Potrebbero piacerti anche
- Cognitive Capitalism or CognitionDocumento28 pagineCognitive Capitalism or CognitionΑλέξανδρος ΓεωργίουNessuna valutazione finora
- The performativity of code: exploring cultures of software circulationDocumento24 pagineThe performativity of code: exploring cultures of software circulationΑλέξανδρος ΓεωργίουNessuna valutazione finora
- Facebook's Rise of Affirmative DiscourseDocumento10 pagineFacebook's Rise of Affirmative DiscourseΑλέξανδρος ΓεωργίουNessuna valutazione finora
- Böhm Steffen Value Marx Free Labour Rent and Primitive' Accumulation FacebookDocumento18 pagineBöhm Steffen Value Marx Free Labour Rent and Primitive' Accumulation Facebook6cjMNzTZIsNessuna valutazione finora
- PASQUIANELLI, Matteo - Google Page Rank AlgorithmDocumento12 paginePASQUIANELLI, Matteo - Google Page Rank AlgorithmadenserffNessuna valutazione finora
- Theory Research at GoogleDocumento19 pagineTheory Research at GoogleΑλέξανδρος ΓεωργίουNessuna valutazione finora
- p1 HenzingerDocumento3 paginep1 HenzingerΑλέξανδρος ΓεωργίουNessuna valutazione finora
- A Netporn Studies ReaderDocumento306 pagineA Netporn Studies ReaderMarlon Barrios Solano0% (1)
- Boudourides Graphs AsDocumento9 pagineBoudourides Graphs AsΑλέξανδρος ΓεωργίουNessuna valutazione finora
- p1022 HenzingerDocumento5 paginep1022 HenzingerΑλέξανδρος ΓεωργίουNessuna valutazione finora
- Pasquinelli Immaterial Civil WarDocumento13 paginePasquinelli Immaterial Civil WarΑλέξανδρος ΓεωργίουNessuna valutazione finora
- Notes On The Edu-Factory and Cognitive Capitalism: Silvia Federici George CaffentzisDocumento8 pagineNotes On The Edu-Factory and Cognitive Capitalism: Silvia Federici George Caffentzisverox2010Nessuna valutazione finora
- p284 HenzingerDocumento8 paginep284 HenzingerΑλέξανδρος ΓεωργίουNessuna valutazione finora
- Pasquinelli Radical MachinesDocumento5 paginePasquinelli Radical MachinesΑλέξανδρος ΓεωργίουNessuna valutazione finora
- Rindermann and ThompsonDocumento11 pagineRindermann and ThompsonΑλέξανδρος ΓεωργίουNessuna valutazione finora
- Cognitive Capitalism or CognitionDocumento28 pagineCognitive Capitalism or CognitionΑλέξανδρος ΓεωργίουNessuna valutazione finora
- The New Articulation of Wages, Rent and Profit in Cognitive CapitalismDocumento12 pagineThe New Articulation of Wages, Rent and Profit in Cognitive CapitalismΑλέξανδρος ΓεωργίουNessuna valutazione finora
- Cyber MarxDocumento594 pagineCyber MarxmmmmpppppNessuna valutazione finora
- C. Vercellone, de La Subsunción Formal Al Intelecto GeneralDocumento24 pagineC. Vercellone, de La Subsunción Formal Al Intelecto GeneralfjmfjmNessuna valutazione finora
- Anchors in Shifting Sand The Primacy of MethodDocumento5 pagineAnchors in Shifting Sand The Primacy of MethodΑλέξανδρος ΓεωργίουNessuna valutazione finora
- Learning From Linked Open Data Usage Patterns MetricsDocumento8 pagineLearning From Linked Open Data Usage Patterns MetricsΑλέξανδρος ΓεωργίουNessuna valutazione finora
- Exploiting A Web of Semantic Data For Interpreting TablesDocumento8 pagineExploiting A Web of Semantic Data For Interpreting TablesΑλέξανδρος ΓεωργίουNessuna valutazione finora
- Towards A Philosophy of The Web RepresentationDocumento5 pagineTowards A Philosophy of The Web RepresentationΑλέξανδρος ΓεωργίουNessuna valutazione finora
- A Manifesto For Web SciencDocumento6 pagineA Manifesto For Web SciencΑλέξανδρος ΓεωργίουNessuna valutazione finora
- Turkalytics Analytics For Human ComputationDocumento10 pagineTurkalytics Analytics For Human ComputationΑλέξανδρος ΓεωργίουNessuna valutazione finora
