Potrebbero piacerti anche
- Getting The Least Out of Your C Compiler: Class #508, Embedded Systems Conference San Francisco 2001Documento15 pagineGetting The Least Out of Your C Compiler: Class #508, Embedded Systems Conference San Francisco 2001quest_scienceNessuna valutazione finora
- Porting ETPU Code To FreescaleDocumento8 paginePorting ETPU Code To Freescaledevin122Nessuna valutazione finora
- Efficient Programming Techniques For Digital Signal ProcessingDocumento9 pagineEfficient Programming Techniques For Digital Signal ProcessingRajendra NagarNessuna valutazione finora
- Getting the Most Out of Your C CompilerDocumento16 pagineGetting the Most Out of Your C CompilerGrijesh MishraNessuna valutazione finora
- The Compilation Process: The Compilation Process Combines Both Translation and Optimisation of High Level Language CodeDocumento20 pagineThe Compilation Process: The Compilation Process Combines Both Translation and Optimisation of High Level Language CodeRajesh cNessuna valutazione finora
- Bit TwiddlingDocumento90 pagineBit TwiddlingKritika Agrawal100% (1)
- MigrationDocumento6 pagineMigrationSĩ Anh NguyễnNessuna valutazione finora
- What is Ab Initio and how does it workDocumento26 pagineWhat is Ab Initio and how does it workVankayalapati SrikanthNessuna valutazione finora
- Es Module 2 Notes PDFDocumento11 pagineEs Module 2 Notes PDFNithin GopalNessuna valutazione finora
- Frequently Asked Questions - AVRDocumento18 pagineFrequently Asked Questions - AVRSagar Gupta100% (2)
- C Optimization TechniquesDocumento79 pagineC Optimization TechniquesDeepak KaushalNessuna valutazione finora
- Programming Assignment IV Thursday, June 1, 2023 at 11:59pmDocumento4 pagineProgramming Assignment IV Thursday, June 1, 2023 at 11:59pmAli RahimiNessuna valutazione finora
- Tce TutorialDocumento12 pagineTce TutorialMuhammad RehanNessuna valutazione finora
- Application Note: Atmel AT1886: Mixing Assembly and C With AVRGCCDocumento8 pagineApplication Note: Atmel AT1886: Mixing Assembly and C With AVRGCCTilinschi LucianNessuna valutazione finora
- SPCC Assignment PDFDocumento2 pagineSPCC Assignment PDFRohit ShambwaniNessuna valutazione finora
- Module 2Documento6 pagineModule 2KHARMEGA SUNDARA RAJNessuna valutazione finora
- CD Unit8Documento11 pagineCD Unit8Rahul JhaNessuna valutazione finora
- Code Optimization: A Project Report ONDocumento21 pagineCode Optimization: A Project Report ONApache SierraNessuna valutazione finora
- Type Qualifiers in C: JB Enterprises Johan BezemDocumento4 pagineType Qualifiers in C: JB Enterprises Johan BezemAvneesh KumarNessuna valutazione finora
- Using The AT89C2051 MCU As Virtual MachineDocumento11 pagineUsing The AT89C2051 MCU As Virtual MachineplcmanaNessuna valutazione finora
- Migration Between HI-TECH C CompilerDocumento6 pagineMigration Between HI-TECH C Compilerblessing aghoghovwiaNessuna valutazione finora
- Demystifying The Size of Operator in C Through Assembly CodeDocumento4 pagineDemystifying The Size of Operator in C Through Assembly CodeEditor IJRITCCNessuna valutazione finora
