Potrebbero piacerti anche
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Da EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Valutazione: 4.5 su 5 stelle4.5/5 (121)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDa EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryValutazione: 3.5 su 5 stelle3.5/5 (231)
- Grit: The Power of Passion and PerseveranceDa EverandGrit: The Power of Passion and PerseveranceValutazione: 4 su 5 stelle4/5 (588)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDa EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaValutazione: 4.5 su 5 stelle4.5/5 (266)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDa EverandNever Split the Difference: Negotiating As If Your Life Depended On ItValutazione: 4.5 su 5 stelle4.5/5 (838)
- The Emperor of All Maladies: A Biography of CancerDa EverandThe Emperor of All Maladies: A Biography of CancerValutazione: 4.5 su 5 stelle4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingDa EverandThe Little Book of Hygge: Danish Secrets to Happy LivingValutazione: 3.5 su 5 stelle3.5/5 (400)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDa EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeValutazione: 4 su 5 stelle4/5 (5794)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDa EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyValutazione: 3.5 su 5 stelle3.5/5 (2259)
- Shoe Dog: A Memoir by the Creator of NikeDa EverandShoe Dog: A Memoir by the Creator of NikeValutazione: 4.5 su 5 stelle4.5/5 (537)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDa EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreValutazione: 4 su 5 stelle4/5 (1090)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDa EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersValutazione: 4.5 su 5 stelle4.5/5 (345)
- Team of Rivals: The Political Genius of Abraham LincolnDa EverandTeam of Rivals: The Political Genius of Abraham LincolnValutazione: 4.5 su 5 stelle4.5/5 (234)
- Her Body and Other Parties: StoriesDa EverandHer Body and Other Parties: StoriesValutazione: 4 su 5 stelle4/5 (821)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDa EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceValutazione: 4 su 5 stelle4/5 (895)
- AA Metatron The Rays of Atlantian Knowledge and Rays of Healing Through Jim SelfDocumento14 pagineAA Metatron The Rays of Atlantian Knowledge and Rays of Healing Through Jim SelfMeaghan Mathews100% (1)
- The Unwinding: An Inner History of the New AmericaDa EverandThe Unwinding: An Inner History of the New AmericaValutazione: 4 su 5 stelle4/5 (45)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDa EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureValutazione: 4.5 su 5 stelle4.5/5 (474)
- On Fire: The (Burning) Case for a Green New DealDa EverandOn Fire: The (Burning) Case for a Green New DealValutazione: 4 su 5 stelle4/5 (74)
- The Yellow House: A Memoir (2019 National Book Award Winner)Da EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Valutazione: 4 su 5 stelle4/5 (98)
- CRB - Digging Up A New PastDocumento17 pagineCRB - Digging Up A New PastAlvino-Mario FantiniNessuna valutazione finora
- Third-Party LogisticsDocumento16 pagineThird-Party Logisticsdeepshetty100% (1)
- GAIN - Flight Safety HandbookDocumento180 pagineGAIN - Flight Safety HandbookDennis Groves100% (4)
- The Universe ALWAYS Says YES - Brad JensenDocumento15 pagineThe Universe ALWAYS Says YES - Brad JensenNicole Weatherley100% (3)
- Stochastic ProgrammingDocumento315 pagineStochastic Programmingfeiying1980100% (1)
- P6 Set Up Performance %Documento10 pagineP6 Set Up Performance %Bryan JacksonNessuna valutazione finora
- Ielts Reading Test 10 - QuestionsDocumento5 pagineIelts Reading Test 10 - QuestionsĐinh Quốc LiêmNessuna valutazione finora
- Data Analysis Using Lichtman's 3 C'sDocumento2 pagineData Analysis Using Lichtman's 3 C'sLyka Yusay60% (5)
- Semi-Detailed Lesson Plan in TLE VIDocumento3 pagineSemi-Detailed Lesson Plan in TLE VIPepper Santiago100% (5)
