Potrebbero piacerti anche
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDa EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceValutazione: 4 su 5 stelle4/5 (895)
- 06 Mechanical PropertiesDocumento62 pagine06 Mechanical PropertiesJessamine KurniaNessuna valutazione finora
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDa EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeValutazione: 4 su 5 stelle4/5 (5794)
- Ch19 ISMDocumento84 pagineCh19 ISMJessamine KurniaNessuna valutazione finora
- The Yellow House: A Memoir (2019 National Book Award Winner)Da EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Valutazione: 4 su 5 stelle4/5 (98)
- EthicsDocumento23 pagineEthicsJessamine KurniaNessuna valutazione finora
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDa EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureValutazione: 4.5 su 5 stelle4.5/5 (474)
- Exploring Bayes THMDocumento6 pagineExploring Bayes THMJessamine KurniaNessuna valutazione finora
- Shoe Dog: A Memoir by the Creator of NikeDa EverandShoe Dog: A Memoir by the Creator of NikeValutazione: 4.5 su 5 stelle4.5/5 (537)
- Important Terms in ObliconDocumento4 pagineImportant Terms in ObliconAriana Cristelle L. Pagdanganan100% (1)
- The Little Book of Hygge: Danish Secrets to Happy LivingDa EverandThe Little Book of Hygge: Danish Secrets to Happy LivingValutazione: 3.5 su 5 stelle3.5/5 (399)
- CPI As A KPIDocumento13 pagineCPI As A KPIKS LimNessuna valutazione finora
- DataBase Management Systems SlidesDocumento64 pagineDataBase Management Systems SlidesMukhesh InturiNessuna valutazione finora
- On Fire: The (Burning) Case for a Green New DealDa EverandOn Fire: The (Burning) Case for a Green New DealValutazione: 4 su 5 stelle4/5 (73)
- Median FilteringDocumento30 pagineMedian FilteringK.R.RaguramNessuna valutazione finora
- Never Split the Difference: Negotiating As If Your Life Depended On ItDa EverandNever Split the Difference: Negotiating As If Your Life Depended On ItValutazione: 4.5 su 5 stelle4.5/5 (838)
- Pa 28 151 161 - mmv1995 PDFDocumento585 paginePa 28 151 161 - mmv1995 PDFJonatan JonatanBernalNessuna valutazione finora
- Grit: The Power of Passion and PerseveranceDa EverandGrit: The Power of Passion and PerseveranceValutazione: 4 su 5 stelle4/5 (588)
- Chinaware - Zen PDFDocumento111 pagineChinaware - Zen PDFMixo LogiNessuna valutazione finora
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDa EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryValutazione: 3.5 su 5 stelle3.5/5 (231)
- CIVREV!!!!Documento5 pagineCIVREV!!!!aypod100% (1)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDa EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaValutazione: 4.5 su 5 stelle4.5/5 (266)
- Psychological Attitude Towards SafetyDocumento17 paginePsychological Attitude Towards SafetyAMOL RASTOGI 19BCM0012Nessuna valutazione finora
- Renvoi in Private International LawDocumento4 pagineRenvoi in Private International LawAgav VithanNessuna valutazione finora
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDa EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersValutazione: 4.5 su 5 stelle4.5/5 (344)
- Phet Body Group 1 ScienceDocumento42 paginePhet Body Group 1 ScienceMebel Alicante GenodepanonNessuna valutazione finora
- The Emperor of All Maladies: A Biography of CancerDa EverandThe Emperor of All Maladies: A Biography of CancerValutazione: 4.5 su 5 stelle4.5/5 (271)
- Book Notes Covering: Andy Kirk's Book, Data Visualization - A Successful Design ProcessDocumento10 pagineBook Notes Covering: Andy Kirk's Book, Data Visualization - A Successful Design ProcessDataVersed100% (1)
