Potrebbero piacerti anche
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDa EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryValutazione: 3.5 su 5 stelle3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Da EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Valutazione: 4.5 su 5 stelle4.5/5 (119)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDa EverandNever Split the Difference: Negotiating As If Your Life Depended On ItValutazione: 4.5 su 5 stelle4.5/5 (838)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDa EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaValutazione: 4.5 su 5 stelle4.5/5 (265)
- The Little Book of Hygge: Danish Secrets to Happy LivingDa EverandThe Little Book of Hygge: Danish Secrets to Happy LivingValutazione: 3.5 su 5 stelle3.5/5 (399)
- Grit: The Power of Passion and PerseveranceDa EverandGrit: The Power of Passion and PerseveranceValutazione: 4 su 5 stelle4/5 (587)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDa EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyValutazione: 3.5 su 5 stelle3.5/5 (2219)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDa EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeValutazione: 4 su 5 stelle4/5 (5794)
- Team of Rivals: The Political Genius of Abraham LincolnDa EverandTeam of Rivals: The Political Genius of Abraham LincolnValutazione: 4.5 su 5 stelle4.5/5 (234)
- Shoe Dog: A Memoir by the Creator of NikeDa EverandShoe Dog: A Memoir by the Creator of NikeValutazione: 4.5 su 5 stelle4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerDa EverandThe Emperor of All Maladies: A Biography of CancerValutazione: 4.5 su 5 stelle4.5/5 (271)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDa EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreValutazione: 4 su 5 stelle4/5 (1090)
- Her Body and Other Parties: StoriesDa EverandHer Body and Other Parties: StoriesValutazione: 4 su 5 stelle4/5 (821)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDa EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersValutazione: 4.5 su 5 stelle4.5/5 (344)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDa EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceValutazione: 4 su 5 stelle4/5 (890)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDa EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureValutazione: 4.5 su 5 stelle4.5/5 (474)
- The Unwinding: An Inner History of the New AmericaDa EverandThe Unwinding: An Inner History of the New AmericaValutazione: 4 su 5 stelle4/5 (45)
- The Yellow House: A Memoir (2019 National Book Award Winner)Da EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Valutazione: 4 su 5 stelle4/5 (98)
- On Fire: The (Burning) Case for a Green New DealDa EverandOn Fire: The (Burning) Case for a Green New DealValutazione: 4 su 5 stelle4/5 (73)
- OWASP ZAP Getting Started GuideDocumento10 pagineOWASP ZAP Getting Started GuideNobitaJuniorNessuna valutazione finora
- Operating System VirtualizationDocumento13 pagineOperating System VirtualizationSachin JainNessuna valutazione finora
- Agile Extension To The Babok GuideDocumento108 pagineAgile Extension To The Babok GuidePatricia RamírezNessuna valutazione finora
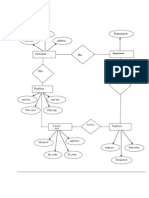
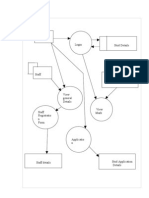
- Furniture Management SystemDocumento27 pagineFurniture Management Systemanadhan45% (11)
- Manage Requirements & Bank SystemsDocumento24 pagineManage Requirements & Bank Systemsanadhan33% (3)
- Online ShoppingDocumento19 pagineOnline ShoppinganadhanNessuna valutazione finora
- Rss Feeder DocumentDocumento40 pagineRss Feeder DocumentanadhanNessuna valutazione finora
- Call Center ER DiagramDocumento1 paginaCall Center ER DiagramanadhanNessuna valutazione finora
- Final Inventory DocumentDocumento26 pagineFinal Inventory DocumentanadhanNessuna valutazione finora
- Concern Detail Database Tables Finyear Field Name Field Type SizeDocumento10 pagineConcern Detail Database Tables Finyear Field Name Field Type SizeanadhanNessuna valutazione finora
- Content Based Image RetrievalDocumento86 pagineContent Based Image RetrievalanadhanNessuna valutazione finora
- Rss Feeder DocumentDocumento40 pagineRss Feeder DocumentanadhanNessuna valutazione finora
- VN M IntroductionDocumento5 pagineVN M IntroductionRahul ChopadeNessuna valutazione finora
- SynopsisDocumento2 pagineSynopsisanadhanNessuna valutazione finora
- 1.1 Organisation Profile: "DAFFODILLS INDIA", Established in The Year 2006.they Are LocatedDocumento31 pagine1.1 Organisation Profile: "DAFFODILLS INDIA", Established in The Year 2006.they Are LocatedanadhanNessuna valutazione finora
- Final Inventory DocumentDocumento26 pagineFinal Inventory DocumentanadhanNessuna valutazione finora
- WEBSITE DocumentDocumento50 pagineWEBSITE DocumentanadhanNessuna valutazione finora