- Portable Ground Control Station: A Universal Off-The Shelf SolutionDocumento3 paginePortable Ground Control Station: A Universal Off-The Shelf SolutionantsouNessuna valutazione finora
- Project Plan SealDocumento19 pagineProject Plan SealantsouNessuna valutazione finora
- Combined Pitot - Static Tube: Datasheet V 2.0Documento1 paginaCombined Pitot - Static Tube: Datasheet V 2.0antsouNessuna valutazione finora
- 2N SIP Speaker: Far More Than Just IP PagingDocumento2 pagine2N SIP Speaker: Far More Than Just IP PagingantsouNessuna valutazione finora
- Face RecognitionDocumento2 pagineFace RecognitionantsouNessuna valutazione finora
- Control Station User Manual V1.1 PDFDocumento23 pagineControl Station User Manual V1.1 PDFantsouNessuna valutazione finora
- SmartGate BrochureDocumento2 pagineSmartGate BrochureantsouNessuna valutazione finora
- 2n Easygate Umts UsbDocumento6 pagine2n Easygate Umts UsbantsouNessuna valutazione finora
- 2N NetStar Product Presentation End Users enDocumento14 pagine2N NetStar Product Presentation End Users enantsouNessuna valutazione finora
- 2N Netstar: Discover The Simplicity of CommunicationDocumento4 pagine2N Netstar: Discover The Simplicity of CommunicationantsouNessuna valutazione finora
- Top Sec 703 Plus enDocumento2 pagineTop Sec 703 Plus enantsouNessuna valutazione finora
- 2N NetStar Product Presentation End Users enDocumento14 pagine2N NetStar Product Presentation End Users enantsouNessuna valutazione finora
- 2016/2017 Master Timetable (Tentative) : Published: May 2016Documento19 pagine2016/2017 Master Timetable (Tentative) : Published: May 2016Ken StaynerNessuna valutazione finora
- I PU Geography English Medium PDFDocumento211 pagineI PU Geography English Medium PDFMADEGOWDA BSNessuna valutazione finora
- Naac Uma Maha PandharpurDocumento204 pagineNaac Uma Maha Pandharpurapi-191430885Nessuna valutazione finora
- Listening FIB SpellingDocumento6 pagineListening FIB SpellingAtif JavedNessuna valutazione finora
- Cheat Sheet - Mathematical Reasoning Truth Tables Laws: Conjunction: Double Negation LawDocumento1 paginaCheat Sheet - Mathematical Reasoning Truth Tables Laws: Conjunction: Double Negation LawVîñît YãdûvãñšhîNessuna valutazione finora
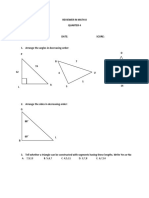
- Reviewer in Math 8Documento13 pagineReviewer in Math 8Cañeda AlejanioNessuna valutazione finora
- SPC 200 Manual 170246Documento371 pagineSPC 200 Manual 170246osamaaaaaNessuna valutazione finora
- Intel (R) ME Firmware Integrated Clock Control (ICC) Tools User GuideDocumento24 pagineIntel (R) ME Firmware Integrated Clock Control (ICC) Tools User Guidebox.office1003261Nessuna valutazione finora
- SIX SIGMA at GEDocumento11 pagineSIX SIGMA at GE1987dezyNessuna valutazione finora
- Population QuestionsDocumento79 paginePopulation QuestionsBooNessuna valutazione finora
- Anilam 4200t CNC Programming and Operations ManualDocumento355 pagineAnilam 4200t CNC Programming and Operations ManualAlexandru PrecupNessuna valutazione finora
- Anam CVDocumento2 pagineAnam CVAnam AslamNessuna valutazione finora
- Maths Assessment Year 3 Term 3: Addition and Subtraction: NameDocumento4 pagineMaths Assessment Year 3 Term 3: Addition and Subtraction: NamebayaNessuna valutazione finora
- Reaction Paper Failon Ngayon: Kalamidad Sa Pabahay Failon Ngayon: Barangay Health StationsDocumento4 pagineReaction Paper Failon Ngayon: Kalamidad Sa Pabahay Failon Ngayon: Barangay Health StationsRomeo Chavez BardajeNessuna valutazione finora
- 7 ODE 2nd Order v2Documento3 pagine7 ODE 2nd Order v2Agung GuskaNessuna valutazione finora
- Berna1Documento4 pagineBerna1Kenneth RomanoNessuna valutazione finora
- Theoretical Foundation in NursingDocumento24 pagineTheoretical Foundation in NursingJorie RocoNessuna valutazione finora
- ST - Lucia Seventh-Day Adventist Academy Physics Notes Form 5 October 18, 2016Documento3 pagineST - Lucia Seventh-Day Adventist Academy Physics Notes Form 5 October 18, 2016Anna Lyse MosesNessuna valutazione finora
- BK Gdan 000768Documento5 pagineBK Gdan 000768azisridwansyahNessuna valutazione finora