Potrebbero piacerti anche
- Python: Advanced Guide to Programming Code with Python: Python Computer Programming, #4Da EverandPython: Advanced Guide to Programming Code with Python: Python Computer Programming, #4Nessuna valutazione finora
- R ManualDocumento10 pagineR ManualSuperset NotificationsNessuna valutazione finora
- Perl Scripts For Eda ToolsDocumento6 paginePerl Scripts For Eda ToolsSharan Kumar GoudNessuna valutazione finora
- Simple Tutorial in RDocumento15 pagineSimple Tutorial in RklugshitterNessuna valutazione finora
- SaS NotesDocumento8 pagineSaS NotesVelupucharla Saiprasad ReddyNessuna valutazione finora
- R Exercise 1 - Introduction To R For Non-ProgrammersDocumento9 pagineR Exercise 1 - Introduction To R For Non-ProgrammersSamaki AlsatNessuna valutazione finora
- Getting Started in R Stata Notes On Exploring Data: Oscar Torres-ReynaDocumento30 pagineGetting Started in R Stata Notes On Exploring Data: Oscar Torres-ReynamissinuNessuna valutazione finora
- R For Stata Users PDFDocumento32 pagineR For Stata Users PDFJimmy100% (1)
- Exploratory Data Analysis and Graphics: Lab 2Documento19 pagineExploratory Data Analysis and Graphics: Lab 2juntujuntuNessuna valutazione finora
- Instructions For Using R To Create Predictive Models v5Documento17 pagineInstructions For Using R To Create Predictive Models v5Giovanni FirrincieliNessuna valutazione finora
- Solution Manual For Using Multivariate Statistics 7th Edition Barbara G Tabachnick Linda S FidellDocumento37 pagineSolution Manual For Using Multivariate Statistics 7th Edition Barbara G Tabachnick Linda S Fidelloliverstelvpk100% (14)
- Appendix RDocumento11 pagineAppendix RRaphael CorbiNessuna valutazione finora
- Introduction To RDocumento3 pagineIntroduction To RDavid CrabtreeNessuna valutazione finora
- Stata BibleDocumento17 pagineStata BibleDarrel BhugwandasNessuna valutazione finora
- MrtglibDocumento4 pagineMrtglibPaul BecanNessuna valutazione finora
- Chapter 5 - File Input and OutputDocumento4 pagineChapter 5 - File Input and OutputKrishna KumarNessuna valutazione finora
- YouTube DownLoaderDocumento20 pagineYouTube DownLoaderMackos-GnuNessuna valutazione finora
- HADOOP AND BIG DATA - FinalDocumento26 pagineHADOOP AND BIG DATA - FinalDeeq HuseenNessuna valutazione finora
- Python For DS Cheat SheetDocumento6 paginePython For DS Cheat SheetSebastián Emdef100% (2)
- IDAP AssignmentDocumento6 pagineIDAP AssignmentRithik ReddyNessuna valutazione finora
- Beginner Guide To R and R Studio V1Documento27 pagineBeginner Guide To R and R Studio V1broto_wasesoNessuna valutazione finora
- ECE 264 Advanced C Programming 2009/01/30: 1 File Operations 1Documento14 pagineECE 264 Advanced C Programming 2009/01/30: 1 File Operations 1truongvinhlan19895148Nessuna valutazione finora
- Programming in STATADocumento15 pagineProgramming in STATAAfc HawkNessuna valutazione finora
- ML FileDocumento12 pagineML Filehdofficial2003Nessuna valutazione finora
- Notes For SAS Programming Fall2009Documento88 pagineNotes For SAS Programming Fall2009Gowtham SpNessuna valutazione finora
- Stata TutorialDocumento63 pagineStata TutorialAndré Medeiros SztutmanNessuna valutazione finora
- System Calls 1657780916998Documento15 pagineSystem Calls 1657780916998SUBHANessuna valutazione finora
- Char Fgets (Char STR, Int N, FILE Stream) : #IncludeDocumento60 pagineChar Fgets (Char STR, Int N, FILE Stream) : #IncludeMaisyatul IhsaniyahNessuna valutazione finora
