Potrebbero piacerti anche
- Logistic Regression AnalysisDocumento16 pagineLogistic Regression AnalysisPIE TUTORSNessuna valutazione finora
- Basic Econometrics Revision - Econometric ModellingDocumento65 pagineBasic Econometrics Revision - Econometric ModellingTrevor ChimombeNessuna valutazione finora
- CH 123Documento63 pagineCH 123bgsrizkiNessuna valutazione finora
- Running A Proper Regression Analysis: V G R Chandran Govindaraju Uitm Email: WebsiteDocumento36 pagineRunning A Proper Regression Analysis: V G R Chandran Govindaraju Uitm Email: WebsiteArafatul Alam PatwaryNessuna valutazione finora
- 7,8-Simple Regression PDFDocumento47 pagine7,8-Simple Regression PDFKevin HyunNessuna valutazione finora
- Introduction To Econometrics and Operations ResearchDocumento28 pagineIntroduction To Econometrics and Operations ResearchkhongaybytNessuna valutazione finora
- Random Effects ModelsDocumento37 pagineRandom Effects Modelshubik38Nessuna valutazione finora
- 945 Lecture6 Generalized PDFDocumento63 pagine945 Lecture6 Generalized PDFYusrianti HanikeNessuna valutazione finora
- Ch01 02 03 Final BDocumento63 pagineCh01 02 03 Final BMaria Cristina RossiNessuna valutazione finora
- Chap3 - Multiple RegressionDocumento56 pagineChap3 - Multiple RegressionNguyễn Lê Minh AnhNessuna valutazione finora
- LogitDocumento48 pagineLogitavatarman92Nessuna valutazione finora
- MultilevelPRI WorkshopDocumento32 pagineMultilevelPRI WorkshopAndré Luiz LimaNessuna valutazione finora
- Stats101A - Chapter 1Documento25 pagineStats101A - Chapter 1Zhen WangNessuna valutazione finora
- GLMDocumento26 pagineGLMNirmal RoyNessuna valutazione finora
- Regression Analysis (Cases 1-3)Documento42 pagineRegression Analysis (Cases 1-3)saeedawais47Nessuna valutazione finora
- Chapter 14Documento15 pagineChapter 14UsamaNessuna valutazione finora
- 09-Limited Dependent Variable ModelsDocumento71 pagine09-Limited Dependent Variable ModelsChristopher WilliamsNessuna valutazione finora
- Regression and Multiple Regression AnalysisDocumento21 pagineRegression and Multiple Regression AnalysisRaghu NayakNessuna valutazione finora
- Worksheets-Importance of MathematicsDocumento38 pagineWorksheets-Importance of MathematicsHarsh VyasNessuna valutazione finora
- ECN102 FNSample IIDocumento9 pagineECN102 FNSample IIakinagakiNessuna valutazione finora
- Multiple Regression Analysis 1Documento57 pagineMultiple Regression Analysis 1Jacqueline CarbonelNessuna valutazione finora
- Sample Exam Questions SolutionsDocumento3 pagineSample Exam Questions Solutionskickbartram2Nessuna valutazione finora
- Discrete Choice Modeling: William Greene Stern School of Business New York UniversityDocumento58 pagineDiscrete Choice Modeling: William Greene Stern School of Business New York UniversityJesús M. VilleroNessuna valutazione finora
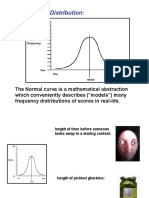
- NormalDistribution2012 PDFDocumento29 pagineNormalDistribution2012 PDFElisa Dela Reyna BaladadNessuna valutazione finora
- Class 10 Multilevel ModelsDocumento42 pagineClass 10 Multilevel Modelshubik38Nessuna valutazione finora
- MicroEconometrics Lecture10Documento27 pagineMicroEconometrics Lecture10Carolina Correa CaroNessuna valutazione finora
- Analysis of Complex Sample Survey DataDocumento24 pagineAnalysis of Complex Sample Survey DataCamilo Gutiérrez PatiñoNessuna valutazione finora
- Structural Equation ModellingDocumento36 pagineStructural Equation ModellingMuhammad Imran AlamNessuna valutazione finora
- Regression Analysis 01Documento56 pagineRegression Analysis 01IRPS100% (5)
- 10 - APM 1205 Linear ModelDocumento40 pagine10 - APM 1205 Linear ModelTeddy BonitezNessuna valutazione finora
- Lecture+8+ +Linear+RegressionDocumento45 pagineLecture+8+ +Linear+RegressionSupaapt SrionNessuna valutazione finora
