Potrebbero piacerti anche
- Experiment 13: Memory Unit: Source CodeDocumento3 pagineExperiment 13: Memory Unit: Source Codechuck4301Nessuna valutazione finora
- Econ PE ProblemBkDocumento19 pagineEcon PE ProblemBkMustafa OmarNessuna valutazione finora
- Termtestw 021Documento5 pagineTermtestw 021chuck4301Nessuna valutazione finora
- Text TwistDocumento7 pagineText Twistchuck4301Nessuna valutazione finora
- The Yellow House: A Memoir (2019 National Book Award Winner)Da EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Valutazione: 4 su 5 stelle4/5 (98)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDa EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeValutazione: 4 su 5 stelle4/5 (5795)
- Shoe Dog: A Memoir by the Creator of NikeDa EverandShoe Dog: A Memoir by the Creator of NikeValutazione: 4.5 su 5 stelle4.5/5 (537)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDa EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureValutazione: 4.5 su 5 stelle4.5/5 (474)
- Grit: The Power of Passion and PerseveranceDa EverandGrit: The Power of Passion and PerseveranceValutazione: 4 su 5 stelle4/5 (588)
- On Fire: The (Burning) Case for a Green New DealDa EverandOn Fire: The (Burning) Case for a Green New DealValutazione: 4 su 5 stelle4/5 (74)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDa EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryValutazione: 3.5 su 5 stelle3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDa EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceValutazione: 4 su 5 stelle4/5 (895)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDa EverandNever Split the Difference: Negotiating As If Your Life Depended On ItValutazione: 4.5 su 5 stelle4.5/5 (838)
- The Little Book of Hygge: Danish Secrets to Happy LivingDa EverandThe Little Book of Hygge: Danish Secrets to Happy LivingValutazione: 3.5 su 5 stelle3.5/5 (400)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDa EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersValutazione: 4.5 su 5 stelle4.5/5 (345)
- The Unwinding: An Inner History of the New AmericaDa EverandThe Unwinding: An Inner History of the New AmericaValutazione: 4 su 5 stelle4/5 (45)
- Team of Rivals: The Political Genius of Abraham LincolnDa EverandTeam of Rivals: The Political Genius of Abraham LincolnValutazione: 4.5 su 5 stelle4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDa EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyValutazione: 3.5 su 5 stelle3.5/5 (2259)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDa EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaValutazione: 4.5 su 5 stelle4.5/5 (266)
- The Emperor of All Maladies: A Biography of CancerDa EverandThe Emperor of All Maladies: A Biography of CancerValutazione: 4.5 su 5 stelle4.5/5 (271)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDa EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreValutazione: 4 su 5 stelle4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Da EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Valutazione: 4.5 su 5 stelle4.5/5 (121)
- Her Body and Other Parties: StoriesDa EverandHer Body and Other Parties: StoriesValutazione: 4 su 5 stelle4/5 (821)
- SWI-Prolog-5 11 28Documento422 pagineSWI-Prolog-5 11 28floricaBNessuna valutazione finora
- I2P - PF - Quiz 3 and 4Documento8 pagineI2P - PF - Quiz 3 and 4adam iqbalNessuna valutazione finora
- Chip Dolby DecoderDocumento90 pagineChip Dolby Decoderjr1234Nessuna valutazione finora
- IBM AS400 RPG IV Training Course (Course Code OL86) - 2Documento24 pagineIBM AS400 RPG IV Training Course (Course Code OL86) - 2Ramana VaralaNessuna valutazione finora
