Potrebbero piacerti anche
- Estatística Básica (Parte II - Tabelas de Frequencias)Documento13 pagineEstatística Básica (Parte II - Tabelas de Frequencias)Ricardo AlexNessuna valutazione finora
- Aulas de Triângulos - Slides Revisão 9 AnoDocumento18 pagineAulas de Triângulos - Slides Revisão 9 AnoProf Evandro CostaNessuna valutazione finora
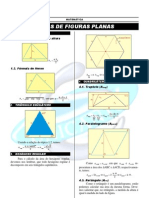
- Aula 15 - Áreas de Polígonos PDFDocumento11 pagineAula 15 - Áreas de Polígonos PDFCarlos BrandãoNessuna valutazione finora
- 1 Lista EstatísticaDocumento5 pagine1 Lista EstatísticanixikenNessuna valutazione finora
- Avaliação de Matemática para 6o Ano do Ensino FundamentalDocumento14 pagineAvaliação de Matemática para 6o Ano do Ensino FundamentalDébora Maria NunesNessuna valutazione finora
- Apostila MatemáticaDocumento12 pagineApostila MatemáticaWerqueson Souza100% (1)
- Exercícios Resolvidos de TrigonometriaDocumento6 pagineExercícios Resolvidos de Trigonometriamika 2015Nessuna valutazione finora
- Matemática do 3o CicloDocumento222 pagineMatemática do 3o CicloAnne KellyNessuna valutazione finora
- II Lista de Exercícios II Trimestre - 8° Ano ResoluçãoDocumento4 pagineII Lista de Exercícios II Trimestre - 8° Ano Resoluçãoluisresponde100% (1)
- Lei dos Cossenos e Senos para TriângulosDocumento5 pagineLei dos Cossenos e Senos para TriângulosMaysa MaltaNessuna valutazione finora
- Teorema de Pitágoras: Cálculos e AplicaçõesDocumento31 pagineTeorema de Pitágoras: Cálculos e AplicaçõesEdsonBarros100% (1)
- Matemática - Números racionaisDocumento2 pagineMatemática - Números racionaisJadiele100% (1)
- Livro Matemática 4 Exercí CiosDocumento40 pagineLivro Matemática 4 Exercí CiosValter AlmeidaNessuna valutazione finora
- Regra de três e proporcionalidade para resolver problemasDocumento4 pagineRegra de três e proporcionalidade para resolver problemasMarcos RondineyNessuna valutazione finora
- 05-Area Das Figuras PlanasDocumento5 pagine05-Area Das Figuras Planasresolvidos100% (1)
- Apostila de Geometria Plana PDFDocumento36 pagineApostila de Geometria Plana PDFMariana MendesNessuna valutazione finora
- Ed FinanceiraDocumento22 pagineEd FinanceiraIara Reis Bispo MarquesNessuna valutazione finora
- Matemática 7, 8 e 9Documento76 pagineMatemática 7, 8 e 9Constâncio CumbaNessuna valutazione finora
- Conseguir 2018 9º Ano Aluno Módulo IDocumento30 pagineConseguir 2018 9º Ano Aluno Módulo IAnonymous 5luP8WNessuna valutazione finora
- Angulos e ParalelasDocumento3 pagineAngulos e ParalelasPedro Cáceres0% (1)
- VOD-Retas Paralelas Cortadas Por Uma Transversal - Teorema de Tales-2019Documento10 pagineVOD-Retas Paralelas Cortadas Por Uma Transversal - Teorema de Tales-2019rodolfofisNessuna valutazione finora
- Tronco de ConeDocumento9 pagineTronco de Conedfremy50% (2)
- Pressão em recipientes e tubulaçõesDocumento9 paginePressão em recipientes e tubulaçõesArthur RohdeNessuna valutazione finora
- MatemáticaDocumento18 pagineMatemáticaMelquisedeque FreitasNessuna valutazione finora
- SEMANA 7 - 9º Ano - MaDocumento8 pagineSEMANA 7 - 9º Ano - MaRander SoaresNessuna valutazione finora
