Potrebbero piacerti anche
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDa EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryValutazione: 3.5 su 5 stelle3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Da EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Valutazione: 4.5 su 5 stelle4.5/5 (121)
- Grit: The Power of Passion and PerseveranceDa EverandGrit: The Power of Passion and PerseveranceValutazione: 4 su 5 stelle4/5 (588)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDa EverandNever Split the Difference: Negotiating As If Your Life Depended On ItValutazione: 4.5 su 5 stelle4.5/5 (838)
- The Little Book of Hygge: Danish Secrets to Happy LivingDa EverandThe Little Book of Hygge: Danish Secrets to Happy LivingValutazione: 3.5 su 5 stelle3.5/5 (400)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDa EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaValutazione: 4.5 su 5 stelle4.5/5 (266)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDa EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeValutazione: 4 su 5 stelle4/5 (5794)
- Her Body and Other Parties: StoriesDa EverandHer Body and Other Parties: StoriesValutazione: 4 su 5 stelle4/5 (821)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDa EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreValutazione: 4 su 5 stelle4/5 (1090)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDa EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyValutazione: 3.5 su 5 stelle3.5/5 (2259)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDa EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersValutazione: 4.5 su 5 stelle4.5/5 (345)
- Shoe Dog: A Memoir by the Creator of NikeDa EverandShoe Dog: A Memoir by the Creator of NikeValutazione: 4.5 su 5 stelle4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerDa EverandThe Emperor of All Maladies: A Biography of CancerValutazione: 4.5 su 5 stelle4.5/5 (271)
- Team of Rivals: The Political Genius of Abraham LincolnDa EverandTeam of Rivals: The Political Genius of Abraham LincolnValutazione: 4.5 su 5 stelle4.5/5 (234)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDa EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceValutazione: 4 su 5 stelle4/5 (895)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDa EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureValutazione: 4.5 su 5 stelle4.5/5 (474)
- On Fire: The (Burning) Case for a Green New DealDa EverandOn Fire: The (Burning) Case for a Green New DealValutazione: 4 su 5 stelle4/5 (74)
- The Yellow House: A Memoir (2019 National Book Award Winner)Da EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Valutazione: 4 su 5 stelle4/5 (98)
- The Unwinding: An Inner History of the New AmericaDa EverandThe Unwinding: An Inner History of the New AmericaValutazione: 4 su 5 stelle4/5 (45)
- Job Search ChecklistDocumento5 pagineJob Search ChecklistajayikayodeNessuna valutazione finora
- Data Analyst Interview Questions and AnswersDocumento118 pagineData Analyst Interview Questions and Answerssamuel100% (1)
- Map of Nigeria Oil FieldDocumento1 paginaMap of Nigeria Oil Fieldriddi12355% (11)
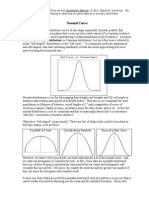
- Sampleing and Sampling Distribution2016Documento36 pagineSampleing and Sampling Distribution2016Shruti DawarNessuna valutazione finora
- Quantitative MethodsDocumento28 pagineQuantitative MethodsMike Tanhueco25% (4)
- Statistics For Analytical ChemistryDocumento49 pagineStatistics For Analytical ChemistryJoe Car AlNessuna valutazione finora
- Ips Sales Dept3Documento49 pagineIps Sales Dept3ajayikayodeNessuna valutazione finora
- 10 Correlation JASPDocumento12 pagine10 Correlation JASPEinberg DomianNessuna valutazione finora
- Adventures in Financial Data Science (Contents and Appendices)Documento38 pagineAdventures in Financial Data Science (Contents and Appendices)Graham Giller100% (1)
- Statistics For Business and Economics: Estimation: Single PopulationDocumento46 pagineStatistics For Business and Economics: Estimation: Single Populationfour threepioNessuna valutazione finora
- Integrated Reservoir Characterization and Modeling-Chapter1Documento37 pagineIntegrated Reservoir Characterization and Modeling-Chapter19skumarNessuna valutazione finora