- Ajp Micro-ProjectDocumento11 pagineAjp Micro-ProjectCO-352 Vedant Deshpande100% (1)
- Apoorva MehetreDocumento64 pagineApoorva MehetreApoorva MehetreNessuna valutazione finora
- AMD Athlon OPNs June 2003Documento4 pagineAMD Athlon OPNs June 2003Dragac CifraNessuna valutazione finora
- Activity Life CycleDocumento8 pagineActivity Life Cycletanveer MullaNessuna valutazione finora
- 1.5 Set - 1 - 1one - IT - Project - Presentation - 0901Documento47 pagine1.5 Set - 1 - 1one - IT - Project - Presentation - 0901Stephen Lloyd GeronaNessuna valutazione finora
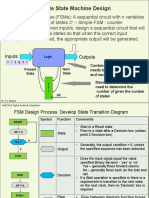
- Finite State Machine Design: Outputs InputsDocumento39 pagineFinite State Machine Design: Outputs InputsZulfiqar AliNessuna valutazione finora
- Java - How To Retrieve Data From SQL Server DB in Android - Stack OverflowDocumento7 pagineJava - How To Retrieve Data From SQL Server DB in Android - Stack Overflowbkk.prog2Nessuna valutazione finora
- Technology in Action Complete 9th Edition Evans Test BankDocumento20 pagineTechnology in Action Complete 9th Edition Evans Test BankMrsKellyHammondqrejw100% (11)
- How To Use Command Prompt To Fix Issues With Your PC's Boot Records PDFDocumento13 pagineHow To Use Command Prompt To Fix Issues With Your PC's Boot Records PDFPramod ThakurNessuna valutazione finora
- Automatic Phase Selector Fro, Avilable Three Phase With Use of RelaysDocumento37 pagineAutomatic Phase Selector Fro, Avilable Three Phase With Use of RelaysDinesh KumarNessuna valutazione finora
- Arm STM32WB55 PDFDocumento178 pagineArm STM32WB55 PDFtungNessuna valutazione finora
- UHFReader18 Demo Software User's Guidev2.1Documento18 pagineUHFReader18 Demo Software User's Guidev2.1Jack WyhNessuna valutazione finora
- Terminals Guide For WiMAX Macro BSDocumento35 pagineTerminals Guide For WiMAX Macro BSRamiz RzaogluNessuna valutazione finora
- ROS Release Notes (V1 - 1 - 9)Documento29 pagineROS Release Notes (V1 - 1 - 9)sethzinhoNessuna valutazione finora
- Data ConduitDocumento176 pagineData ConduitLuciano Rodrigues E RodriguesNessuna valutazione finora
- Docker Certified Associate: Training DemoDocumento21 pagineDocker Certified Associate: Training Demoravindramca43382Nessuna valutazione finora
- Chameleon Chips Full ReportDocumento40 pagineChameleon Chips Full Reporttejaswi_manthena05Nessuna valutazione finora
- Introduction To Software-Defined Networking (SDN) and Network Programmability PDFDocumento132 pagineIntroduction To Software-Defined Networking (SDN) and Network Programmability PDFLuc TranNessuna valutazione finora
- Bcs011 NotesDocumento17 pagineBcs011 NotesSachin KumarNessuna valutazione finora
- Oracle® Transportation Management: Technical Architecture Guide Release 6.3 Part No. E38420-07Documento22 pagineOracle® Transportation Management: Technical Architecture Guide Release 6.3 Part No. E38420-07Khalid SiddiquiNessuna valutazione finora
- Chapter 8 - Code GenerationDocumento22 pagineChapter 8 - Code Generationsindhura2258Nessuna valutazione finora
- Comp Holiday HomeworkDocumento12 pagineComp Holiday HomeworkYogendra Singh ShekhawatNessuna valutazione finora
- Computer Networking Multiple Choice Questions & Answers - 1Documento8 pagineComputer Networking Multiple Choice Questions & Answers - 1raghad mejeedNessuna valutazione finora
- Bca Java PDFDocumento8 pagineBca Java PDFchandrekNessuna valutazione finora
- 21 20 3 FCS10 UPC CUPS RCM Config and Admin GuideDocumento29 pagine21 20 3 FCS10 UPC CUPS RCM Config and Admin GuideNguyễn Lương QuyềnNessuna valutazione finora