- Abstract Resume BuilderDocumento1 paginaAbstract Resume Builderanadhan100% (1)
- College Website DFDDocumento1 paginaCollege Website DFDanadhanNessuna valutazione finora
- SynopsisDocumento2 pagineSynopsisanadhanNessuna valutazione finora
- WEBSITE DocumentDocumento50 pagineWEBSITE DocumentanadhanNessuna valutazione finora
- Compress Large Databases with Column StorageDocumento31 pagineCompress Large Databases with Column StorageanadhanNessuna valutazione finora
- ERP Industrial ManagementDocumento25 pagineERP Industrial ManagementanadhanNessuna valutazione finora
- SynopsisDocumento2 pagineSynopsisanadhanNessuna valutazione finora
- Compress Large Databases with Column StorageDocumento31 pagineCompress Large Databases with Column StorageanadhanNessuna valutazione finora
- Courier ManagementDocumento9 pagineCourier ManagementanadhanNessuna valutazione finora
- AutomationDocumento2 pagineAutomationanadhanNessuna valutazione finora
- Compress Large Databases with Column StorageDocumento31 pagineCompress Large Databases with Column StorageanadhanNessuna valutazione finora
- Compress Large Databases with Column StorageDocumento31 pagineCompress Large Databases with Column StorageanadhanNessuna valutazione finora
- Office Automation Management SystemDocumento32 pagineOffice Automation Management SystemanadhanNessuna valutazione finora
- Office Automation Management SystemDocumento32 pagineOffice Automation Management SystemanadhanNessuna valutazione finora
- ERP Industrial ManagementDocumento25 pagineERP Industrial ManagementanadhanNessuna valutazione finora
- One Stop Shop For Buying, Selling & Renting BooksDocumento38 pagineOne Stop Shop For Buying, Selling & Renting Booksapi-402842914Nessuna valutazione finora
- Apple Strategic Audit AnalysisDocumento14 pagineApple Strategic Audit AnalysisShaff Mubashir BhattiNessuna valutazione finora
- CS6310 A4 Architecture - Design Fall2022Documento8 pagineCS6310 A4 Architecture - Design Fall2022Phillip DieppaNessuna valutazione finora
- Chapter 6 HomeworkDocumento7 pagineChapter 6 HomeworkSushmitha YallaNessuna valutazione finora
- Data Structure Preliminaries, Array and Linked ListDocumento9 pagineData Structure Preliminaries, Array and Linked ListAntonio RogersNessuna valutazione finora
- Din Electric Connectors M12 InterfaceDocumento2 pagineDin Electric Connectors M12 InterfaceAndre JuandaNessuna valutazione finora
- HUAWEI SMC2.0 Lab GuideDocumento92 pagineHUAWEI SMC2.0 Lab Guidebaccari taoufikNessuna valutazione finora
- Stock Coal and Limestone Feed Systems: Powering Industry ForwardDocumento12 pagineStock Coal and Limestone Feed Systems: Powering Industry ForwardAchmad Nidzar AlifNessuna valutazione finora
- Week10-11-Access Control Models-PoliciesDocumento33 pagineWeek10-11-Access Control Models-Policiesmahtab mahtabNessuna valutazione finora
- Kubernetes As A Service at VCCloudDocumento27 pagineKubernetes As A Service at VCCloudKiên Trần TrungNessuna valutazione finora
- Integrating Computational Chemistry (Molecular Modeling) Into The General Chemistry CurriculumDocumento12 pagineIntegrating Computational Chemistry (Molecular Modeling) Into The General Chemistry CurriculumDevi Vianisa UliviaNessuna valutazione finora
- Extract PunoDocumento375 pagineExtract PunoHugoAñamuroNessuna valutazione finora
- Epson Ecotank l3256Documento2 pagineEpson Ecotank l3256ioanNessuna valutazione finora
- Verilog Operators ManualDocumento27 pagineVerilog Operators Manualnik250890Nessuna valutazione finora
- ROOT Basic Course PDFDocumento374 pagineROOT Basic Course PDFjoao da silvaNessuna valutazione finora
- FBL1N - Vendor HistoryDocumento13 pagineFBL1N - Vendor HistorytserafimNessuna valutazione finora
- Simulate ONTAP 8.2 Step-by-Step Installation (Nau-Final) PDFDocumento53 pagineSimulate ONTAP 8.2 Step-by-Step Installation (Nau-Final) PDFKishore ChowdaryNessuna valutazione finora
- AWL Axes Management (En SW nf0)Documento90 pagineAWL Axes Management (En SW nf0)IvanNessuna valutazione finora
- Auto Hematology AnalyzerDocumento1 paginaAuto Hematology AnalyzersaidaNessuna valutazione finora
- Resource Management PlanDocumento9 pagineResource Management PlanAsghar MughalNessuna valutazione finora
- Engineering Is An Art When It's Learnt Right: Me& NinoDocumento5 pagineEngineering Is An Art When It's Learnt Right: Me& NinoMohit SinghNessuna valutazione finora
- Solving PDEs using radial basis functionsDocumento10 pagineSolving PDEs using radial basis functionsHamid MojiryNessuna valutazione finora
- Chi Patrat PDFDocumento14 pagineChi Patrat PDFvNessuna valutazione finora
- Under The StarsDocumento185 pagineUnder The StarsMatthew TempleNessuna valutazione finora
- MC-2 SERIES OPERATION MANUALDocumento21 pagineMC-2 SERIES OPERATION MANUALsergio paulo chavesNessuna valutazione finora
- FortiCloudReport386 PDFDocumento11 pagineFortiCloudReport386 PDFMi S.Nessuna valutazione finora