- Poisson Regression - Stata Data Analysis ExamplesDocumento12 paginePoisson Regression - Stata Data Analysis ExamplesAngger Wiji RahayuNessuna valutazione finora
- Multiple Regression: Model and InterpretationDocumento10 pagineMultiple Regression: Model and InterpretationC CNessuna valutazione finora
- Assessing Studies Based On Multiple Regression (SW Ch. 9) : Causal EffectDocumento35 pagineAssessing Studies Based On Multiple Regression (SW Ch. 9) : Causal EffectJenningsJingjingXuNessuna valutazione finora
- Review QuestionsDocumento9 pagineReview Questionsacr2944Nessuna valutazione finora
- Covariance Vs Component Based Structural Equation Modeling: Prof. Dr. Imam GhozaliDocumento49 pagineCovariance Vs Component Based Structural Equation Modeling: Prof. Dr. Imam GhozaliuletboeloeNessuna valutazione finora
- Remedial Measures Purdue - EduDocumento28 pagineRemedial Measures Purdue - EduDash CorderoNessuna valutazione finora
- Introduction To SEMDocumento64 pagineIntroduction To SEMThu LeNessuna valutazione finora
- Chapter Two: Bivariate Regression ModeDocumento54 pagineChapter Two: Bivariate Regression ModenahomNessuna valutazione finora
- Name: Chinmay Tripurwar Roll No: 22b3902: Simple Regression Model AnalysisDocumento9 pagineName: Chinmay Tripurwar Roll No: 22b3902: Simple Regression Model Analysissparee1256Nessuna valutazione finora
- Multiple RegressionDocumento100 pagineMultiple RegressionNilton de SousaNessuna valutazione finora
- An Introduction To Logistic Regression: Johnwhitehead Department of Economics East Carolina UniversityDocumento48 pagineAn Introduction To Logistic Regression: Johnwhitehead Department of Economics East Carolina UniversityAnagha PatilNessuna valutazione finora
- PPT+59+ +Ex+11B+Standardisation,+68!95!99.7+RuleDocumento23 paginePPT+59+ +Ex+11B+Standardisation,+68!95!99.7+RuleRalph Rezin MooreNessuna valutazione finora
- Z-Score Problems With The Normal Model: ObjectiveDocumento24 pagineZ-Score Problems With The Normal Model: ObjectiveCleverton da VeigaNessuna valutazione finora
- Ie Slide02Documento30 pagineIe Slide02Leo KaligisNessuna valutazione finora
- Normal Distribution 2012Documento29 pagineNormal Distribution 2012Isaac Daplas RosarioNessuna valutazione finora
- Let LetDocumento29 pagineLet LetIsaac Daplas RosarioNessuna valutazione finora
- Introduction Multilevel Analysis: Rens Van de SchootDocumento37 pagineIntroduction Multilevel Analysis: Rens Van de Schootvsuarezf2732Nessuna valutazione finora
- Week 9 ADocumento26 pagineWeek 9 AKarthi KeyanNessuna valutazione finora
- Problem Set #1Documento6 pagineProblem Set #1cflores48Nessuna valutazione finora
- Regression With Dummy Variables Econ420 1Documento47 pagineRegression With Dummy Variables Econ420 1shaharhr1Nessuna valutazione finora
- Standard Scores and The Normal Curve: Report Presentation byDocumento38 pagineStandard Scores and The Normal Curve: Report Presentation byEmmanuel AbadNessuna valutazione finora
- Polynomial RegressionDocumento15 paginePolynomial RegressionHumberto Alonso Santos MoralesNessuna valutazione finora
- AP Statistics Flashcards, Fourth Edition: Up-to-Date PracticeDa EverandAP Statistics Flashcards, Fourth Edition: Up-to-Date PracticeNessuna valutazione finora
- Practical Engineering, Process, and Reliability StatisticsDa EverandPractical Engineering, Process, and Reliability StatisticsNessuna valutazione finora
- Process Performance Models: Statistical, Probabilistic & SimulationDa EverandProcess Performance Models: Statistical, Probabilistic & SimulationNessuna valutazione finora
- Integer Optimization and its Computation in Emergency ManagementDa EverandInteger Optimization and its Computation in Emergency ManagementNessuna valutazione finora
