Potrebbero piacerti anche
- Cheatsheet PDFDocumento4 pagineCheatsheet PDFJDTerex100% (1)
- Quantum Scattering Basic ProblemsDocumento23 pagineQuantum Scattering Basic ProblemsJeison RojasNessuna valutazione finora
- Atlas Copco: Parts ListDocumento152 pagineAtlas Copco: Parts ListChathura SenanayakeNessuna valutazione finora
- Vector Calculus Cheat SheetDocumento1 paginaVector Calculus Cheat SheetAyisha A. GillNessuna valutazione finora
- 36-708 Statistical Machine Learning Homework #4 Solutions: DUE: April 19, 2019Documento16 pagine36-708 Statistical Machine Learning Homework #4 Solutions: DUE: April 19, 2019SNessuna valutazione finora
- Assignment 1 DESA 1004 - Paulo Ricardo Rangel Maciel PimentaDocumento4 pagineAssignment 1 DESA 1004 - Paulo Ricardo Rangel Maciel PimentaPaulo PimentaNessuna valutazione finora
- Problem Set - 6: MATHEMATICS-II (MA10002)Documento2 pagineProblem Set - 6: MATHEMATICS-II (MA10002)MaulinduNessuna valutazione finora
- Examen Ejercicio 2Documento5 pagineExamen Ejercicio 2Candy Morayta CanoNessuna valutazione finora
- Examen Ejercicio 2Documento5 pagineExamen Ejercicio 2Candy Morayta CanoNessuna valutazione finora
- Elliptic Curve CryptographyDocumento3 pagineElliptic Curve CryptographyMikkelsNessuna valutazione finora
- Pde As 2Documento7 paginePde As 2sahlewel weldemichaelNessuna valutazione finora
- Segédanyag ÖsszesDocumento1 paginaSegédanyag ÖsszesBalázs MegyeryNessuna valutazione finora
- Electro PDFDocumento5 pagineElectro PDFJhonNessuna valutazione finora
- Formula SheetDocumento3 pagineFormula SheetSimthembileNessuna valutazione finora
- VzorceDocumento1 paginaVzorceebymab.meNessuna valutazione finora
- Tutorial 11Documento3 pagineTutorial 11jagriti kumariNessuna valutazione finora
- Practice Questions Set: Green's FunctionsDocumento2 paginePractice Questions Set: Green's FunctionsBishnu LamichhaneNessuna valutazione finora
- Surfaceareaandvolume Ofatorus: by JakoblindbladblaavandDocumento3 pagineSurfaceareaandvolume Ofatorus: by JakoblindbladblaavandabasakNessuna valutazione finora
- MATH1231 CALCULUS CHAPTER 2B PARTIAL FRACTIONSDocumento27 pagineMATH1231 CALCULUS CHAPTER 2B PARTIAL FRACTIONSmax zebalaNessuna valutazione finora
- Estat Istica MAEG 2013/14 Formul ArioDocumento3 pagineEstat Istica MAEG 2013/14 Formul ArioBeatriz FerreiraNessuna valutazione finora
- Math Summary: Inverse, Composite, Conic SectionsDocumento4 pagineMath Summary: Inverse, Composite, Conic SectionsnursyadzwinaNessuna valutazione finora
- Griffith's Introduction To Quantum Mechanics Problem 3.30Documento3 pagineGriffith's Introduction To Quantum Mechanics Problem 3.30palisonNessuna valutazione finora
- Exercises Analysis 2 (2WA40) Lecture 22Documento2 pagineExercises Analysis 2 (2WA40) Lecture 22Andrei PatularuNessuna valutazione finora
- Functions: B Such That (X, Y) F: ADocumento4 pagineFunctions: B Such That (X, Y) F: AasshhaaNessuna valutazione finora
- Sol T2Documento2 pagineSol T2Sohini RoyNessuna valutazione finora
- Curve Alignment With Known CorrespondencesDocumento3 pagineCurve Alignment With Known CorrespondencesAmadeusNessuna valutazione finora
- Calculus Booklet PDFDocumento6 pagineCalculus Booklet PDFMuhammad IzzuanNessuna valutazione finora
- 026 Ahmed IntegralDocumento9 pagine026 Ahmed Integraljuniotor2023Nessuna valutazione finora
- Jackson 3.3: Stanislav Boldyrev, Physics Department, UW-MadisonDocumento4 pagineJackson 3.3: Stanislav Boldyrev, Physics Department, UW-MadisonDennis Diaz TrujilloNessuna valutazione finora
- Homework 9. Solutions. 1. Find Coordinate Basis Vectors, First Quadratic Form, Unit Normal Vector Field, Shape Operator and GaussianDocumento8 pagineHomework 9. Solutions. 1. Find Coordinate Basis Vectors, First Quadratic Form, Unit Normal Vector Field, Shape Operator and GaussianKiprop VentureNessuna valutazione finora
