Potrebbero piacerti anche
- Research Proposal: Chapter 2Documento6 pagineResearch Proposal: Chapter 2mirashikaNessuna valutazione finora
- Research PaperDocumento14 pagineResearch PaperJarise Maisa50% (4)
- Research Problem, Hypotheses and VariablesDocumento11 pagineResearch Problem, Hypotheses and VariablesGILTON MADEME88% (33)
- Three Types of ResearchDocumento8 pagineThree Types of Researchasghaznavi95% (19)
- Social Work Practice and Social Welfare Policy in The United States A History (Philip R. Popple)Documento393 pagineSocial Work Practice and Social Welfare Policy in The United States A History (Philip R. Popple)5819Elis RahmawatiNessuna valutazione finora
- Creative Nonfiction: Quarter 3 - Module 4: Principles, Elements, and Devices of Creative NonfictionDocumento18 pagineCreative Nonfiction: Quarter 3 - Module 4: Principles, Elements, and Devices of Creative NonfictionHernan Pacatang100% (4)
- Sample Quantitative ResearchDocumento62 pagineSample Quantitative ResearchChimar DhineeshaNessuna valutazione finora
- Chapter 3Documento4 pagineChapter 3Rochelle May CanlasNessuna valutazione finora
- Research PaperDocumento4 pagineResearch PaperJOHANNA MAE ERODIASNessuna valutazione finora
- Chapter 3 (Amedzror)Documento4 pagineChapter 3 (Amedzror)Quame Enam KunuNessuna valutazione finora
- Quantitative ResearchDocumento7 pagineQuantitative ResearchFauzan ZifaNessuna valutazione finora
- CHAPTER 3 and 4Documento12 pagineCHAPTER 3 and 4albert matandagNessuna valutazione finora
- Quantitative Research Methodology Assignment 2Documento12 pagineQuantitative Research Methodology Assignment 2Sobeeha Abdul LatheefNessuna valutazione finora
- Parts of Research PaperDocumento19 pagineParts of Research PaperGayle100% (3)
- Chapter IiiDocumento3 pagineChapter Iiikaycel ramosNessuna valutazione finora
- ThesisDocumento94 pagineThesisAimzyl Operio TriaNessuna valutazione finora
- Quantitative Vs QualitativeDocumento14 pagineQuantitative Vs QualitativeRúben SousaNessuna valutazione finora
- CHAPTER III RESEARCH FinalDocumento3 pagineCHAPTER III RESEARCH FinalLovely MedranoBiscaro Dela CruzNessuna valutazione finora
- Qualitative ResearchDocumento14 pagineQualitative Researchhayleymeredith67% (3)
- Qualitative ResearchDocumento7 pagineQualitative ResearchInggy Yuliani P , MPd.80% (5)
- Study Habits and Attitudes LocalDocumento19 pagineStudy Habits and Attitudes LocalDaverianne Quibael Beltrano75% (8)
- Theoretical FrameworkDocumento5 pagineTheoretical FrameworkElusive IrisNessuna valutazione finora
- Quantitative Research DesignDocumento8 pagineQuantitative Research DesignAufa liaNessuna valutazione finora
- Sample Research PaperDocumento7 pagineSample Research PaperJouie Rose Palo100% (2)
- Text Speaks and Its Effect On Adolescents' Spelling Proficiency: Ma. Christine JoguilonDocumento21 pagineText Speaks and Its Effect On Adolescents' Spelling Proficiency: Ma. Christine Joguilonanon_63691992% (13)
- Qualitative ResearchDocumento31 pagineQualitative Researchrimuly100% (5)
- Quota SamplingDocumento6 pagineQuota SamplingKeking Xoniuqe100% (1)
- A Purposive Sampling Is A Form of Sampling in Which The Selection of The Sample Is Based On The Judgment or Perception of The Researcher As To Which Subjects Best Fit The Criteria of The StudyDocumento5 pagineA Purposive Sampling Is A Form of Sampling in Which The Selection of The Sample Is Based On The Judgment or Perception of The Researcher As To Which Subjects Best Fit The Criteria of The StudyIcey Songco ValenciaNessuna valutazione finora
- Unit 2 Qualitative Research 1. The Nature of Qualitative ResearchDocumento77 pagineUnit 2 Qualitative Research 1. The Nature of Qualitative ResearchArchana PokharelNessuna valutazione finora
