Potrebbero piacerti anche
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDa EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeValutazione: 4 su 5 stelle4/5 (5794)
- Technologies in The HP BladesSystem c7000 EnclosureDocumento35 pagineTechnologies in The HP BladesSystem c7000 EnclosureKasu_777Nessuna valutazione finora
- The Yellow House: A Memoir (2019 National Book Award Winner)Da EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Valutazione: 4 su 5 stelle4/5 (98)
- HP ProLiant C-Class Server BladesDocumento25 pagineHP ProLiant C-Class Server BladesKasu_777Nessuna valutazione finora
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDa EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryValutazione: 3.5 su 5 stelle3.5/5 (231)
- Quantum Gis User GuideDocumento169 pagineQuantum Gis User GuideKasu_777Nessuna valutazione finora
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDa EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceValutazione: 4 su 5 stelle4/5 (895)
- Quantum GIS User and Installation Guide V - 091Documento189 pagineQuantum GIS User and Installation Guide V - 091Kasu_777Nessuna valutazione finora
- The Little Book of Hygge: Danish Secrets to Happy LivingDa EverandThe Little Book of Hygge: Danish Secrets to Happy LivingValutazione: 3.5 su 5 stelle3.5/5 (400)
- Manual QgisDocumento76 pagineManual QgisJuliano CândidoNessuna valutazione finora
- Shoe Dog: A Memoir by the Creator of NikeDa EverandShoe Dog: A Memoir by the Creator of NikeValutazione: 4.5 su 5 stelle4.5/5 (537)
- On Information and Knowledge Representation in The BrainDocumento6 pagineOn Information and Knowledge Representation in The BrainKasu_777Nessuna valutazione finora
- Never Split the Difference: Negotiating As If Your Life Depended On ItDa EverandNever Split the Difference: Negotiating As If Your Life Depended On ItValutazione: 4.5 su 5 stelle4.5/5 (838)
- Mapping GPS Points With QuantumDocumento9 pagineMapping GPS Points With QuantumKasu_777Nessuna valutazione finora
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDa EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureValutazione: 4.5 su 5 stelle4.5/5 (474)
- 321321Documento154 pagine321321Kasu_777Nessuna valutazione finora
- Grit: The Power of Passion and PerseveranceDa EverandGrit: The Power of Passion and PerseveranceValutazione: 4 su 5 stelle4/5 (588)
- L TEX Maths and Graphics: A Tim Love July 27, 2006Documento16 pagineL TEX Maths and Graphics: A Tim Love July 27, 2006Jessé OliveiraNessuna valutazione finora
- HP Bladesystem Matrix Solution OverviewDocumento7 pagineHP Bladesystem Matrix Solution OverviewKasu_777Nessuna valutazione finora
- The Emperor of All Maladies: A Biography of CancerDa EverandThe Emperor of All Maladies: A Biography of CancerValutazione: 4.5 su 5 stelle4.5/5 (271)
- Acc Velo DistDocumento9 pagineAcc Velo DistKasu_777Nessuna valutazione finora
- On Fire: The (Burning) Case for a Green New DealDa EverandOn Fire: The (Burning) Case for a Green New DealValutazione: 4 su 5 stelle4/5 (74)
- GIS Feb05 - GPS - Principles - 2004Documento24 pagineGIS Feb05 - GPS - Principles - 2004Kasu_777Nessuna valutazione finora
- Team of Rivals: The Political Genius of Abraham LincolnDa EverandTeam of Rivals: The Political Genius of Abraham LincolnValutazione: 4.5 su 5 stelle4.5/5 (234)
- HP Bladesystem: An Adaptive Infrastructure Out of The BoxDocumento8 pagineHP Bladesystem: An Adaptive Infrastructure Out of The BoxKasu_777Nessuna valutazione finora
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDa EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaValutazione: 4.5 su 5 stelle4.5/5 (266)
- Latex AdvancedDocumento23 pagineLatex AdvancedKasu_777Nessuna valutazione finora
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDa EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersValutazione: 4.5 su 5 stelle4.5/5 (344)
- Kelompok 6 (PLS Algorithm)Documento98 pagineKelompok 6 (PLS Algorithm)Hadid WirawanNessuna valutazione finora
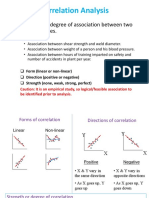
- Correlation Analysis: Concept, Interpretation, and ReportingDocumento5 pagineCorrelation Analysis: Concept, Interpretation, and ReportingRoman AhmadNessuna valutazione finora
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDa EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyValutazione: 3.5 su 5 stelle3.5/5 (2259)