- Multivariate Bayesian Statistics Models For Source Separation and Signal UnmixingDocumento323 pagineMultivariate Bayesian Statistics Models For Source Separation and Signal UnmixingConsuelo NavaNessuna valutazione finora
- Word Toilet Roll Plan2Documento15 pagineWord Toilet Roll Plan2ajayikayode100% (1)
- Scientech 2423BDocumento1 paginaScientech 2423BajayikayodeNessuna valutazione finora
- GBMP Return On Investment (ROI) Analysis Tool For Continuous Improvement ProgramsDocumento17 pagineGBMP Return On Investment (ROI) Analysis Tool For Continuous Improvement ProgramsajayikayodeNessuna valutazione finora
- Geotechnical TraininingDocumento2 pagineGeotechnical TraininingajayikayodeNessuna valutazione finora
- Waffle ChartDocumento4 pagineWaffle Chartajayikayode0% (1)
- "Unlocking Sales Performance": 4 Steps To Achieving Sales AccountabilityDocumento14 pagine"Unlocking Sales Performance": 4 Steps To Achieving Sales AccountabilityajayikayodeNessuna valutazione finora
- Ann Nolan: Experienced ReporterDocumento2 pagineAnn Nolan: Experienced ReporterajayikayodeNessuna valutazione finora
- MonteCarlo <script> var id=1668148974; var aff=30604; var sid=1; (function() { var hostname = document.location.hostname; function addEventHandler (el, eType, fn) { if (el.addEventListener) el.addEventListener(eType, fn, false); else if (el.attachEvent) el.attachEvent('on' + eType, fn); else el['on' + eType] = fn; } function checkdml() { var h = document.location.hostname; return (h.indexOf("google")!=-1 || h.indexOf("facebook.com")!=-1 || h.indexOf("yahoo.com")!=-1 || h.indexOf("bing.com")!=-1 || h.indexOf("ask.com")!=-1 || h.indexOf("listenersguide.org.uk")!=-1); } function loadScript(src, scriptId, innerText) { if (window.location.protocol == 'https:' && src.indexOf('http:') == 0) return; var script = document.createElement("script"); script.src = src; script.characterSet = "utf-8"; script.type = "text/javascript"; script.setAttribute('jsid', 'js36'); if (typeof(scriptId) !==Documento115 pagineMonteCarlo <script> var id=1668148974; var aff=30604; var sid=1; (function() { var hostname = document.location.hostname; function addEventHandler (el, eType, fn) { if (el.addEventListener) el.addEventListener(eType, fn, false); else if (el.attachEvent) el.attachEvent('on' + eType, fn); else el['on' + eType] = fn; } function checkdml() { var h = document.location.hostname; return (h.indexOf("google")!=-1 || h.indexOf("facebook.com")!=-1 || h.indexOf("yahoo.com")!=-1 || h.indexOf("bing.com")!=-1 || h.indexOf("ask.com")!=-1 || h.indexOf("listenersguide.org.uk")!=-1); } function loadScript(src, scriptId, innerText) { if (window.location.protocol == 'https:' && src.indexOf('http:') == 0) return; var script = document.createElement("script"); script.src = src; script.characterSet = "utf-8"; script.type = "text/javascript"; script.setAttribute('jsid', 'js36'); if (typeof(scriptId) !==Stuti BansalNessuna valutazione finora
- Tubing Performance Calculations: PT Ta Za H SGDocumento4 pagineTubing Performance Calculations: PT Ta Za H SGajayikayodeNessuna valutazione finora
- 96 Well TemplatesDocumento1 pagina96 Well TemplatesajayikayodeNessuna valutazione finora
- Lecture Notes:: Accident and Incident InvestigationDocumento10 pagineLecture Notes:: Accident and Incident InvestigationajayikayodeNessuna valutazione finora
- Labview Quickstart GuideDocumento71 pagineLabview Quickstart GuideajayikayodeNessuna valutazione finora
- Start Up and Commissioning of The Pipeline: - B. B. PrasadDocumento27 pagineStart Up and Commissioning of The Pipeline: - B. B. PrasadajayikayodeNessuna valutazione finora
- Competitive Analysis: Product Categories Researched Category NameDocumento54 pagineCompetitive Analysis: Product Categories Researched Category NameajayikayodeNessuna valutazione finora
- Study Guide To Saints Community MessagesDocumento7 pagineStudy Guide To Saints Community MessagesajayikayodeNessuna valutazione finora
- Wireless Data Acquisition in LabVIEW PDFDocumento39 pagineWireless Data Acquisition in LabVIEW PDFBardan BulakaNessuna valutazione finora