- Practical Program List WITH SOLUTIONSDocumento16 paginePractical Program List WITH SOLUTIONShecaxi7698Nessuna valutazione finora
- Basic Unix and Linux Commands With ExamplesDocumento168 pagineBasic Unix and Linux Commands With ExamplesSundeep ByraganiNessuna valutazione finora
- Char Fgets (Char STR, Int N, FILE Stream)Documento34 pagineChar Fgets (Char STR, Int N, FILE Stream)Maisyatul IhsaniyahNessuna valutazione finora
- Session 5: A C Program For Straight Line Fitting To Data: 1st Year Computing For EngineeringDocumento11 pagineSession 5: A C Program For Straight Line Fitting To Data: 1st Year Computing For Engineeringkvgpraveen107Nessuna valutazione finora
- Iptables LinuxDocumento286 pagineIptables LinuxVeronica ChiriacNessuna valutazione finora
- NNPP2020. - Guia RDocumento6 pagineNNPP2020. - Guia RYassine HamdaneNessuna valutazione finora
- Fast RDocumento43 pagineFast RHannah MurichoNessuna valutazione finora
- Lenguaje R C1Documento33 pagineLenguaje R C1amaury bascosNessuna valutazione finora
- Commands, Fork and ExecDocumento10 pagineCommands, Fork and ExecManil K SharmaNessuna valutazione finora
- SAS: What You Need To Know To Write A SAS Program: Data Definition and Options Data Step Procedure(s)Documento8 pagineSAS: What You Need To Know To Write A SAS Program: Data Definition and Options Data Step Procedure(s)anis_hasan2008Nessuna valutazione finora
- Course Ada AdvancedDocumento93 pagineCourse Ada AdvancedDavid BriggsNessuna valutazione finora
- R Studio Info For 272Documento13 pagineR Studio Info For 272samrasamara2014Nessuna valutazione finora
- A Brief Guide To R For Beginners in Econometrics: Department of Economics, Stockholm UniversityDocumento31 pagineA Brief Guide To R For Beginners in Econometrics: Department of Economics, Stockholm Universityatom108Nessuna valutazione finora
- Problem Set 1: Introduction To R - Solutions With R Output: 1 Install PackagesDocumento24 pagineProblem Set 1: Introduction To R - Solutions With R Output: 1 Install PackagesDarnell LarsenNessuna valutazione finora
- Problem Set 1: Prof. Conlon Due: 2/15/19Documento6 pagineProblem Set 1: Prof. Conlon Due: 2/15/19Vicente JorgeNessuna valutazione finora
- R Language NotesDocumento8 pagineR Language NotesRudransh JNessuna valutazione finora
- Free Form RPGDocumento18 pagineFree Form RPGVISHNU400Nessuna valutazione finora
- OS ManualDocumento63 pagineOS ManualNivetha SubramanianNessuna valutazione finora
- Package Sys': R Topics DocumentedDocumento7 paginePackage Sys': R Topics Documentedforjunk786Nessuna valutazione finora
- Data Analyses Stata Manual NYTSDocumento40 pagineData Analyses Stata Manual NYTSahmad rifanNessuna valutazione finora
- PythonDocumento31 paginePythonRimjhim KymariNessuna valutazione finora
- Quiz 2Documento11 pagineQuiz 2KSHITIJ SONI 19PE10041Nessuna valutazione finora
- Orchadmin CommandsDocumento2 pagineOrchadmin CommandsVasu SrinivasNessuna valutazione finora
- Usingrformapmaking NotesDocumento12 pagineUsingrformapmaking Notesaya996995Nessuna valutazione finora
- Text%2 BFilesDocumento4 pagineText%2 BFilesadelinaNessuna valutazione finora
- CS8461 Os Lab Manual PrintDocumento58 pagineCS8461 Os Lab Manual Printkurinji67% (3)
- Abintio DocumentsDocumento15 pagineAbintio DocumentsSaurabhNessuna valutazione finora
