Potrebbero piacerti anche
- The Yellow House: A Memoir (2019 National Book Award Winner)Da EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Valutazione: 4 su 5 stelle4/5 (98)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDa EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeValutazione: 4 su 5 stelle4/5 (5795)
- Shoe Dog: A Memoir by the Creator of NikeDa EverandShoe Dog: A Memoir by the Creator of NikeValutazione: 4.5 su 5 stelle4.5/5 (537)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDa EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureValutazione: 4.5 su 5 stelle4.5/5 (474)
- Grit: The Power of Passion and PerseveranceDa EverandGrit: The Power of Passion and PerseveranceValutazione: 4 su 5 stelle4/5 (588)
- On Fire: The (Burning) Case for a Green New DealDa EverandOn Fire: The (Burning) Case for a Green New DealValutazione: 4 su 5 stelle4/5 (74)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDa EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryValutazione: 3.5 su 5 stelle3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDa EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceValutazione: 4 su 5 stelle4/5 (895)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDa EverandNever Split the Difference: Negotiating As If Your Life Depended On ItValutazione: 4.5 su 5 stelle4.5/5 (838)
- The Little Book of Hygge: Danish Secrets to Happy LivingDa EverandThe Little Book of Hygge: Danish Secrets to Happy LivingValutazione: 3.5 su 5 stelle3.5/5 (400)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDa EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersValutazione: 4.5 su 5 stelle4.5/5 (345)
- The Unwinding: An Inner History of the New AmericaDa EverandThe Unwinding: An Inner History of the New AmericaValutazione: 4 su 5 stelle4/5 (45)
- Team of Rivals: The Political Genius of Abraham LincolnDa EverandTeam of Rivals: The Political Genius of Abraham LincolnValutazione: 4.5 su 5 stelle4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDa EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyValutazione: 3.5 su 5 stelle3.5/5 (2259)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDa EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaValutazione: 4.5 su 5 stelle4.5/5 (266)
- The Emperor of All Maladies: A Biography of CancerDa EverandThe Emperor of All Maladies: A Biography of CancerValutazione: 4.5 su 5 stelle4.5/5 (271)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDa EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreValutazione: 4 su 5 stelle4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Da EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Valutazione: 4.5 su 5 stelle4.5/5 (121)
- Her Body and Other Parties: StoriesDa EverandHer Body and Other Parties: StoriesValutazione: 4 su 5 stelle4/5 (821)
- Lesson Plan ComsumerismDocumento6 pagineLesson Plan ComsumerismMan Eugenia50% (4)
- Gender InequalityDocumento9 pagineGender InequalityRhzNessuna valutazione finora
- The Evolution of Management TheoryDocumento49 pagineThe Evolution of Management TheoryAnjali MeharaNessuna valutazione finora
- Pal and Lisa Senior Secondary School Senior Five End of Term Two ExaminationsDocumento3 paginePal and Lisa Senior Secondary School Senior Five End of Term Two ExaminationsAthiyo MartinNessuna valutazione finora
- Potential Application of Orange Peel (OP) As An Eco-Friendly Adsorbent For Textile Dyeing EffluentsDocumento13 paginePotential Application of Orange Peel (OP) As An Eco-Friendly Adsorbent For Textile Dyeing EffluentsAnoif Naputo AidnamNessuna valutazione finora
- Đề Thi Tham Khảo (Đề thi có 5 trang) : 6: The flood victims 7: Many 8Documento7 pagineĐề Thi Tham Khảo (Đề thi có 5 trang) : 6: The flood victims 7: Many 8Quang Đặng HồngNessuna valutazione finora
- Culvert Design Write UpDocumento8 pagineCulvert Design Write UpifylasyNessuna valutazione finora
- Artificial Intelligence Is Branch of Computer Science Dealing With The Simulation of Intelligent Behavior in ComputersDocumento2 pagineArtificial Intelligence Is Branch of Computer Science Dealing With The Simulation of Intelligent Behavior in ComputersMuhammad Zaheer AnwarNessuna valutazione finora
- Partnerships Program For Education and Training (PAEC)Documento6 paginePartnerships Program For Education and Training (PAEC)LeslieNessuna valutazione finora
- Problem Solving and Algorithms: Problems, Solutions, and ToolsDocumento12 pagineProblem Solving and Algorithms: Problems, Solutions, and ToolsskarthikpriyaNessuna valutazione finora
- Compiled H.W - Class 10th-1Documento3 pagineCompiled H.W - Class 10th-1Sree KalaNessuna valutazione finora
- Learn C++ Programming LanguageDocumento322 pagineLearn C++ Programming LanguageAli Eb100% (8)
- 009 Installation of Pumps Risk AssessmentDocumento2 pagine009 Installation of Pumps Risk Assessmentgangadharan000100% (13)
- Prospectus For Admission Into Postgraduate Programs at BUET April-2013Documento6 pagineProspectus For Admission Into Postgraduate Programs at BUET April-2013missilemissionNessuna valutazione finora
- Augmented FeedbackDocumento54 pagineAugmented FeedbackAhmad KhuwarizmyNessuna valutazione finora
- 21st Cent Lit DLP KimDocumento7 pagine21st Cent Lit DLP KimKim BandolaNessuna valutazione finora
- KRAWIEC, Representations of Monastic Clothing in Late AntiquityDocumento27 pagineKRAWIEC, Representations of Monastic Clothing in Late AntiquityDejan MitreaNessuna valutazione finora
- Stepping Stones Grade 4 ScopeDocumento2 pagineStepping Stones Grade 4 ScopeGretchen BensonNessuna valutazione finora
- Lp-7 2019-Ratio and ProportionDocumento5 pagineLp-7 2019-Ratio and Proportionroy c. diocampoNessuna valutazione finora
- Chapter 17Documento78 pagineChapter 17Romar PanopioNessuna valutazione finora
- SWAY GuideDocumento16 pagineSWAY Guide63456 touristaNessuna valutazione finora
- JurnalDocumento24 pagineJurnaltsania rahmaNessuna valutazione finora
- Corrosion of Iron Lab Writeup Julia GillespieDocumento4 pagineCorrosion of Iron Lab Writeup Julia Gillespieapi-344957036Nessuna valutazione finora
- Chapter - 5 Theory of Consumer BehaviourDocumento30 pagineChapter - 5 Theory of Consumer BehaviourpoojNessuna valutazione finora
- Gear Whine Prediction With CAE For AAMDocumento6 pagineGear Whine Prediction With CAE For AAMSanjay DeshpandeNessuna valutazione finora
- Reference GuideDocumento3 pagineReference GuideStudentforiNessuna valutazione finora
- What Are The Subjects Which Come in UPSC Engineering Services - Electronics - Communication - ExamDocumento2 pagineWhat Are The Subjects Which Come in UPSC Engineering Services - Electronics - Communication - ExamVikas ChandraNessuna valutazione finora
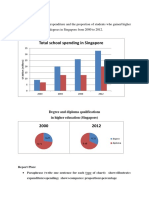
- Total School Spending in Singapore: Task 1 020219Documento6 pagineTotal School Spending in Singapore: Task 1 020219viper_4554Nessuna valutazione finora
- CPCCCM2006 - Learner Guide V1.0Documento89 pagineCPCCCM2006 - Learner Guide V1.0Sid SharmaNessuna valutazione finora