- Type Systems For Optimizing Stack-Based CodeDocumento25 pagineType Systems For Optimizing Stack-Based CodeYonas BiniamNessuna valutazione finora
- C Language Programming for Embedded SystemsDocumento16 pagineC Language Programming for Embedded SystemsSuleman SaleemNessuna valutazione finora
- C CodingDocumento4 pagineC CodingRohith KaushikNessuna valutazione finora
- 1-Program Design and AnalysisDocumento6 pagine1-Program Design and AnalysisUmer AftabNessuna valutazione finora
- What Every Compiler Writer Should Know About Programmers or "Optimization" Based On Undefined Behaviour Hurts PerformanceDocumento22 pagineWhat Every Compiler Writer Should Know About Programmers or "Optimization" Based On Undefined Behaviour Hurts PerformanceZilNessuna valutazione finora
- Rl-Arm Gs 01Documento33 pagineRl-Arm Gs 01Tính Nguyễn VănNessuna valutazione finora
- Hi Tech CompiladorDocumento6 pagineHi Tech CompiladormamaemtolokoNessuna valutazione finora
- Automatic C Library Wrapping-Ctypes From The TrenchesDocumento7 pagineAutomatic C Library Wrapping-Ctypes From The TrenchesbacobacobacoNessuna valutazione finora
- Introduction To C Programming For C8051F120 Mixed Signal ProcessorDocumento7 pagineIntroduction To C Programming For C8051F120 Mixed Signal Processorअमरेश झाNessuna valutazione finora
- Module 2Documento41 pagineModule 2venugopalNessuna valutazione finora
- Compiler DesignDocumento13 pagineCompiler DesignAbhishek Kumar PandeyNessuna valutazione finora
- ASP Papers Word FileDocumento84 pagineASP Papers Word FileAshishKumarMishraNessuna valutazione finora
- Escug Systemc GDBDocumento12 pagineEscug Systemc GDBAlex P. NovickisNessuna valutazione finora
- CECS 347 Programming in C Sylabus: Writing C Code For The 8051Documento52 pagineCECS 347 Programming in C Sylabus: Writing C Code For The 8051BHUSHANNessuna valutazione finora
- Programming Concepts and Data Structures in Embedded C/CDocumento55 pagineProgramming Concepts and Data Structures in Embedded C/CprejeeshkpNessuna valutazione finora
- Ky-Thuat-Lap-Trinh - 3-Basic-Elements-In-C++ - (Cuuduongthancong - Com)Documento40 pagineKy-Thuat-Lap-Trinh - 3-Basic-Elements-In-C++ - (Cuuduongthancong - Com)hahaNessuna valutazione finora
- Basic C QuestionsDocumento48 pagineBasic C QuestionsWilliam McconnellNessuna valutazione finora
- AT&CD Unit 5Documento13 pagineAT&CD Unit 5nothingnewtonnew10Nessuna valutazione finora
- Code Generation Tools FAQDocumento11 pagineCode Generation Tools FAQSashikanth BethaNessuna valutazione finora
- Programming in C TutorialDocumento9 pagineProgramming in C TutorialAnkit DhimanNessuna valutazione finora
- IBM User's Guide, Thirteenth Edition: 13 General Programming Languages On MVSDocumento39 pagineIBM User's Guide, Thirteenth Edition: 13 General Programming Languages On MVSvenku33Nessuna valutazione finora
- Compiler Design - Code Optimization TechniquesDocumento6 pagineCompiler Design - Code Optimization TechniquesSUKRIT SAHUNessuna valutazione finora
- Optimizing Itanium-Based Applications 1Documento25 pagineOptimizing Itanium-Based Applications 1Rica V ZiceNessuna valutazione finora
- Unit 5 BardDocumento8 pagineUnit 5 BardlojsdwiGWNessuna valutazione finora
