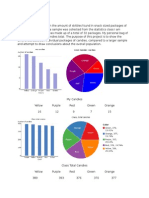
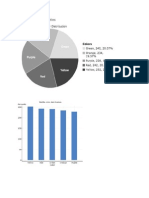
Potrebbero piacerti anche
- Math 1040 Skittles Term ProjectDocumento9 pagineMath 1040 Skittles Term Projectapi-319881085Nessuna valutazione finora
- Skittles ProjectDocumento9 pagineSkittles Projectapi-242873849Nessuna valutazione finora
- Skittles Term Project StatsDocumento8 pagineSkittles Term Project Statsapi-302549779Nessuna valutazione finora
- StatsfinalprojectDocumento7 pagineStatsfinalprojectapi-325102852Nessuna valutazione finora
- Skittles ProjectDocumento6 pagineSkittles Projectapi-319345408Nessuna valutazione finora
- TP 2 StatsDocumento5 pagineTP 2 Statsapi-240850453Nessuna valutazione finora
- Final Math ProjectDocumento7 pagineFinal Math Projectapi-316775963Nessuna valutazione finora
- Skittles AssignmentDocumento8 pagineSkittles Assignmentapi-291800396Nessuna valutazione finora
- Skittles Group E-PortfolioDocumento9 pagineSkittles Group E-Portfolioapi-253834649Nessuna valutazione finora
- Final Stats ProjectDocumento8 pagineFinal Stats Projectapi-238717717100% (2)
- SkittlesdataclassprojectDocumento8 pagineSkittlesdataclassprojectapi-399586872Nessuna valutazione finora
- Math 1040 Statistics Term Project: Blake FreemanDocumento10 pagineMath 1040 Statistics Term Project: Blake Freemanapi-252919218Nessuna valutazione finora
- Final SkittlesDocumento6 pagineFinal Skittlesapi-272838320Nessuna valutazione finora
- Skittles Project With ReflectionDocumento7 pagineSkittles Project With Reflectionapi-234712126100% (1)
- Skittles FinalDocumento12 pagineSkittles Finalapi-241861434Nessuna valutazione finora
- Skittles Project 1Documento7 pagineSkittles Project 1api-299868669100% (2)
- Skittles WordDocumento5 pagineSkittles Wordapi-285645725Nessuna valutazione finora
- Math 1040 ProjectDocumento8 pagineMath 1040 Projectapi-388517702Nessuna valutazione finora
- Math 1040 Skittles Final ProjectDocumento5 pagineMath 1040 Skittles Final Projectapi-253961355Nessuna valutazione finora
- Final ProjectDocumento6 pagineFinal Projectapi-283261340Nessuna valutazione finora
- Statistics Term Project E-Portfolio ReflectionDocumento8 pagineStatistics Term Project E-Portfolio Reflectionapi-258147701Nessuna valutazione finora
- Term Project: Part 2 - IndividualDocumento13 pagineTerm Project: Part 2 - Individualapi-289345421Nessuna valutazione finora
- 1040 Skittles ProjectDocumento3 pagine1040 Skittles Projectapi-302929225Nessuna valutazione finora
- Math Project Part B With ConclusionDocumento5 pagineMath Project Part B With Conclusionapi-273321131Nessuna valutazione finora
- Skittles Term Project - Kai Galbiso Stat1040Documento6 pagineSkittles Term Project - Kai Galbiso Stat1040api-316758771Nessuna valutazione finora
- Term Project - EportfolioDocumento7 pagineTerm Project - Eportfolioapi-251981709Nessuna valutazione finora
- Math 1040 Skittles Term Project EportfolioDocumento7 pagineMath 1040 Skittles Term Project Eportfolioapi-260817278Nessuna valutazione finora
- Croot Part6 EportfolioDocumento16 pagineCroot Part6 Eportfolioapi-276896975Nessuna valutazione finora
- Math 1040 Final ProjectDocumento3 pagineMath 1040 Final Projectapi-285380759Nessuna valutazione finora
- The Rainbow ReportDocumento11 pagineThe Rainbow Reportapi-316991888Nessuna valutazione finora
- Skittles Term Project Math 1040Documento6 pagineSkittles Term Project Math 1040api-316781222Nessuna valutazione finora
- Skittles ProjectDocumento9 pagineSkittles Projectapi-252747849Nessuna valutazione finora