- PR2 - Week 1 - Research IntroductionDocumento6 paginePR2 - Week 1 - Research IntroductionJasmine Nouvel Soriaga Cruz100% (1)
- Quantitative and Qualitative ResearchDocumento32 pagineQuantitative and Qualitative ResearchShahinHannahMarjan50% (2)
- Purposes of DiscourseDocumento2 paginePurposes of DiscourseChar LayiNessuna valutazione finora
- Independent and Dependent VariablesDocumento6 pagineIndependent and Dependent VariablesDawn Lewis100% (2)
- Data CollectionDocumento21 pagineData CollectionJasmeenKaurNessuna valutazione finora
- Gavileño - Critique1 (Hoang Et Al 2020)Documento7 pagineGavileño - Critique1 (Hoang Et Al 2020)Reymart Jade Gavileno100% (1)
- Quota Sampling TechniqueDocumento5 pagineQuota Sampling TechniqueSer GiboNessuna valutazione finora
- 5 Types of Qualitative ResearchDocumento10 pagine5 Types of Qualitative ResearchPeregrin Took100% (1)
- Sampling and Sample SurveyDocumento15 pagineSampling and Sample SurveySUFIAUN FERDOUS100% (1)
- Sop and Questionnaire - Mam JaneDocumento3 pagineSop and Questionnaire - Mam JanePaul Christian VillaverdeNessuna valutazione finora
- Chapter 3 ThesisDocumento11 pagineChapter 3 ThesisDada N. NahilNessuna valutazione finora
- Sampling MethodsDocumento6 pagineSampling Methods'Sari' Siti Khadijah HapsariNessuna valutazione finora
- Language Learning Anxiety and Oral Perfo PDFDocumento10 pagineLanguage Learning Anxiety and Oral Perfo PDFMel MacatangayNessuna valutazione finora
- Chapter III - MethodologyDocumento3 pagineChapter III - MethodologyAlthea OrolazaNessuna valutazione finora
- How Different Time-Management Techniques Affect The Academic Performance of A Senior High-School StudentDocumento18 pagineHow Different Time-Management Techniques Affect The Academic Performance of A Senior High-School StudentJan Ivan MontenegroNessuna valutazione finora
- What Is Research GAPDocumento5 pagineWhat Is Research GAPAdeel Manzar100% (1)
- Samples of Qualitative ResearchDocumento2 pagineSamples of Qualitative ResearchMichelle Berme100% (2)
- Qualitative and Quantitative Research MethodsDocumento6 pagineQualitative and Quantitative Research Methodsseagoddess_simo100% (2)
- Research ProposalDocumento4 pagineResearch Proposalsalman100% (2)
- MethodologyDocumento2 pagineMethodologyakanksha_cNessuna valutazione finora
- Academic Validation, Motivation, and Anxiety Among College Students in Lipa City CollegesDocumento26 pagineAcademic Validation, Motivation, and Anxiety Among College Students in Lipa City CollegesPsychology and Education: A Multidisciplinary JournalNessuna valutazione finora
- Chapter Three Research Methodology 3.0. Introduction: March 2020Documento6 pagineChapter Three Research Methodology 3.0. Introduction: March 2020Danica SoriaNessuna valutazione finora
- Running Head: Quantitative Critique 1Documento10 pagineRunning Head: Quantitative Critique 1ncory79100% (12)
- Importance of Research - Research Is As Important As Any Field of Study. Its Significance Cuts Across All DisciplinesDocumento1 paginaImportance of Research - Research Is As Important As Any Field of Study. Its Significance Cuts Across All DisciplinesMichael James AnanayoNessuna valutazione finora
- Local StudiesDocumento7 pagineLocal StudiesAgnes GamboaNessuna valutazione finora
- Research Report Soft Copy (Qualitative and Quantitative)Documento2 pagineResearch Report Soft Copy (Qualitative and Quantitative)Jean Gulleban100% (2)
- Uses and GratificationDocumento6 pagineUses and GratificationHashim KhanNessuna valutazione finora
- Quantitative Research A Complete Guide - 2020 EditionDa EverandQuantitative Research A Complete Guide - 2020 EditionNessuna valutazione finora