- Systems with Delays: Analysis, Control, and ComputationsDa EverandSystems with Delays: Analysis, Control, and ComputationsNessuna valutazione finora
- Sabre V8Documento16 pagineSabre V8stefan.vince536Nessuna valutazione finora
- Transformational and Charismatic Leadership: The Road Ahead 10th Anniversary EditionDocumento32 pagineTransformational and Charismatic Leadership: The Road Ahead 10th Anniversary Editionfisaac333085Nessuna valutazione finora
- Manipulation Methods and How To Avoid From ManipulationDocumento5 pagineManipulation Methods and How To Avoid From ManipulationEylül ErgünNessuna valutazione finora
- Dawn of The DhammaDocumento65 pagineDawn of The Dhammaarkaprava paulNessuna valutazione finora
- PMP Exam Questions and Answers PDFDocumento12 paginePMP Exam Questions and Answers PDFAshwin Raghav SankarNessuna valutazione finora
- Lesson 3: Letters of RequestDocumento4 pagineLesson 3: Letters of RequestMinh HiếuNessuna valutazione finora
- HC-97G FactsheetDocumento1 paginaHC-97G FactsheettylerturpinNessuna valutazione finora
- Variables in The EquationDocumento3 pagineVariables in The EquationfiharjatinNessuna valutazione finora
- User Manual ManoScanDocumento58 pagineUser Manual ManoScanNurul FathiaNessuna valutazione finora
- Concordance C Index - 2 PDFDocumento8 pagineConcordance C Index - 2 PDFnuriyesanNessuna valutazione finora
- Free DMAIC Checklist Template Excel DownloadDocumento5 pagineFree DMAIC Checklist Template Excel DownloadErik Leonel LucianoNessuna valutazione finora
- 1st Quarter 2016 Lesson 5 Powerpoint With Tagalog NotesDocumento25 pagine1st Quarter 2016 Lesson 5 Powerpoint With Tagalog NotesRitchie FamarinNessuna valutazione finora
- Acute Conditions of The NewbornDocumento46 pagineAcute Conditions of The NewbornCamille Joy BaliliNessuna valutazione finora
- Shaheed Suhrawardy Medical College HospitalDocumento3 pagineShaheed Suhrawardy Medical College HospitalDr. Mohammad Nazrul IslamNessuna valutazione finora
- Parker (T6, T6D) Hydraulic Vane PumpsDocumento12 pagineParker (T6, T6D) Hydraulic Vane PumpsMortumDamaNessuna valutazione finora
- Boomer L2 D - 9851 2586 01Documento4 pagineBoomer L2 D - 9851 2586 01Pablo Luis Pérez PostigoNessuna valutazione finora
- Cics 400 Administration and Operations GuideDocumento343 pagineCics 400 Administration and Operations GuidedafraumNessuna valutazione finora
- Amlodipine Besylate Drug StudyDocumento2 pagineAmlodipine Besylate Drug StudyJonieP84Nessuna valutazione finora
- GE Elec 7 UNIT-3 NoDocumento22 pagineGE Elec 7 UNIT-3 NoLyleNessuna valutazione finora
- Psychological Well Being - 18 ItemsDocumento5 paginePsychological Well Being - 18 ItemsIqra LatifNessuna valutazione finora
- File Server Resource ManagerDocumento9 pagineFile Server Resource ManagerBùi Đình NhuNessuna valutazione finora
- Light Design by Anil ValiaDocumento10 pagineLight Design by Anil ValiaMili Jain0% (1)
- Secondary Scheme of Work Form 2Documento163 pagineSecondary Scheme of Work Form 2Fariha RismanNessuna valutazione finora
- Manual Safety Installation Operations Tescom en 123946Documento23 pagineManual Safety Installation Operations Tescom en 123946Karikalan JayNessuna valutazione finora
- Interdisciplinary Project 1Documento11 pagineInterdisciplinary Project 1api-424250570Nessuna valutazione finora
- 2400 8560 PR 8010 - A1 HSE Management PlanDocumento34 pagine2400 8560 PR 8010 - A1 HSE Management PlanMohd Musa HashimNessuna valutazione finora
- #5-The Specialities in The Krithis of Muthuswamy DikshitharDocumento5 pagine#5-The Specialities in The Krithis of Muthuswamy DikshitharAnuradha MaheshNessuna valutazione finora
- CSMP77: en Es FRDocumento38 pagineCSMP77: en Es FRGerson FelipeNessuna valutazione finora
- Foreign Affairs May June 2021 IssueDocumento216 pagineForeign Affairs May June 2021 IssueSohail BhattiNessuna valutazione finora