- ATIVIDADE 9 9o Ano MAT Graficos de Barras Coluna Linhas Ou Setores e Seus Elementos ConstitutivosDocumento6 pagineATIVIDADE 9 9o Ano MAT Graficos de Barras Coluna Linhas Ou Setores e Seus Elementos ConstitutivosDaniel SilvaNessuna valutazione finora
- Caminhadas Aleatória - Conceito e AplicaçõesDocumento5 pagineCaminhadas Aleatória - Conceito e AplicaçõesdvkozakNessuna valutazione finora
- Simulado 06Documento18 pagineSimulado 06Adilio DiasNessuna valutazione finora
- Lsta II de Exercícios - 1 Série - 2023 - 2º BimestreDocumento3 pagineLsta II de Exercícios - 1 Série - 2023 - 2º BimestreHenrique QueirogaNessuna valutazione finora
- História Das Sequências e SériesDocumento3 pagineHistória Das Sequências e SériesKarin SimonatoNessuna valutazione finora
- Apostila de Trigonometria.Documento47 pagineApostila de Trigonometria.Margelson SalemNessuna valutazione finora
- Círculo e Circunferência PDFDocumento1 paginaCírculo e Circunferência PDFRoberto SantosNessuna valutazione finora
- CA 9 Ano Vol 1 - Professor MatemáticaDocumento85 pagineCA 9 Ano Vol 1 - Professor MatemáticaGabriela UlianNessuna valutazione finora
- Arcos, ângulos e medidas de circunferênciaDocumento2 pagineArcos, ângulos e medidas de circunferênciaGenival NunesNessuna valutazione finora
- Quadriláteros: tipos e elementosDocumento5 pagineQuadriláteros: tipos e elementosAngela Maria Rocha de OliveiraNessuna valutazione finora
- Oficina de Matemática: Cálculo Algébrico, Funções e EquaçõesDocumento66 pagineOficina de Matemática: Cálculo Algébrico, Funções e EquaçõesMayara EFabio100% (1)
- Ângulos formados por retas e cortadas por transversalDocumento6 pagineÂngulos formados por retas e cortadas por transversalSandro CarvalhoNessuna valutazione finora
- Matemática 7o ano: Inequações, ângulos, probabilidadeDocumento128 pagineMatemática 7o ano: Inequações, ângulos, probabilidadeYara MiottoNessuna valutazione finora
- Caderno 9 anoEF Matematica Unidade 1 15 01 2021Documento35 pagineCaderno 9 anoEF Matematica Unidade 1 15 01 2021Darlene Souza MendesNessuna valutazione finora
- Gráficos EstatísticosDocumento4 pagineGráficos EstatísticosEdinei ChagasNessuna valutazione finora
- 1 Lista de Exercicios (Estatistica Basica)Documento3 pagine1 Lista de Exercicios (Estatistica Basica)Alex de Oliveira Souza100% (1)
- AlgotmosDocumento29 pagineAlgotmosJouber FerreiraNessuna valutazione finora
- Geometria Na NaturezaDocumento8 pagineGeometria Na Naturezageodescritiva_esaqNessuna valutazione finora
- Porcentagem noções iniciaisDocumento22 paginePorcentagem noções iniciaisAna Paula FerreiraNessuna valutazione finora
- BoletimPedagogico Mat 3AnoEMSAEPE 2008Documento124 pagineBoletimPedagogico Mat 3AnoEMSAEPE 2008João V. CoutinhoNessuna valutazione finora
- Atividade de Educação FinanceiraDocumento1 paginaAtividade de Educação FinanceiraCamilla Souza SantiagoNessuna valutazione finora
- Regra de três composta: guindastes carregam caixas em navioDocumento49 pagineRegra de três composta: guindastes carregam caixas em navioBruno BiazziNessuna valutazione finora