- Full Skittles ProjectDocumento13 pagineFull Skittles Projectapi-537189505Nessuna valutazione finora
- Skittles Project FinalDocumento5 pagineSkittles Project Finalapi-271348941Nessuna valutazione finora
- Skittles Project 5-02Documento8 pagineSkittles Project 5-02api-354040698Nessuna valutazione finora
- Skittles Term Project 11 9 14Documento5 pagineSkittles Term Project 11 9 14api-192489685Nessuna valutazione finora
- Statistics Project 17Documento13 pagineStatistics Project 17api-271978152Nessuna valutazione finora
- Math 1040 Term ProjectDocumento7 pagineMath 1040 Term Projectapi-340188424Nessuna valutazione finora
- Skittles Final Project Statistics 1040Documento7 pagineSkittles Final Project Statistics 1040api-297109325Nessuna valutazione finora
- Maths Statistics Coursework ExampleDocumento7 pagineMaths Statistics Coursework Exampleafaocsazx100% (2)
- Ashley Kammerman Statistics Term ProjectDocumento6 pagineAshley Kammerman Statistics Term Projectapi-253465186Nessuna valutazione finora
- Lesson 5 1Documento28 pagineLesson 5 1Bien BibasNessuna valutazione finora
- The Skittles Project FinalDocumento8 pagineThe Skittles Project Finalapi-316760667Nessuna valutazione finora
- Reflection and EportfolioDocumento8 pagineReflection and Eportfolioapi-252747849Nessuna valutazione finora
- Skittles ProDocumento9 pagineSkittles Proapi-241124972Nessuna valutazione finora
- Skittles Project Math 1040Documento8 pagineSkittles Project Math 1040api-495044194Nessuna valutazione finora
- Skittles ProjectDocumento5 pagineSkittles Projectapi-271444168Nessuna valutazione finora
- Math 1040 Skittles Term Project AynoaDocumento15 pagineMath 1040 Skittles Term Project Aynoaapi-301347675Nessuna valutazione finora
- The Full Skittles ProjectDocumento6 pagineThe Full Skittles Projectapi-340271527100% (1)
- Math 1040 Skittles Term ProjectDocumento10 pagineMath 1040 Skittles Term Projectapi-310671451Nessuna valutazione finora
- Term Project ReportDocumento9 pagineTerm Project Reportapi-238585685Nessuna valutazione finora
- Healthwealthportfoliopacket LeslieDocumento6 pagineHealthwealthportfoliopacket Leslieapi-305880039Nessuna valutazione finora
- Workshop 2 Statistical SupplementDocumento4 pagineWorkshop 2 Statistical Supplementazazel666Nessuna valutazione finora
- Math Skittles Term Project-1Documento6 pagineMath Skittles Term Project-1api-241771020Nessuna valutazione finora
- P ValueDocumento13 pagineP ValueKamal AnchaliaNessuna valutazione finora
- Mathematical Mindsets:: Directions: Please Answer The Questions Below in Complete Sentences With ExplanationsDocumento4 pagineMathematical Mindsets:: Directions: Please Answer The Questions Below in Complete Sentences With Explanationsapi-306465805Nessuna valutazione finora
- Group Project #1 - SkittlesDocumento9 pagineGroup Project #1 - Skittlesapi-245266056Nessuna valutazione finora
- Gcse Maths Statistics Coursework ExamplesDocumento5 pagineGcse Maths Statistics Coursework Examplesbcr7r579100% (1)
- Kalasalingam University: Office of Research & DevelopmentDocumento35 pagineKalasalingam University: Office of Research & DevelopmentsundaranagapandisnpNessuna valutazione finora
- Part 2 ProjectDocumento50 paginePart 2 Projectramakrishnad reddyNessuna valutazione finora
- DN Cross Cutting IssuesDocumento22 pagineDN Cross Cutting Issuesfatmama7031Nessuna valutazione finora
- Geography and PlanningDocumento41 pagineGeography and PlanningbolindroNessuna valutazione finora