- R Lab Programs-1Documento26 pagineR Lab Programs-1rns itNessuna valutazione finora
- Running Winsteps With SASDocumento18 pagineRunning Winsteps With SASEzekiel F. CoNessuna valutazione finora
- Chapter 1: R Style Guide: 1. Quy tắc đặt tênDocumento27 pagineChapter 1: R Style Guide: 1. Quy tắc đặt tênKiềuTuyếnNessuna valutazione finora
- BRM FileDocumento20 pagineBRM FilegarvbarrejaNessuna valutazione finora
- Profile Analysis of Students' Academic Performance in Ghanaian Polytechnics: The Case of Bolgatanga PolytechnicDocumento8 pagineProfile Analysis of Students' Academic Performance in Ghanaian Polytechnics: The Case of Bolgatanga PolytechnicAkolgo PaulinaNessuna valutazione finora
- Data Analysis (0243199541)Documento4 pagineData Analysis (0243199541)Akolgo PaulinaNessuna valutazione finora
- Ajsms 2 4 348 355Documento8 pagineAjsms 2 4 348 355Akolgo PaulinaNessuna valutazione finora
- Ncae - Knust (2011)Documento1 paginaNcae - Knust (2011)Akolgo PaulinaNessuna valutazione finora
- Tandf Nere2014 305.risDocumento2 pagineTandf Nere2014 305.risApam BenjaminNessuna valutazione finora
- 6370-8517-1-PB (Pp. 7-10)Documento4 pagine6370-8517-1-PB (Pp. 7-10)Akolgo PaulinaNessuna valutazione finora
- Income Analysis (Oct - 2011 - Sept - 2012)Documento18 pagineIncome Analysis (Oct - 2011 - Sept - 2012)Akolgo PaulinaNessuna valutazione finora
- 6th Central Pay Commission Salary CalculatorDocumento15 pagine6th Central Pay Commission Salary Calculatorrakhonde100% (436)
- Logistic Regress QDocumento5 pagineLogistic Regress QAkolgo PaulinaNessuna valutazione finora
- CVD InfoDocumento1 paginaCVD InfoApam BenjaminNessuna valutazione finora
- Work Done 3333Documento4 pagineWork Done 3333Akolgo PaulinaNessuna valutazione finora
- Asri Stata 2013-FlyerDocumento1 paginaAsri Stata 2013-FlyerAkolgo PaulinaNessuna valutazione finora
- Goodwin MessageDocumento1 paginaGoodwin MessageAkolgo PaulinaNessuna valutazione finora
- Attachment Report EditDocumento17 pagineAttachment Report EditAkolgo PaulinaNessuna valutazione finora
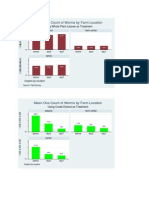
- Mean Ova Count of Worms by Farm Location: Using Whole Plant Leaves As TreatmentDocumento4 pagineMean Ova Count of Worms by Farm Location: Using Whole Plant Leaves As TreatmentAkolgo PaulinaNessuna valutazione finora
- Bolgatanga Polytechnic: School of BusinessDocumento2 pagineBolgatanga Polytechnic: School of BusinessAkolgo PaulinaNessuna valutazione finora
- Managing Director: Personal AssistantDocumento1 paginaManaging Director: Personal AssistantApam BenjaminNessuna valutazione finora
- Multivariate Data AnalysisDocumento20 pagineMultivariate Data AnalysisAkolgo PaulinaNessuna valutazione finora
- Command Window: Stata Results Window: Variables Window: Review WindowDocumento3 pagineCommand Window: Stata Results Window: Variables Window: Review WindowAkolgo PaulinaNessuna valutazione finora
- Statistical Inference WebDocumento26 pagineStatistical Inference WebgogasinghNessuna valutazione finora
- Maximum LikelihoodDocumento3 pagineMaximum LikelihoodAkolgo PaulinaNessuna valutazione finora
- Clinical TrialDocumento13 pagineClinical TrialApam BenjaminNessuna valutazione finora
- What Is A PHP File?Documento12 pagineWhat Is A PHP File?Jeremiah EliorNessuna valutazione finora
- Innterview QuestionsDocumento19 pagineInnterview QuestionsEmran HossainNessuna valutazione finora