- Transformações da Imagem: Isometrias, Semelhanças e ProjetividadesDa EverandTransformações da Imagem: Isometrias, Semelhanças e ProjetividadesNessuna valutazione finora
- Medidas Descritivas APLICADA BASICADocumento35 pagineMedidas Descritivas APLICADA BASICAThis DudeNessuna valutazione finora
- Análise de dados estatísticosDocumento4 pagineAnálise de dados estatísticosMatheus AvelinoNessuna valutazione finora
- DistribuicaoDeFrequencias AULADocumento9 pagineDistribuicaoDeFrequencias AULAEdson MeloNessuna valutazione finora
- Resolucao Lista 2Documento20 pagineResolucao Lista 2Amore MioNessuna valutazione finora
- Aplicações da Curva S no Gerenciamento de ProjetosDocumento25 pagineAplicações da Curva S no Gerenciamento de ProjetosSidney Penha100% (1)
- Apostila 2 - Dados QuantitativosDocumento5 pagineApostila 2 - Dados QuantitativosluisfernandoNessuna valutazione finora
- Graficos Lista de Estatistica FatimaDocumento4 pagineGraficos Lista de Estatistica Fatimafatimataha1805Nessuna valutazione finora
- O Uso Dos Computadores e Da Internet Nas Escolas Publicas de Capitais BrasileirasDocumento37 pagineO Uso Dos Computadores e Da Internet Nas Escolas Publicas de Capitais BrasileirasRicardo AlexNessuna valutazione finora
- Proposta Curricular Ghisleine para SEE 1Documento27 pagineProposta Curricular Ghisleine para SEE 1Ricardo AlexNessuna valutazione finora
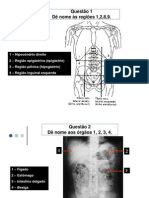
- Questão 1 Dê Nome Às Regiões 1,2,8,9.Documento25 pagineQuestão 1 Dê Nome Às Regiões 1,2,8,9.Ricardo AlexNessuna valutazione finora
- 2010.03.25..aula39.40.fatec - Anatomia Radiológica Da MamaDocumento41 pagine2010.03.25..aula39.40.fatec - Anatomia Radiológica Da MamaRicardo AlexNessuna valutazione finora
- 2010.03.18.aula33.34.fatec - Fígado Vesícula e Vias BiliaresDocumento47 pagine2010.03.18.aula33.34.fatec - Fígado Vesícula e Vias BiliaresRicardo AlexNessuna valutazione finora
- 2010.04.14. Gabarito Prova 1Documento1 pagina2010.04.14. Gabarito Prova 1Ricardo AlexNessuna valutazione finora
- Questão 1 Dê Nome Às Regiões 1,2,8,9.Documento25 pagineQuestão 1 Dê Nome Às Regiões 1,2,8,9.Ricardo AlexNessuna valutazione finora
- 2010.03.31.aula43.44.fatec - Anatomia Radiológica Do Sistema GenitalDocumento61 pagine2010.03.31.aula43.44.fatec - Anatomia Radiológica Do Sistema GenitalRicardo AlexNessuna valutazione finora
- 2010.04.07.reviisão Bloco 1Documento25 pagine2010.04.07.reviisão Bloco 1Ricardo AlexNessuna valutazione finora
- 2010.04.07.aula47.48.fatec - Anatomia Radiológica Vascular Do AbdomeDocumento16 pagine2010.04.07.aula47.48.fatec - Anatomia Radiológica Vascular Do AbdomeRicardo AlexNessuna valutazione finora
- 2010.03.31.aula43.44.fatec - Anatomia Radiológica Do Sistema GenitalDocumento61 pagine2010.03.31.aula43.44.fatec - Anatomia Radiológica Do Sistema GenitalRicardo AlexNessuna valutazione finora
- 2010.03.25..aula39.40.fatec - Anatomia Radiológica Da MamaDocumento41 pagine2010.03.25..aula39.40.fatec - Anatomia Radiológica Da MamaRicardo AlexNessuna valutazione finora
