 Items)bennisg8Nessuna valutazione finora
- GR 9 Eng CodebDocumento6 pagineGR 9 Eng CodebSharmista WalterNessuna valutazione finora
- Code of Practice For Design Loads (Other Than Earthquake) For Buildings and StructuresDocumento39 pagineCode of Practice For Design Loads (Other Than Earthquake) For Buildings and StructuresIshor ThapaNessuna valutazione finora
- QF Jacket (Drafting & Cutting) - GAR620Documento15 pagineQF Jacket (Drafting & Cutting) - GAR620abdulraheem18822Nessuna valutazione finora
- Module 5Documento14 pagineModule 5shin roseNessuna valutazione finora
- Passage Planning: Dr. Arwa HusseinDocumento15 paginePassage Planning: Dr. Arwa HusseinArwa Hussein100% (3)
- University of Ghana: This Paper Contains Two Parts (PART I and PART II) Answer All Questions From Both PARTSDocumento3 pagineUniversity of Ghana: This Paper Contains Two Parts (PART I and PART II) Answer All Questions From Both PARTSPhilip Pearce-PearsonNessuna valutazione finora
- Task of ProjectDocumento14 pagineTask of ProjectAbdul Wafiy NaqiuddinNessuna valutazione finora
- Sub-Wings of YuvanjaliDocumento2 pagineSub-Wings of Yuvanjalin_tapovan987100% (1)
- Case Study McsDocumento4 pagineCase Study McsManjushree PatilNessuna valutazione finora
- Industrial Motor Control Part IDocumento38 pagineIndustrial Motor Control Part Ikibrom atsbha100% (2)
- CrimDocumento29 pagineCrimkeziahmae.bagacinaNessuna valutazione finora
- Ec 0301Documento25 pagineEc 0301Silvio RomanNessuna valutazione finora
- MCFKTP G3 S2 SC Number Pattern PuzzlesDocumento5 pagineMCFKTP G3 S2 SC Number Pattern PuzzlesEric GoNessuna valutazione finora
- Project Report For Tunnel ExcavationDocumento19 pagineProject Report For Tunnel ExcavationAbhishek Sarkar50% (2)
- 2396510-14-8EN - r1 - Service Information and Procedures Class MDocumento2.072 pagine2396510-14-8EN - r1 - Service Information and Procedures Class MJuan Bautista PradoNessuna valutazione finora
- Matutum View Academy: (The School of Faith)Documento14 pagineMatutum View Academy: (The School of Faith)Neil Trezley Sunico BalajadiaNessuna valutazione finora