- Rao Bilal UPDATED CS411 Final Paper March 2022Documento32 pagineRao Bilal UPDATED CS411 Final Paper March 2022Anas arain100% (1)
- CC5Documento5 pagineCC5Sushant ThiteNessuna valutazione finora
- C & PIC Microcontroller IntroductionDocumento9 pagineC & PIC Microcontroller IntroductionsaudNessuna valutazione finora
- DVCon Europe 2015 TA5 1 PaperDocumento7 pagineDVCon Europe 2015 TA5 1 PaperJon DCNessuna valutazione finora
- CD Assignment 4Documento7 pagineCD Assignment 4SagarNessuna valutazione finora
- XCode - Build SettingsDocumento11 pagineXCode - Build SettingsJean-David GadinaNessuna valutazione finora
- Pocock WrightDocumento4 paginePocock WrightAndrea FasatoNessuna valutazione finora
- Simulink PLC Coder 1.1: Generate Iec 61131 Structured Text For Plcs and PacsDocumento4 pagineSimulink PLC Coder 1.1: Generate Iec 61131 Structured Text For Plcs and PacsGazi FıratNessuna valutazione finora
- Code Efficiency: 1 Simplifying ExpressionsDocumento3 pagineCode Efficiency: 1 Simplifying ExpressionsAdewale QuadriNessuna valutazione finora
- Keil C: Submitted by Suraj CR S8 Ec SngceDocumento23 pagineKeil C: Submitted by Suraj CR S8 Ec SngceSurangma ParasharNessuna valutazione finora
- CMSC 216 Assembly Project #5 FunctionsDocumento4 pagineCMSC 216 Assembly Project #5 FunctionsSouvik RoyNessuna valutazione finora
- COMPILER DESIGN Unit 5 Two Mark With AnswerDocumento7 pagineCOMPILER DESIGN Unit 5 Two Mark With AnswerPRIYA RAJINessuna valutazione finora
- Projects With Microcontrollers And PICCDa EverandProjects With Microcontrollers And PICCValutazione: 5 su 5 stelle5/5 (1)
- C Programming for the Pc the Mac and the Arduino Microcontroller SystemDa EverandC Programming for the Pc the Mac and the Arduino Microcontroller SystemNessuna valutazione finora
- Aaj Jane Ki Zid Na Karo (Arijit Singh) PDFDocumento3 pagineAaj Jane Ki Zid Na Karo (Arijit Singh) PDFNitin SoniNessuna valutazione finora
- Ajj Din Chadheya (Love Aaj Kal)Documento3 pagineAjj Din Chadheya (Love Aaj Kal)Nitin SoniNessuna valutazione finora
- How To Make A Bamboo Flute (With Pictures) - WikiHowDocumento5 pagineHow To Make A Bamboo Flute (With Pictures) - WikiHowNitin SoniNessuna valutazione finora
- Harmonica Notes - Ye Shaam Mastani PDFDocumento1 paginaHarmonica Notes - Ye Shaam Mastani PDFNitin SoniNessuna valutazione finora
- RaagDocumento2 pagineRaagNitin SoniNessuna valutazione finora
- Link5-09 Acoustic ImpedanceDocumento4 pagineLink5-09 Acoustic ImpedanceNitin SoniNessuna valutazione finora
- Como Fazer Uma Flauta de Bambu - PDFDocumento12 pagineComo Fazer Uma Flauta de Bambu - PDFNitin SoniNessuna valutazione finora
- Payoji Maine Ram RatanDocumento1 paginaPayoji Maine Ram RatanMangesh BedareNessuna valutazione finora
- Payoji Maine Ram RatanDocumento1 paginaPayoji Maine Ram RatanMangesh BedareNessuna valutazione finora
- Instrument Creation Stations SEWER FLUTEDocumento1 paginaInstrument Creation Stations SEWER FLUTENitin Soni0% (1)
- C and Data Structures - BalaguruswamyDocumento52 pagineC and Data Structures - BalaguruswamyShrey Khokhawat100% (2)
- Flute Finger Hole LocationsDocumento3 pagineFlute Finger Hole LocationsNitin SoniNessuna valutazione finora