- Lecture 6 Covering Numbers and ChainingDocumento4 pagineLecture 6 Covering Numbers and ChainingBoul chandra GaraiNessuna valutazione finora
- Parte 10Documento7 pagineParte 10Elohim Ortiz CaballeroNessuna valutazione finora
- Indian Institute of Science: Problem 1Documento4 pagineIndian Institute of Science: Problem 1ChandreshSinghNessuna valutazione finora
- Øksendal Solutions ManualDocumento35 pagineØksendal Solutions ManualJose RamirezNessuna valutazione finora
- Functions: B Such That (X, Y) F: ADocumento4 pagineFunctions: B Such That (X, Y) F: Aeamcetmaterials100% (11)
- RELATIONS AND FUNCTIONSDocumento16 pagineRELATIONS AND FUNCTIONSPranavNessuna valutazione finora
- The Schrodinger Equation: Fisika KuantumDocumento13 pagineThe Schrodinger Equation: Fisika KuantumIndah pratiwiNessuna valutazione finora
- Problem Set 15Documento3 pagineProblem Set 15bgiangre8372Nessuna valutazione finora
- SolutionsDocumento16 pagineSolutionsKireziNessuna valutazione finora
- FormulaDocumento1 paginaFormulafaimy josephNessuna valutazione finora
- Solution Series 7Documento6 pagineSolution Series 7edisonNessuna valutazione finora
- Functii Continue: R. I. BalilescuDocumento3 pagineFunctii Continue: R. I. BalilescuRalu BalilescuNessuna valutazione finora
- QM2 HM5 SolutionsDocumento11 pagineQM2 HM5 Solutionsjog1Nessuna valutazione finora
- Notações Dos AlgoritimosDocumento10 pagineNotações Dos AlgoritimosJonathan MessiasNessuna valutazione finora
- Formul Ario Fundamentos de Matem Atica (M1012) Matem Atica I (M1034) 2018/2019 DerivadasDocumento2 pagineFormul Ario Fundamentos de Matem Atica (M1012) Matem Atica I (M1034) 2018/2019 DerivadasPaula De Oliveira PintoNessuna valutazione finora
- 105S109 CS15L01Documento2 pagine105S109 CS15L01Jie MaNessuna valutazione finora
- Midterm 2 potentially useful informationDocumento2 pagineMidterm 2 potentially useful informationChristian Alic KelleyNessuna valutazione finora
- SEEMOUS 2009 ProblemsDocumento4 pagineSEEMOUS 2009 ProblemsHipstersdssadadNessuna valutazione finora
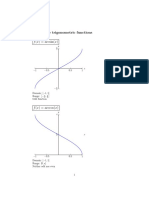
- Graphs of Inverse Trigonometric Functions and Logarithmic Functions2019Documento3 pagineGraphs of Inverse Trigonometric Functions and Logarithmic Functions2019LeviNessuna valutazione finora
- An Alternate Proof For A Case of A Malmsten IntegralDocumento5 pagineAn Alternate Proof For A Case of A Malmsten IntegralAngel RomeroNessuna valutazione finora
- Math 331 HW1Documento4 pagineMath 331 HW1Alex L WangNessuna valutazione finora
- Gamma DistributionDocumento3 pagineGamma Distributionqwertypushkar123Nessuna valutazione finora
- Solución Ecuaciones de Bateman (Articulo)Documento6 pagineSolución Ecuaciones de Bateman (Articulo)GeraldinNessuna valutazione finora
- DynamicPortfolioChoiceWithFrictions AppendiDocumento15 pagineDynamicPortfolioChoiceWithFrictions AppendiDiego MakaseviciusNessuna valutazione finora
- Sec 4-7Documento15 pagineSec 4-7FlorinNessuna valutazione finora
- Les Fonctions TrigonométriquesDocumento2 pagineLes Fonctions Trigonométriquesamani benNessuna valutazione finora
- Linear Algebra Exercises - EigenvaluesDocumento9 pagineLinear Algebra Exercises - EigenvaluesCayuss Andrei MihăițoaiaNessuna valutazione finora
- MATH4052 Supplementary Exercise 2Documento4 pagineMATH4052 Supplementary Exercise 2John ChanNessuna valutazione finora
- ANT - Unit 2 Part 2Documento15 pagineANT - Unit 2 Part 2Swarna Priya RNessuna valutazione finora
- Orbits in Axisymmetric PotentialsDocumento28 pagineOrbits in Axisymmetric PotentialsMHSouNessuna valutazione finora
- mth asmt 8Documento2 paginemth asmt 8Mausam JhaNessuna valutazione finora