- Talimongan Christine PRDocumento10 pagineTalimongan Christine PRchristineNessuna valutazione finora
- Solved Paper 837Documento11 pagineSolved Paper 837Nauman JavedNessuna valutazione finora
- Educational - Research PowerpointDocumento22 pagineEducational - Research PowerpointPapa King100% (1)
- Research HypothesisDocumento7 pagineResearch HypothesisSherwin Jay BentazarNessuna valutazione finora
- PR2 Week 6Documento10 paginePR2 Week 6Camille CornelioNessuna valutazione finora
- Writing Critical Literature ReviewDocumento7 pagineWriting Critical Literature Reviewhjaromptb100% (6)
- Literature ReviewDocumento30 pagineLiterature Reviewhjaromptb84% (25)
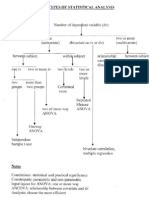
- Types of Statistical AnalysisDocumento2 pagineTypes of Statistical Analysishjaromptb100% (5)
- Chapter 1 To Chapter 5-Making The Connections!Documento116 pagineChapter 1 To Chapter 5-Making The Connections!hjaromptb100% (4)
- Organizing The Literature Review Based On The Theoretical FrameworkDocumento29 pagineOrganizing The Literature Review Based On The Theoretical Frameworkhjaromptb100% (18)
- Matching Constructivism and QualitativeDocumento14 pagineMatching Constructivism and Qualitativehjaromptb100% (3)
- Excellent Thesis - Metacognitive Scaffolding and Cooperative LearningDocumento217 pagineExcellent Thesis - Metacognitive Scaffolding and Cooperative Learninghjaromptb100% (36)
- Writing Critical Literature ReviewDocumento7 pagineWriting Critical Literature Reviewhjaromptb100% (6)
- Quantitative and Qualitative ResearchDocumento42 pagineQuantitative and Qualitative Researchhjaromptb100% (8)
- What Constitute Excellence in ResearchDocumento35 pagineWhat Constitute Excellence in Researchhjaromptb100% (6)
- Literature ReviewDocumento30 pagineLiterature Reviewhjaromptb84% (25)
- Analysing Quantitative DataDocumento25 pagineAnalysing Quantitative Datahjaromptb100% (4)
- Qualitative ResearchDocumento52 pagineQualitative Researchhjaromptb97% (31)
- Gain Score in Data AnalysisDocumento1 paginaGain Score in Data Analysishjaromptb100% (1)
- 40 Questions To Improve Your ResearchDocumento3 pagine40 Questions To Improve Your Researchhjaromptb100% (19)
- Development of Ideas and Refining Research TopicsDocumento25 pagineDevelopment of Ideas and Refining Research Topicshjaromptb100% (9)
- Why Cant Null Hyp Be RejectedDocumento1 paginaWhy Cant Null Hyp Be Rejectedhjaromptb100% (2)
- Literature Review - How To Go About It!Documento18 pagineLiterature Review - How To Go About It!hjaromptb100% (19)
- Challenges and Issues in PHD ResearchDocumento12 pagineChallenges and Issues in PHD Researchhjaromptb100% (8)
- Cambridge Primary Progression Test - English As A Second Language 2016 Stage 3 - Paper 1 Question PDFDocumento11 pagineCambridge Primary Progression Test - English As A Second Language 2016 Stage 3 - Paper 1 Question PDFTumwesigye robert100% (3)
- Portfolio Cover Sheet - Cap Debates (Critical Thinking)Documento2 paginePortfolio Cover Sheet - Cap Debates (Critical Thinking)Aisling GearhartNessuna valutazione finora
- SecA - Group1 - Can Nice Guys Finish FirstDocumento18 pagineSecA - Group1 - Can Nice Guys Finish FirstVijay KrishnanNessuna valutazione finora
- Select Bibliography of Works Relating To ProsopographyDocumento23 pagineSelect Bibliography of Works Relating To ProsopographyFridrich DI Erste MejezelaNessuna valutazione finora
- Minister Darrell - Gold Bermudians RemarksDocumento2 pagineMinister Darrell - Gold Bermudians RemarksBernewsAdminNessuna valutazione finora
- Elements of NonfictionDocumento2 pagineElements of Nonfiction본술파100% (1)
- Student Handbook PDFDocumento51 pagineStudent Handbook PDFAssad SaghirNessuna valutazione finora
