Potrebbero piacerti anche
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDa EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryValutazione: 3.5 su 5 stelle3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Da EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Valutazione: 4.5 su 5 stelle4.5/5 (121)
- Grit: The Power of Passion and PerseveranceDa EverandGrit: The Power of Passion and PerseveranceValutazione: 4 su 5 stelle4/5 (588)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDa EverandNever Split the Difference: Negotiating As If Your Life Depended On ItValutazione: 4.5 su 5 stelle4.5/5 (838)
- The Little Book of Hygge: Danish Secrets to Happy LivingDa EverandThe Little Book of Hygge: Danish Secrets to Happy LivingValutazione: 3.5 su 5 stelle3.5/5 (400)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDa EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaValutazione: 4.5 su 5 stelle4.5/5 (266)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDa EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeValutazione: 4 su 5 stelle4/5 (5794)
- Her Body and Other Parties: StoriesDa EverandHer Body and Other Parties: StoriesValutazione: 4 su 5 stelle4/5 (821)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDa EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreValutazione: 4 su 5 stelle4/5 (1090)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDa EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyValutazione: 3.5 su 5 stelle3.5/5 (2259)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDa EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersValutazione: 4.5 su 5 stelle4.5/5 (345)
- Shoe Dog: A Memoir by the Creator of NikeDa EverandShoe Dog: A Memoir by the Creator of NikeValutazione: 4.5 su 5 stelle4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerDa EverandThe Emperor of All Maladies: A Biography of CancerValutazione: 4.5 su 5 stelle4.5/5 (271)
- Team of Rivals: The Political Genius of Abraham LincolnDa EverandTeam of Rivals: The Political Genius of Abraham LincolnValutazione: 4.5 su 5 stelle4.5/5 (234)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDa EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceValutazione: 4 su 5 stelle4/5 (895)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDa EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureValutazione: 4.5 su 5 stelle4.5/5 (474)
- On Fire: The (Burning) Case for a Green New DealDa EverandOn Fire: The (Burning) Case for a Green New DealValutazione: 4 su 5 stelle4/5 (74)
- The Yellow House: A Memoir (2019 National Book Award Winner)Da EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Valutazione: 4 su 5 stelle4/5 (98)
- The Unwinding: An Inner History of the New AmericaDa EverandThe Unwinding: An Inner History of the New AmericaValutazione: 4 su 5 stelle4/5 (45)
- (123doc) - Toefl-Reading-Comprehension-Test-41Documento8 pagine(123doc) - Toefl-Reading-Comprehension-Test-41Steve XNessuna valutazione finora
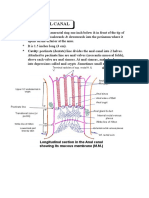
- Anatomy Anal CanalDocumento14 pagineAnatomy Anal CanalBela Ronaldoe100% (1)
- Service Manual: SV01-NHX40AX03-01E NHX4000 MSX-853 Axis Adjustment Procedure of Z-Axis Zero Return PositionDocumento5 pagineService Manual: SV01-NHX40AX03-01E NHX4000 MSX-853 Axis Adjustment Procedure of Z-Axis Zero Return Positionmahdi elmay100% (3)
- Analysis of Electric Machinery Krause Manual Solution PDFDocumento2 pagineAnalysis of Electric Machinery Krause Manual Solution PDFKuldeep25% (8)
- IEC ShipsDocumento6 pagineIEC ShipsdimitaringNessuna valutazione finora
- Lesson 5 Designing and Developing Social AdvocacyDocumento27 pagineLesson 5 Designing and Developing Social Advocacydaniel loberizNessuna valutazione finora
- DQ Vibro SifterDocumento13 pagineDQ Vibro SifterDhaval Chapla67% (3)
- Modulo EminicDocumento13 pagineModulo EminicAndreaNessuna valutazione finora
- Unit 7: Anthropology: Q2e Listening & Speaking 4: Audio ScriptDocumento6 pagineUnit 7: Anthropology: Q2e Listening & Speaking 4: Audio ScriptĐại học Bạc Liêu Truyền thông100% (1)
- Quick Help For EDI SEZ IntegrationDocumento2 pagineQuick Help For EDI SEZ IntegrationsrinivasNessuna valutazione finora
- Making Effective Powerpoint Presentations: October 2014Documento18 pagineMaking Effective Powerpoint Presentations: October 2014Mariam TchkoidzeNessuna valutazione finora
- Organizational ConflictDocumento22 pagineOrganizational ConflictTannya AlexandraNessuna valutazione finora
- Tplink Eap110 Qig EngDocumento20 pagineTplink Eap110 Qig EngMaciejNessuna valutazione finora
- The Homework Song FunnyDocumento5 pagineThe Homework Song Funnyers57e8s100% (1)
- Comparitive Study ICICI & HDFCDocumento22 pagineComparitive Study ICICI & HDFCshah faisal100% (1)
- II 2022 06 Baena-Rojas CanoDocumento11 pagineII 2022 06 Baena-Rojas CanoSebastian GaonaNessuna valutazione finora
- PED003Documento1 paginaPED003ely mae dag-umanNessuna valutazione finora
- UC 20 - Produce Cement Concrete CastingDocumento69 pagineUC 20 - Produce Cement Concrete Castingtariku kiros100% (2)
- Outdoor Air Pollution: Sources, Health Effects and SolutionsDocumento20 pagineOutdoor Air Pollution: Sources, Health Effects and SolutionsCamelia RadulescuNessuna valutazione finora
- Borang Ambulans CallDocumento2 pagineBorang Ambulans Callleo89azman100% (1)
- Tetralogy of FallotDocumento8 pagineTetralogy of FallotHillary Faye FernandezNessuna valutazione finora
- Huawei R4815N1 DatasheetDocumento2 pagineHuawei R4815N1 DatasheetBysNessuna valutazione finora
- Guidelines For SKPMG2 TSSP - Draft For Consultation 10.10.17Documento5 pagineGuidelines For SKPMG2 TSSP - Draft For Consultation 10.10.17zqhnazNessuna valutazione finora
- Existential ThreatsDocumento6 pagineExistential Threatslolab_4Nessuna valutazione finora
- PyhookDocumento23 paginePyhooktuan tuanNessuna valutazione finora
- The Use of Air Cooled Heat Exchangers in Mechanical Seal Piping Plans - SnyderDocumento7 pagineThe Use of Air Cooled Heat Exchangers in Mechanical Seal Piping Plans - SnyderJaime Ocampo SalgadoNessuna valutazione finora
- DP 2 Human IngenuityDocumento8 pagineDP 2 Human Ingenuityamacodoudiouf02Nessuna valutazione finora
- Deal Report Feb 14 - Apr 14Documento26 pagineDeal Report Feb 14 - Apr 14BonviNessuna valutazione finora
- The Magic DrumDocumento185 pagineThe Magic Drumtanishgiri2012Nessuna valutazione finora
- DNA ReplicationDocumento19 pagineDNA ReplicationLouis HilarioNessuna valutazione finora