- Applications Cloud Using Functional Setup ManagerDocumento52 pagineApplications Cloud Using Functional Setup ManagerMohammed Abdelfttah MustafaNessuna valutazione finora
- E ScriptDocumento334 pagineE ScriptAshwathkumar86Nessuna valutazione finora
- Micriμm - C Coding Standard - An1003Documento15 pagineMicriμm - C Coding Standard - An1003sdfklaghNessuna valutazione finora
- Program SAB - 01Documento2 pagineProgram SAB - 01Catalin SasNessuna valutazione finora
- Public Class: Singleton, Prototype, Request, Session and Global SessionDocumento6 paginePublic Class: Singleton, Prototype, Request, Session and Global SessionAshihsNessuna valutazione finora
- CSEDocumento117 pagineCSEramanjijntu10Nessuna valutazione finora
- Contents at A Glance: Assessment Tests LixDocumento19 pagineContents at A Glance: Assessment Tests Lixasdffdsaasdffdsa12344312Nessuna valutazione finora
- Final Exam (Study Guide 2 Questions)Documento13 pagineFinal Exam (Study Guide 2 Questions)i_gilNessuna valutazione finora
- C++ - Functions CheatsheetDocumento6 pagineC++ - Functions CheatsheetYoussouf KadiNessuna valutazione finora
- CS201 Fall 2008 Final Solved by Vuzs TeamDocumento10 pagineCS201 Fall 2008 Final Solved by Vuzs Teamcyborg_titenNessuna valutazione finora
- Overview - PCAP - Programming Essentials in Python (December 19, 201...Documento23 pagineOverview - PCAP - Programming Essentials in Python (December 19, 201...LeandroNessuna valutazione finora
- Dashboard Design Part 2 v1Documento17 pagineDashboard Design Part 2 v1Bea BoocNessuna valutazione finora
- 4 Open PLCDocumento4 pagine4 Open PLCSebestyén BélaNessuna valutazione finora
- CPP Interview QuestionsDocumento8 pagineCPP Interview Questionsapi-3711728Nessuna valutazione finora
- PowerForwardUG PDFDocumento400 paginePowerForwardUG PDFvarma2986Nessuna valutazione finora
- Beginner Level Javascript Interview Questions and Answers For FreshersDocumento19 pagineBeginner Level Javascript Interview Questions and Answers For Freshersdorian451Nessuna valutazione finora
- ROOT Basic Course PDFDocumento374 pagineROOT Basic Course PDFjoao da silvaNessuna valutazione finora
- Salesforce Summer12 Release NotesDocumento200 pagineSalesforce Summer12 Release NotesMilind GokarnNessuna valutazione finora
- CHK-084 Conducting A Skills AuditDocumento6 pagineCHK-084 Conducting A Skills AuditMus'ab AhnafNessuna valutazione finora
- C++ - Unit IIDocumento109 pagineC++ - Unit IIElamathi LNessuna valutazione finora
- Aspen Plus ACU Study GuideDocumento38 pagineAspen Plus ACU Study GuideEl Mouatez Messini100% (1)
- Call 1Documento29 pagineCall 1nergal19Nessuna valutazione finora
- Best Practices Power AutomateDocumento80 pagineBest Practices Power AutomatesolfegeNessuna valutazione finora
- Auto Trading System Final PDFDocumento26 pagineAuto Trading System Final PDFRajatNessuna valutazione finora
- CPP Smart Pointers EbookDocumento58 pagineCPP Smart Pointers EbookashNessuna valutazione finora
- CIP 002 5.1aDocumento37 pagineCIP 002 5.1aJoel FigueroaNessuna valutazione finora
- Course: CGSC 1005 A Facilitator: Samaia AidroosDocumento6 pagineCourse: CGSC 1005 A Facilitator: Samaia AidroosJules LavoieNessuna valutazione finora
- 1z0-964.exam.47q: Number: 1z0-964 Passing Score: 800 Time Limit: 120 MinDocumento24 pagine1z0-964.exam.47q: Number: 1z0-964 Passing Score: 800 Time Limit: 120 MinSohailMunawarNessuna valutazione finora