- Application Letters To Apply For A Job - OdtDocumento2 pagineApplication Letters To Apply For A Job - OdtRita NourNessuna valutazione finora
- Team of Rivals: The Political Genius of Abraham LincolnDa EverandTeam of Rivals: The Political Genius of Abraham LincolnValutazione: 4.5 su 5 stelle4.5/5 (234)
- Scheduled Events in MySQL Load CSV Fileto MysqltabDocumento11 pagineScheduled Events in MySQL Load CSV Fileto Mysqltabboil35Nessuna valutazione finora
- 50 Hotelierstalk MinDocumento16 pagine50 Hotelierstalk MinPadma SanthoshNessuna valutazione finora
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDa EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreValutazione: 4 su 5 stelle4/5 (1090)
- (Rajagopal) Brand Management Strategy, Measuremen (BookFi) PDFDocumento317 pagine(Rajagopal) Brand Management Strategy, Measuremen (BookFi) PDFSneha SinghNessuna valutazione finora
- The Unwinding: An Inner History of the New AmericaDa EverandThe Unwinding: An Inner History of the New AmericaValutazione: 4 su 5 stelle4/5 (45)
- ANNEX C LIST OF EXCEPTIONS (Non-Disslosure of Information)Documento3 pagineANNEX C LIST OF EXCEPTIONS (Non-Disslosure of Information)ryujinxxcastorNessuna valutazione finora
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDa EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyValutazione: 3.5 su 5 stelle3.5/5 (2259)
- An Analytical Study On Impact of Credit Rating Agencies in India 'S DevelopmentDocumento14 pagineAn Analytical Study On Impact of Credit Rating Agencies in India 'S DevelopmentRamneet kaur (Rizzy)Nessuna valutazione finora
- War As I Knew ItDocumento2 pagineWar As I Knew ItShreyansNessuna valutazione finora
- Vivado Power Analysis OptimizationDocumento120 pagineVivado Power Analysis OptimizationBad BoyNessuna valutazione finora
- Craske - Mastering Your Fears and FobiasDocumento174 pagineCraske - Mastering Your Fears and Fobiasjuliana218Nessuna valutazione finora
- Suggested Answers Spring 2015 Examinations 1 of 8: Strategic Management Accounting - Semester-6Documento8 pagineSuggested Answers Spring 2015 Examinations 1 of 8: Strategic Management Accounting - Semester-6Abdul BasitNessuna valutazione finora
- Lecture 3 - Marriage and Marriage PaymentsDocumento11 pagineLecture 3 - Marriage and Marriage PaymentsGrace MguniNessuna valutazione finora
- UNECE-Turkey-TCDO-Rail Freight Traffic in Euro-Asian LinksDocumento20 pagineUNECE-Turkey-TCDO-Rail Freight Traffic in Euro-Asian LinksArseneNessuna valutazione finora
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Da EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Valutazione: 4.5 su 5 stelle4.5/5 (120)
- PDFDocumento18 paginePDFDental LabNessuna valutazione finora
- Supply DemandProblems With Solutions, Part 1Documento16 pagineSupply DemandProblems With Solutions, Part 1deviNessuna valutazione finora
- Wiring DiagramsDocumento69 pagineWiring DiagramsMahdiNessuna valutazione finora
- Indian Consumer - Goldman Sachs ReportDocumento22 pagineIndian Consumer - Goldman Sachs Reporthvsboua100% (1)
- A Case Study From The: PhilippinesDocumento2 pagineA Case Study From The: PhilippinesNimNessuna valutazione finora
- Telstra InterviewsDocumento3 pagineTelstra InterviewsDaxShenNessuna valutazione finora
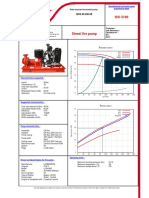
- NOS 65-200-90x60-30KWD PDFDocumento2 pagineNOS 65-200-90x60-30KWD PDFDao The ThangNessuna valutazione finora
- Her Body and Other Parties: StoriesDa EverandHer Body and Other Parties: StoriesValutazione: 4 su 5 stelle4/5 (821)