- Kelola, 13 - JIMKES 2021 Vol 9 No 1 YuliaDocumento4 pagineKelola, 13 - JIMKES 2021 Vol 9 No 1 YuliamoiNessuna valutazione finora
- Case Problem ForecastingDocumento13 pagineCase Problem ForecastingSuresh KumarNessuna valutazione finora
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDa EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreValutazione: 4 su 5 stelle4/5 (1090)
- Chapter 9: Serial CorrelationDocumento7 pagineChapter 9: Serial CorrelationEmberlaineNessuna valutazione finora
- Principles of Model BuildingDocumento75 paginePrinciples of Model BuildingWingtung HoNessuna valutazione finora
- Regression ValidationDocumento3 pagineRegression Validationharrison9Nessuna valutazione finora
- The Unwinding: An Inner History of the New AmericaDa EverandThe Unwinding: An Inner History of the New AmericaValutazione: 4 su 5 stelle4/5 (45)
- Homework 3Documento7 pagineHomework 3Alexis R. CamargoNessuna valutazione finora
- Demand Estimation and Forecasting: Managerial Economics, 2eDocumento13 pagineDemand Estimation and Forecasting: Managerial Economics, 2eMandira PrakashNessuna valutazione finora
- SVM and Linear Regression Interview Questions 1gwndpDocumento23 pagineSVM and Linear Regression Interview Questions 1gwndpASHISH KUMAR MAJHINessuna valutazione finora
- Time Series Analysis Cheat SheetDocumento2 pagineTime Series Analysis Cheat SheetMNHNessuna valutazione finora
- As of Oct 24, 2017: Seppo Pynn Onen Econometrics IDocumento27 pagineAs of Oct 24, 2017: Seppo Pynn Onen Econometrics IMartinNessuna valutazione finora
- BUS 173 Final AssignmentDocumento7 pagineBUS 173 Final AssignmentDinha ChowdhuryNessuna valutazione finora
- 000+ +curriculum+ +Complete+Data+Science+and+Machine+Learning+Using+PythonDocumento10 pagine000+ +curriculum+ +Complete+Data+Science+and+Machine+Learning+Using+PythonVishal MudgalNessuna valutazione finora
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Da EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Valutazione: 4.5 su 5 stelle4.5/5 (121)
- Ensemble Learning Algorithms With Python Mini CourseDocumento20 pagineEnsemble Learning Algorithms With Python Mini CourseJihene BenchohraNessuna valutazione finora
- Results Binomial Logistic Regression: Model Deviance AIC RDocumento7 pagineResults Binomial Logistic Regression: Model Deviance AIC RSmit MangeNessuna valutazione finora
- Business Report: Predictive ModellingDocumento37 pagineBusiness Report: Predictive Modellinghepzi selvam100% (1)
- Multivariate and Multilevel Data Analysis Using SPSS, Amos, Smartpls and MplusDocumento8 pagineMultivariate and Multilevel Data Analysis Using SPSS, Amos, Smartpls and MplusMuhammad Asad AliNessuna valutazione finora
- Ridge Regression: Patrick BrehenyDocumento22 pagineRidge Regression: Patrick BrehenyDjordje MiladinovicNessuna valutazione finora
- Study of Anova TestDocumento16 pagineStudy of Anova Testshilpasingh1297Nessuna valutazione finora
- Pone 0153487 s012Documento4 paginePone 0153487 s012radha satiNessuna valutazione finora
- 1108 2910 1 SMDocumento8 pagine1108 2910 1 SMsri wahyuniNessuna valutazione finora
- Using R To Teach EconometricsDocumento15 pagineUsing R To Teach Econometricsjojo liNessuna valutazione finora
- U.S Medical Insurance Costs: Wesley F. MaiaDocumento30 pagineU.S Medical Insurance Costs: Wesley F. MaiaWesley MaiaNessuna valutazione finora
- CH 4 Correlation AnalysisDocumento12 pagineCH 4 Correlation AnalysisPoint BlankNessuna valutazione finora
- Her Body and Other Parties: StoriesDa EverandHer Body and Other Parties: StoriesValutazione: 4 su 5 stelle4/5 (821)
- Parameter Lower 95.0% Confidence Limit Point Estimate Upper 95.0% Confidence LimitDocumento5 pagineParameter Lower 95.0% Confidence Limit Point Estimate Upper 95.0% Confidence LimitJoseNessuna valutazione finora
- ANOVAbDocumento4 pagineANOVAbMore BizumutimaNessuna valutazione finora
- Eviews User Guide 2Documento822 pagineEviews User Guide 2Rana Muhammad Arif KhanNessuna valutazione finora
- ML Ques Bank For 2nd Unit PDFDocumento5 pagineML Ques Bank For 2nd Unit PDFshreyashNessuna valutazione finora
- REVISION 2 (Solution - Test Yourself Topic 8)Documento5 pagineREVISION 2 (Solution - Test Yourself Topic 8)nurauniatiqah49Nessuna valutazione finora