- Equilibria and Efficiency Loss in Games On NetworksDocumento22 pagineEquilibria and Efficiency Loss in Games On NetworksΑλέξανδρος ΓεωργίουNessuna valutazione finora
- Behavior Change Support SystemsDocumento8 pagineBehavior Change Support SystemsΑλέξανδρος ΓεωργίουNessuna valutazione finora
- Actor Network TheoryDocumento22 pagineActor Network Theorylu_oshiroNessuna valutazione finora
- Worst Case Efficient Data StructuresDocumento134 pagineWorst Case Efficient Data StructuresΑλέξανδρος ΓεωργίουNessuna valutazione finora
- Shoe Dog: A Memoir by the Creator of NikeDa EverandShoe Dog: A Memoir by the Creator of NikeValutazione: 4.5 su 5 stelle4.5/5 (537)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDa EverandNever Split the Difference: Negotiating As If Your Life Depended On ItValutazione: 4.5 su 5 stelle4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDa EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureValutazione: 4.5 su 5 stelle4.5/5 (474)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDa EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeValutazione: 4 su 5 stelle4/5 (5783)
- Grit: The Power of Passion and PerseveranceDa EverandGrit: The Power of Passion and PerseveranceValutazione: 4 su 5 stelle4/5 (587)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDa EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceValutazione: 4 su 5 stelle4/5 (890)
- The Yellow House: A Memoir (2019 National Book Award Winner)Da EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Valutazione: 4 su 5 stelle4/5 (98)
- On Fire: The (Burning) Case for a Green New DealDa EverandOn Fire: The (Burning) Case for a Green New DealValutazione: 4 su 5 stelle4/5 (72)
- The Little Book of Hygge: Danish Secrets to Happy LivingDa EverandThe Little Book of Hygge: Danish Secrets to Happy LivingValutazione: 3.5 su 5 stelle3.5/5 (399)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDa EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryValutazione: 3.5 su 5 stelle3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnDa EverandTeam of Rivals: The Political Genius of Abraham LincolnValutazione: 4.5 su 5 stelle4.5/5 (234)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDa EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaValutazione: 4.5 su 5 stelle4.5/5 (265)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDa EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersValutazione: 4.5 su 5 stelle4.5/5 (344)
- The Emperor of All Maladies: A Biography of CancerDa EverandThe Emperor of All Maladies: A Biography of CancerValutazione: 4.5 su 5 stelle4.5/5 (271)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDa EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyValutazione: 3.5 su 5 stelle3.5/5 (2219)
- The Unwinding: An Inner History of the New AmericaDa EverandThe Unwinding: An Inner History of the New AmericaValutazione: 4 su 5 stelle4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDa EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreValutazione: 4 su 5 stelle4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Da EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Valutazione: 4.5 su 5 stelle4.5/5 (119)
- Her Body and Other Parties: StoriesDa EverandHer Body and Other Parties: StoriesValutazione: 4 su 5 stelle4/5 (821)
- PPMDB Schema For Version 1770.0001.0001 PDFDocumento106 paginePPMDB Schema For Version 1770.0001.0001 PDFGeorge AniborNessuna valutazione finora
- ANALYSIS AND DESIGN OF ONLINE ASSESSMENT INFORMATION SYSTEMDocumento10 pagineANALYSIS AND DESIGN OF ONLINE ASSESSMENT INFORMATION SYSTEMBarryNessuna valutazione finora
- CH 11Documento18 pagineCH 11Febri MonikaNessuna valutazione finora