- Defining Leadership: A Review of Past, Present, and Future IdeasDocumento5 pagineDefining Leadership: A Review of Past, Present, and Future IdeasAngelica WiraNessuna valutazione finora
- Phonics Sentences Blends and Digraphs From A Teachable TeacherDocumento37 paginePhonics Sentences Blends and Digraphs From A Teachable TeacherDeepti Darak100% (4)
- Evaluation of Evidence-Based Practices in Online Learning: A Meta-Analysis and Review of Online Learning StudiesDocumento93 pagineEvaluation of Evidence-Based Practices in Online Learning: A Meta-Analysis and Review of Online Learning Studiesmario100% (3)
- (Bible & Postcolonialism) Fernando F. Segovia, Stephen D. Moore-Postcolonial Biblical Criticism - Interdisciplinary Intersections-Bloomsbury T&T Clark (2005) PDFDocumento215 pagine(Bible & Postcolonialism) Fernando F. Segovia, Stephen D. Moore-Postcolonial Biblical Criticism - Interdisciplinary Intersections-Bloomsbury T&T Clark (2005) PDFGreg O'Ruffus100% (1)
- NTT PTT: Nursery Teacher's Training Teacher's Training Primary Teacher's Training Teacher's TrainingDocumento15 pagineNTT PTT: Nursery Teacher's Training Teacher's Training Primary Teacher's Training Teacher's TrainingShashank SaxenaNessuna valutazione finora
- Lesson Plan Subject: Math Trainee: Razna Topic or Theme: Fruits Class: KG1 Date & Duration: 40 Minutes Trainee Personal GoalsDocumento5 pagineLesson Plan Subject: Math Trainee: Razna Topic or Theme: Fruits Class: KG1 Date & Duration: 40 Minutes Trainee Personal GoalsRazna FarhanNessuna valutazione finora
- Proper Servicing: A Future Nail Technician Proper Positions and Gestures in Nail Care ServicingDocumento8 pagineProper Servicing: A Future Nail Technician Proper Positions and Gestures in Nail Care ServicingCaister Jherald SamatraNessuna valutazione finora
- The Daily Tar Heel For November 8, 2010Documento12 pagineThe Daily Tar Heel For November 8, 2010The Daily Tar HeelNessuna valutazione finora
- (2019) Piecewise Reproducing Kernel Method For Linear Impulsive Delay Differential Equations With Piecewise Constant ArgumentsDocumento10 pagine(2019) Piecewise Reproducing Kernel Method For Linear Impulsive Delay Differential Equations With Piecewise Constant ArgumentsAlejandro ChiuNessuna valutazione finora
- 05 Preprocessing and Sklearn - SlidesDocumento81 pagine05 Preprocessing and Sklearn - SlidesRatneswar SaikiaNessuna valutazione finora
- ASSESSMENT2 - Question - MAT183 - MAC2023Documento5 pagineASSESSMENT2 - Question - MAT183 - MAC2023Asy 11Nessuna valutazione finora
- Course - Home Course For CIPD Level 5 Certificate in HRMDocumento2 pagineCourse - Home Course For CIPD Level 5 Certificate in HRMPiotr NowakNessuna valutazione finora
- English 8 Quarter 2 TOSDocumento27 pagineEnglish 8 Quarter 2 TOSKathrina BonodeNessuna valutazione finora
- FIITJEE1Documento5 pagineFIITJEE1Raunak RoyNessuna valutazione finora
- Region Province Reference Number Learner IDDocumento10 pagineRegion Province Reference Number Learner IDLloydie LopezNessuna valutazione finora
- 1.1 Physical Qualtities CIE IAL Physics MS Theory UnlockedDocumento6 pagine1.1 Physical Qualtities CIE IAL Physics MS Theory Unlockedmaze.putumaNessuna valutazione finora
- The ResearchersDocumento28 pagineThe Researchersricky sto tomasNessuna valutazione finora
- Piaget Bruner VygotskyDocumento31 paginePiaget Bruner VygotskyHershey Mangaba0% (1)
- Eight: Consumer Attitude Formation and ChangeDocumento56 pagineEight: Consumer Attitude Formation and ChangeShashank KrishnaNessuna valutazione finora
- What Is Educational ResearchDocumento14 pagineWhat Is Educational ResearchAngélica Mestra AleanNessuna valutazione finora
- Gui817 JMS PDFDocumento10 pagineGui817 JMS PDFPhilBoardResultsNessuna valutazione finora