- Tables of Weber Functions: Mathematical Tables, Vol. 1Da EverandTables of Weber Functions: Mathematical Tables, Vol. 1Nessuna valutazione finora
- Company Directive: Standard Technique: Sd8A/3 Relating To Revision of Overhead Line RatingsDocumento33 pagineCompany Directive: Standard Technique: Sd8A/3 Relating To Revision of Overhead Line RatingsSathish KumarNessuna valutazione finora
- Dosing Pump Innovata Drive ConceptDocumento5 pagineDosing Pump Innovata Drive ConceptgarpNessuna valutazione finora
- Chemistry Project: To Study The Quantity of Casein Present in Different Samples of MilkDocumento14 pagineChemistry Project: To Study The Quantity of Casein Present in Different Samples of Milkveenu68Nessuna valutazione finora
- GicDocumento155 pagineGicNikita KadamNessuna valutazione finora
- Assignment 2Documento2 pagineAssignment 2ue06037Nessuna valutazione finora
- Electric Current and Charge RelationshipDocumento9 pagineElectric Current and Charge RelationshipLokman HakimNessuna valutazione finora
- Stiffness of Cable-Based Parallel Manipulators With Application To Stability AnalysisDocumento8 pagineStiffness of Cable-Based Parallel Manipulators With Application To Stability AnalysisNhật MinhNessuna valutazione finora
- Chapter 14 Modern SpectrosDocumento24 pagineChapter 14 Modern SpectrosChicken ChickenNessuna valutazione finora
- HP Officejet Pro X476 X576 TroubleshootingDocumento152 pagineHP Officejet Pro X476 X576 Troubleshootingjason7493Nessuna valutazione finora
- Physics: Investigatory ProjectDocumento10 paginePhysics: Investigatory ProjectSourav SethuNessuna valutazione finora
- SI Analysis: The Second Generation of Flow Injection TechniquesDocumento2 pagineSI Analysis: The Second Generation of Flow Injection TechniquesRu Z KiNessuna valutazione finora
- Introduction to Nanorobotics and Their ApplicationsDocumento25 pagineIntroduction to Nanorobotics and Their ApplicationsSharifa RahamadullahNessuna valutazione finora
- A Method of Solving Certain Nonlinear DiophantineDocumento3 pagineA Method of Solving Certain Nonlinear DiophantineArsh TewariNessuna valutazione finora
- Glazed Aluminum Curtain Walls (Thermawall SM 2600)Documento12 pagineGlazed Aluminum Curtain Walls (Thermawall SM 2600)RsjBugtongNessuna valutazione finora
- EPA 1668 A, Ag-2003Documento129 pagineEPA 1668 A, Ag-2003Karina Rondon RivadeneyraNessuna valutazione finora
- F1223 1479757-1Documento9 pagineF1223 1479757-1Thaweekarn ChangthongNessuna valutazione finora
- 079322C Int MR LD Int 1543 0004 3427 01Documento1 pagina079322C Int MR LD Int 1543 0004 3427 01bolat.kukuzovNessuna valutazione finora
- The D and F Block Elements PDFDocumento8 pagineThe D and F Block Elements PDFTr Mazhar PunjabiNessuna valutazione finora
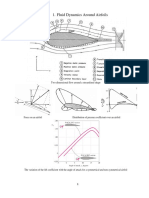
- Overview Aerodynamics 2017Documento10 pagineOverview Aerodynamics 2017marcoNessuna valutazione finora
- Datasheet MPX5100DPDocumento16 pagineDatasheet MPX5100DPKemahyanto Exaudi SiahaanNessuna valutazione finora
- Wiring DiagramDocumento24 pagineWiring DiagramReji Raju0% (1)
- Study Guide For Mid-Term 3 SolutionsDocumento8 pagineStudy Guide For Mid-Term 3 Solutionskuumba0% (3)
- 2 B.tech Biotechnology 27 38Documento38 pagine2 B.tech Biotechnology 27 38Anju GuptaNessuna valutazione finora
- Air Preheater Technical PaperDocumento21 pagineAir Preheater Technical Paperchekoti koushikNessuna valutazione finora
- Optimum Penstocks For Low Head Microhydro Schemes - Alexander, Giddens - 2008Documento13 pagineOptimum Penstocks For Low Head Microhydro Schemes - Alexander, Giddens - 2008cbarajNessuna valutazione finora
- Vector CalculusDocumento62 pagineVector CalculuswaleedNessuna valutazione finora
- HW2 Solutions FinalDocumento5 pagineHW2 Solutions Finalpande_100Nessuna valutazione finora
- 6314Documento18 pagine6314Simone RizzoNessuna valutazione finora