- Multiple Perspectives in Risk and Risk Management: Philip Linsley Philip Shrives Monika Wieczorek-Kosmala EditorsDocumento311 pagineMultiple Perspectives in Risk and Risk Management: Philip Linsley Philip Shrives Monika Wieczorek-Kosmala EditorsIsabella Velasquez RodriguezNessuna valutazione finora
- Hist106 - Ballarat - Australian Indigenous Peoples - FinalDocumento22 pagineHist106 - Ballarat - Australian Indigenous Peoples - Finalapi-318300831Nessuna valutazione finora
- THE Translation Shifts of Idiom IN English-Indonesian Novel Allegiant BY Veronica RothDocumento12 pagineTHE Translation Shifts of Idiom IN English-Indonesian Novel Allegiant BY Veronica RothIan M. RichieNessuna valutazione finora
- Test Bank For Educational Psychology 7th Canadian Edition Anita Woolfolk Philip H Winne Nancy e PerryDocumento22 pagineTest Bank For Educational Psychology 7th Canadian Edition Anita Woolfolk Philip H Winne Nancy e PerryByron Holloway100% (42)
- Zabur)Documento42 pagineZabur)Mushimiyimana Paluku AlineNessuna valutazione finora
- Elango ThirupurDocumento12 pagineElango ThirupurKongunet bNessuna valutazione finora
- New Pairing Scheme 10thDocumento5 pagineNew Pairing Scheme 10thM M SultanNessuna valutazione finora
- Word WallsDocumento16 pagineWord WallsNaufal Ais Zakki DziaulhaqNessuna valutazione finora
- Oil Spill Risk AssessmentDocumento86 pagineOil Spill Risk Assessmenthalahabab100% (3)
- NIADocumento9 pagineNIAEric HexumNessuna valutazione finora
- Résumé - Zhiwen (Steve) Wang: CationDocumento2 pagineRésumé - Zhiwen (Steve) Wang: CationJuasadf IesafNessuna valutazione finora
- Models For Count Data With Overdispersion: 1 Extra-Poisson VariationDocumento7 pagineModels For Count Data With Overdispersion: 1 Extra-Poisson VariationMilkha SinghNessuna valutazione finora
- A Research On The Allowance and Budgeting of Grade 12 Students in ASIST Main CDocumento23 pagineA Research On The Allowance and Budgeting of Grade 12 Students in ASIST Main CCJ Daodaoen79% (48)
- DijkstraDocumento4 pagineDijkstraLiana AndronescuNessuna valutazione finora
- Similar To Me EffectDocumento3 pagineSimilar To Me EffectLisha ShammyNessuna valutazione finora
- Operations ResearchDocumento2 pagineOperations ResearchIshant Bansal100% (4)
- How To Negotiate With Someone More Powerful Than YouDocumento7 pagineHow To Negotiate With Someone More Powerful Than YougshirkovNessuna valutazione finora
- Econometric ToolkitDocumento2 pagineEconometric ToolkitKaiser RobinNessuna valutazione finora
- Cleanth Brooks - Literary History Vs CriticismDocumento11 pagineCleanth Brooks - Literary History Vs CriticismPayal AgarwalNessuna valutazione finora
- Career TheoriesDocumento7 pagineCareer TheoriesVoltaire Delos ReyesNessuna valutazione finora
- Analysis and Design of A Combined Triangular Shaped Pile Cap Due To Pile EccentricityDocumento7 pagineAnalysis and Design of A Combined Triangular Shaped Pile Cap Due To Pile Eccentricityazhar ahmad100% (1)
- Nastal-Dema PhilosophyDocumento1 paginaNastal-Dema PhilosophyJessicaNastal-DemaNessuna valutazione finora
- Introduction To Consumer BehaviourDocumento66 pagineIntroduction To Consumer BehaviourAnoop AjayanNessuna valutazione finora
- Iso 14001 Audit Checklist TemplatesDocumento8 pagineIso 14001 Audit Checklist TemplatesLennon Tan Qin JiNessuna valutazione finora
- JP Integrated-Planning-Manual (Gr3) Mar.2015Documento116 pagineJP Integrated-Planning-Manual (Gr3) Mar.2015SelmaNessuna valutazione finora
- Quality Circles (Q.C) : Meaning, Objectives and BenefitsDocumento17 pagineQuality Circles (Q.C) : Meaning, Objectives and BenefitsAnsal MNessuna valutazione finora