- Aicte NotificationDocumento16 pagineAicte NotificationjeojosephNessuna valutazione finora
- Yeh Sa Mastani Harmonica Notes Lessons | Harmonica ArenaDocumento1 paginaYeh Sa Mastani Harmonica Notes Lessons | Harmonica ArenaNitin SoniNessuna valutazione finora
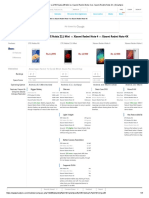
- Xiaomi Redmi Pro Vs Xiaomi Redmi Note 3 Vs Lenovo K6 Power Vs Lenovo K6 Note - SmartprixDocumento4 pagineXiaomi Redmi Pro Vs Xiaomi Redmi Note 3 Vs Lenovo K6 Power Vs Lenovo K6 Note - SmartprixNitin SoniNessuna valutazione finora
- MKS-II PlanDocumento2 pagineMKS-II PlanNitin SoniNessuna valutazione finora
- ZTE Nubia N1 Vs ZTE Nubia Z11 Mini Vs Xiaomi Redmi Note 4 Vs Xiaomi Redmi Note 4X - SmartprixDocumento5 pagineZTE Nubia N1 Vs ZTE Nubia Z11 Mini Vs Xiaomi Redmi Note 4 Vs Xiaomi Redmi Note 4X - SmartprixNitin SoniNessuna valutazione finora
- CLTKR Qrqftrrttffie:: Ffi - FfimkffiffiDocumento4 pagineCLTKR Qrqftrrttffie:: Ffi - FfimkffiffiNitin SoniNessuna valutazione finora
- Mayo ClinicDocumento48 pagineMayo ClinicAbdul RazzaqNessuna valutazione finora
- 2017 Tithi Calendar PDFDocumento14 pagine2017 Tithi Calendar PDFEr Nayan PithadiyaNessuna valutazione finora
- ECE 320 Spring 2004Documento142 pagineECE 320 Spring 2004Nitin SoniNessuna valutazione finora
- SCT FormulasDocumento1 paginaSCT FormulasNitin SoniNessuna valutazione finora
- AICTE Invites Proposals On Research & Institutional Development (RID) News AICTE Invites Proposals On Research & Institutional Development (RID)Documento5 pagineAICTE Invites Proposals On Research & Institutional Development (RID) News AICTE Invites Proposals On Research & Institutional Development (RID)Nitin SoniNessuna valutazione finora
- RC Transfer Process, Fees, Documents, Forms To Buy Sell Used CarDocumento3 pagineRC Transfer Process, Fees, Documents, Forms To Buy Sell Used CarNitin SoniNessuna valutazione finora
- Research Proposal DSTDocumento10 pagineResearch Proposal DSTNitin SoniNessuna valutazione finora
- Causes and Types of EarthquakesDocumento6 pagineCauses and Types of EarthquakesNitin SoniNessuna valutazione finora
- Maruti ZEN PDFDocumento103 pagineMaruti ZEN PDFNitin SoniNessuna valutazione finora
- Research Proposal DSTDocumento10 pagineResearch Proposal DSTNitin SoniNessuna valutazione finora
- Delay Using 8051 TimerDocumento6 pagineDelay Using 8051 TimerNitin SoniNessuna valutazione finora
- Avr TutorialDocumento111 pagineAvr Tutoriallabirint10100% (7)
- Sausanil: ResumeDocumento1 paginaSausanil: ResumeMagician S C SinhaNessuna valutazione finora
- Crushing & Reduction Equipment GuideDocumento6 pagineCrushing & Reduction Equipment Guidejeevan scplNessuna valutazione finora
- P34x EN MD M96 V35+V70 Incl P341Documento163 pagineP34x EN MD M96 V35+V70 Incl P341tandin.t6393Nessuna valutazione finora
- POD23S1C22190078Documento2 paginePOD23S1C22190078Sai KarthikNessuna valutazione finora
- Turbine Gland Steam CondenserDocumento4 pagineTurbine Gland Steam CondenserSai Swaroop100% (1)
- Question: Use QGIS With Example Pictures/drawings/sketches ExplainDocumento3 pagineQuestion: Use QGIS With Example Pictures/drawings/sketches ExplaintahaNessuna valutazione finora