- C# Architecture of ADODocumento5 pagineC# Architecture of ADOravatsinhsNessuna valutazione finora
- CTT102-Chapter 5-SQL PDFDocumento154 pagineCTT102-Chapter 5-SQL PDFsjkj klsjdfNessuna valutazione finora
- ACTIVITYDocumento5 pagineACTIVITYBungar, Daniel Luis, Edades.Nessuna valutazione finora
- AIA DQG IDQ Approach& Features v1.1Documento29 pagineAIA DQG IDQ Approach& Features v1.1AmarnathMaitiNessuna valutazione finora
- Types of E-Resources and Its Utilities in Library 9Documento9 pagineTypes of E-Resources and Its Utilities in Library 9SudhakarNessuna valutazione finora
- BS en 12952-4Documento22 pagineBS en 12952-4Nowshad AlamNessuna valutazione finora
- Vtu 5TH Sem Cse DBMS NotesDocumento35 pagineVtu 5TH Sem Cse DBMS NotesNeha Chinni67% (3)
- Resolving Many-to-Many RelationshipsDocumento15 pagineResolving Many-to-Many RelationshipsNaisha MehlaNessuna valutazione finora
- Knowledge Management in The Hybrid Work Era: Changes, Challenges, and OpportunitiesDocumento3 pagineKnowledge Management in The Hybrid Work Era: Changes, Challenges, and OpportunitiesRob ColdingNessuna valutazione finora
- Statement of Work For ABC HRMS ApplicationDocumento3 pagineStatement of Work For ABC HRMS ApplicationAditya SlathiaNessuna valutazione finora
- Updated200 Pega Interview QuestionsDocumento35 pagineUpdated200 Pega Interview QuestionsKamesh AnandNessuna valutazione finora
- Talend Activity Monitoring Console: User GuideDocumento40 pagineTalend Activity Monitoring Console: User GuideBhanu PrasadNessuna valutazione finora
- Data Modeling For MongoDB HobermanDocumento263 pagineData Modeling For MongoDB Hobermanluana y luna dureNessuna valutazione finora
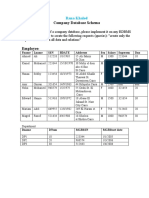
- Company Database Schema: Rana KhaledDocumento8 pagineCompany Database Schema: Rana KhaledRonna WNessuna valutazione finora
- Using Sessions and Session PersistenceDocumento52 pagineUsing Sessions and Session PersistenceRitesh KumarNessuna valutazione finora
- Dr. Chen's overview of database conceptsDocumento88 pagineDr. Chen's overview of database conceptsJenner Patrick Lopes BrasilNessuna valutazione finora
- Introduction To Pharmacoinformatics: DR Dzul Azri Mohamed Noor Dzulazri@usm - MyDocumento17 pagineIntroduction To Pharmacoinformatics: DR Dzul Azri Mohamed Noor Dzulazri@usm - MyLakshmanan ValliappanNessuna valutazione finora
- WLAS - CSS 12 - w3Documento11 pagineWLAS - CSS 12 - w3Rusty Ugay LumbresNessuna valutazione finora
- Midterm Exam Questions and AnswersDocumento21 pagineMidterm Exam Questions and AnswersAifha RamosNessuna valutazione finora
- Oracle Actualtests 1z0-071 Exam Dumps 2021-Apr-09 by Ian 124q VceDocumento12 pagineOracle Actualtests 1z0-071 Exam Dumps 2021-Apr-09 by Ian 124q VcejowbrowNessuna valutazione finora
- Week 03 High Level Dimensional ModelingDocumento9 pagineWeek 03 High Level Dimensional ModelingOuramdane SaoudiNessuna valutazione finora
- Data Privacy and ProtectionDocumento10 pagineData Privacy and Protectionkhuranahardikcr7Nessuna valutazione finora
- Chapter No.2 Database Design Using ER ModelDocumento50 pagineChapter No.2 Database Design Using ER ModelMonkey dragon10Nessuna valutazione finora
- ER diagram for IT training groupDocumento2 pagineER diagram for IT training grouphemarubini96Nessuna valutazione finora
- Database Administration & Management: Introduction To CourseDocumento20 pagineDatabase Administration & Management: Introduction To CourseTalal Ramzan GujjarNessuna valutazione finora
- Labsheet#2 - ERDDocumento2 pagineLabsheet#2 - ERDRuzaini A ArshahNessuna valutazione finora
- Backup ControlsDocumento12 pagineBackup ControlsabbiecdefgNessuna valutazione finora