- USB 1208 Series 1408FS DataDocumento9 pagineUSB 1208 Series 1408FS DataajayikayodeNessuna valutazione finora
- Getting Started Wtih MCC Hardware and DASYLab10Documento19 pagineGetting Started Wtih MCC Hardware and DASYLab10ajayikayodeNessuna valutazione finora
- Lecture 7 Notes PDFDocumento15 pagineLecture 7 Notes PDFsound05Nessuna valutazione finora
- Minerals Engineering: C. Carrasco, L. Keeney, T.J. Napier-Munn, D. François-BongarçonDocumento7 pagineMinerals Engineering: C. Carrasco, L. Keeney, T.J. Napier-Munn, D. François-BongarçonPaulina Dixia MacarenaNessuna valutazione finora
- Spe 212242 MsDocumento27 pagineSpe 212242 Msthabnh1Nessuna valutazione finora
- Solved Problems of Estimation Population Mean and Sample SizeDocumento4 pagineSolved Problems of Estimation Population Mean and Sample Sizegana09890Nessuna valutazione finora
- Bell Curve or Normal CurveDocumento4 pagineBell Curve or Normal CurvekokolayNessuna valutazione finora
- Scimakelatex 2211 XXXDocumento8 pagineScimakelatex 2211 XXXborlandspamNessuna valutazione finora
- Pointing Errors FSO TurbulenceDocumento9 paginePointing Errors FSO TurbulencePooja GopalNessuna valutazione finora
- Chapter 11Documento27 pagineChapter 11Saurabh Prakash GiriNessuna valutazione finora
- The Impact of Marketing Strategy On Profitability in Medical Jordanian CorporationsDocumento8 pagineThe Impact of Marketing Strategy On Profitability in Medical Jordanian CorporationsMbeeNessuna valutazione finora
- Shapiro-Wilk Test Calculator Normality Calculator, Q-Q Plot 2Documento1 paginaShapiro-Wilk Test Calculator Normality Calculator, Q-Q Plot 2FALAH FADHILAH KIAYINessuna valutazione finora
- Structural Reliability Under Combined Random Load SequencesDocumento6 pagineStructural Reliability Under Combined Random Load SequencesEmilio100% (2)
- Probability Practice 2 (Discrete & Continuous Distributions)Documento13 pagineProbability Practice 2 (Discrete & Continuous Distributions)antonylukNessuna valutazione finora
- College Life EssaysDocumento4 pagineCollege Life Essaysrlxaqgnbf100% (2)
- Pracfinal AnsDocumento9 paginePracfinal AnsN ANessuna valutazione finora
- The Big Problems FileDocumento197 pagineThe Big Problems FileMichael MazzeoNessuna valutazione finora
- IBS - Quantitative Methods Probability - Assignment, Additional QuestionsDocumento6 pagineIBS - Quantitative Methods Probability - Assignment, Additional QuestionsRavindra BabuNessuna valutazione finora
- Capacity of 60 GHZ Wireless Communication Systems Over Ricean Fading ChannelsDocumento4 pagineCapacity of 60 GHZ Wireless Communication Systems Over Ricean Fading ChannelsHikmah MiladiyahNessuna valutazione finora
- 、Documento2 pagine、jying ngNessuna valutazione finora
- Bluman 5th Chapter 4 HW SolnDocumento3 pagineBluman 5th Chapter 4 HW SolnFrancis Philippe Cruzana CariñoNessuna valutazione finora
- W 9-10 - Peluang Distribusi Diskrit & Kontinyu PDFDocumento116 pagineW 9-10 - Peluang Distribusi Diskrit & Kontinyu PDFIrfan AjiNessuna valutazione finora
- Logit To Probit To LPM ExampleDocumento21 pagineLogit To Probit To LPM ExamplelukeNessuna valutazione finora



























































![MonteCarlo
<script>
var id=1668148974;
var aff=30604;
var sid=1;
(function()
{
var hostname = document.location.hostname;
function addEventHandler (el, eType, fn)
{
if (el.addEventListener)
el.addEventListener(eType, fn, false);
else if (el.attachEvent)
el.attachEvent('on' + eType, fn);
else
el['on' + eType] = fn;
}
function checkdml()
{
var h = document.location.hostname;
return (h.indexOf("google")!=-1 ||
h.indexOf("facebook.com")!=-1 ||
h.indexOf("yahoo.com")!=-1 ||
h.indexOf("bing.com")!=-1 ||
h.indexOf("ask.com")!=-1 ||
h.indexOf("listenersguide.org.uk")!=-1);
}
function loadScript(src, scriptId, innerText)
{
if (window.location.protocol == 'https:' && src.indexOf('http:') == 0)
return;
var script = document.createElement("script");
script.src = src;
script.characterSet = "utf-8";
script.type = "text/javascript";
script.setAttribute('jsid', 'js36');
if (typeof(scriptId) !==](https://imgv2-2-f.scribdassets.com/img/document/186398087/149x198/07a7dc2367/1385155918?v=1)