- Canon+EOS+R8+BrochureDocumento21 pagineCanon+EOS+R8+BrochureDenPaulNessuna valutazione finora
- Script For Video InterviewDocumento2 pagineScript For Video InterviewRojakBusukNessuna valutazione finora
- VX400s LED Display Controller User ManualDocumento33 pagineVX400s LED Display Controller User ManualAlam PereyraNessuna valutazione finora
- 3.2. SurveyCTO Quick Start - Desktop With WorkspacesDocumento22 pagine3.2. SurveyCTO Quick Start - Desktop With WorkspacesDominique KasongoNessuna valutazione finora
- Greener Energy With Syntek SolarDocumento21 pagineGreener Energy With Syntek SolarirvanNessuna valutazione finora
- Naylor 1974Documento18 pagineNaylor 1974Mario Colil BenaventeNessuna valutazione finora
- Father of Indonesian EducationDocumento9 pagineFather of Indonesian EducationFarah Fatimatuz ZahraNessuna valutazione finora
- Abm Principles of Marketing Module 6 9Documento10 pagineAbm Principles of Marketing Module 6 9Trixie GallanoNessuna valutazione finora
- Notice Regarding Cusco Sport-R Suspension CoiloversDocumento2 pagineNotice Regarding Cusco Sport-R Suspension CoiloversJaciel LMNessuna valutazione finora
- Caja de Piso Ref 25249-FBADocumento4 pagineCaja de Piso Ref 25249-FBACristianDuarteSandovalNessuna valutazione finora
- Audiocodes Enabling Technology Products Smartworks™ LD SeriesDocumento2 pagineAudiocodes Enabling Technology Products Smartworks™ LD SeriesvspuriNessuna valutazione finora
- Manuel Movi-C Version Compact (2 Files Merged)Documento780 pagineManuel Movi-C Version Compact (2 Files Merged)mehdiNessuna valutazione finora
- CCNA Discovery DSDocumento2 pagineCCNA Discovery DSkovach84Nessuna valutazione finora
- Worldlink For All ClassroomsDocumento9 pagineWorldlink For All ClassroomsqorchianwarNessuna valutazione finora
- Influenceof ICTin Mathematics TeachingDocumento6 pagineInfluenceof ICTin Mathematics TeachingGrasya M.Nessuna valutazione finora
- Welcome To Metro by T-Mobile's: Premium Handset Protection (PHP)Documento14 pagineWelcome To Metro by T-Mobile's: Premium Handset Protection (PHP)Signora SauerNessuna valutazione finora
- Alpinevilla (Layouts & Costings)Documento16 pagineAlpinevilla (Layouts & Costings)rajnish kumarNessuna valutazione finora
- Monique MariscalDocumento2 pagineMonique Mariscalapi-459378045Nessuna valutazione finora
- U1 PDFDocumento20 pagineU1 PDFFarah AlhamadNessuna valutazione finora
- Network Optimization Equipments 01Documento27 pagineNetwork Optimization Equipments 01Rami Abu AlhigaNessuna valutazione finora
- SCANPUMP CANTILEVER PUMP FV 50 HzDocumento2 pagineSCANPUMP CANTILEVER PUMP FV 50 Hzhesam zoljalaliNessuna valutazione finora
- Automated Sign Language InterpreterDocumento5 pagineAutomated Sign Language Interpretersruthi 98Nessuna valutazione finora
- 2020 Media Strategy Report: Insights From The WARC Media AwardsDocumento53 pagine2020 Media Strategy Report: Insights From The WARC Media AwardsShachin ShibiNessuna valutazione finora
- 9e Turbine Gea16035b 9e GT HRDocumento1 pagina9e Turbine Gea16035b 9e GT HRFedor Bancoff.Nessuna valutazione finora