- 2010.02.25.aula15.16.fatec - Anatomia Radiológica Da Coluna CervicalDocumento37 pagine2010.02.25.aula15.16.fatec - Anatomia Radiológica Da Coluna CervicalRicardo Alex100% (1)
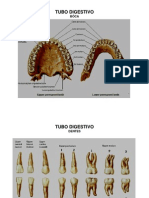
- 2010.03.11.aula27.28.fatec - Anatomia Radiológica Do AbdomeDocumento113 pagine2010.03.11.aula27.28.fatec - Anatomia Radiológica Do AbdomeRicardo AlexNessuna valutazione finora
- 2010.03.24.aula35.36.fatec - Anatomia Radiológica Do Pâncreas e BaçoDocumento25 pagine2010.03.24.aula35.36.fatec - Anatomia Radiológica Do Pâncreas e BaçoRicardo AlexNessuna valutazione finora
- Plano FisiologiaDocumento3 paginePlano FisiologiaRicardo AlexNessuna valutazione finora
- 2010.03.11.aula27.28.fatec - Anatomia Radiológica Do AbdomeDocumento113 pagine2010.03.11.aula27.28.fatec - Anatomia Radiológica Do AbdomeRicardo AlexNessuna valutazione finora
- 2010.03.11.aula27.28.fatec - Anatomia Radiológica Do AbdomeDocumento113 pagine2010.03.11.aula27.28.fatec - Anatomia Radiológica Do AbdomeRicardo AlexNessuna valutazione finora
- 2010.02.11..aula3.4.fatec - Anatomia Radiológica Do CrânioDocumento19 pagine2010.02.11..aula3.4.fatec - Anatomia Radiológica Do CrânioRicardo AlexNessuna valutazione finora
- 2010.03.03..aula17.18.fatec - Anatomia Radiológica Da Coluna DorsalDocumento17 pagine2010.03.03..aula17.18.fatec - Anatomia Radiológica Da Coluna DorsalRicardo AlexNessuna valutazione finora
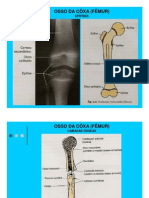
- 2010.02.24..aula13.14.fatec - Anatomia. Radiológica Da Cintura PélvicaDocumento12 pagine2010.02.24..aula13.14.fatec - Anatomia. Radiológica Da Cintura PélvicaRicardo AlexNessuna valutazione finora
- 2010.03.03.aula19.20.fatec - Anatomia Radiológica Coluna LombarDocumento39 pagine2010.03.03.aula19.20.fatec - Anatomia Radiológica Coluna LombarRicardo AlexNessuna valutazione finora
- 2010.02.18.aula9.10.fatec - Anatomia Radiológica Da Cintura EscapularDocumento16 pagine2010.02.18.aula9.10.fatec - Anatomia Radiológica Da Cintura EscapularRicardo Alex100% (1)
- 2010.02.10.aula2.fatec - Anatomia.planos e Regiões Do Corpo HumanoDocumento19 pagine2010.02.10.aula2.fatec - Anatomia.planos e Regiões Do Corpo HumanoRicardo AlexNessuna valutazione finora
- 2010.02.17.aula7.8.fatec - Anatomia Radiológica Do Membro SuperiorDocumento24 pagine2010.02.17.aula7.8.fatec - Anatomia Radiológica Do Membro SuperiorRicardo AlexNessuna valutazione finora
- Aula PotencialDocumento30 pagineAula PotencialRicardo Alex100% (1)
- 2010.02.17.aula5.6.fatec - Anatomia Radiológica Da FaceDocumento22 pagine2010.02.17.aula5.6.fatec - Anatomia Radiológica Da FaceRicardo AlexNessuna valutazione finora
- Aula Musculo (Somente Leitura)Documento37 pagineAula Musculo (Somente Leitura)Ricardo AlexNessuna valutazione finora
- Aula 01 12-02-2010Documento17 pagineAula 01 12-02-2010Ricardo AlexNessuna valutazione finora
- Fa Lda Cu de de Tecn OlogiaDocumento3 pagineFa Lda Cu de de Tecn OlogiaRicardo AlexNessuna valutazione finora
- Importância dos Projetos e Práticas de Ação PedagógicaDocumento21 pagineImportância dos Projetos e Práticas de Ação Pedagógicalgxm100% (1)
- Manual para identificar e atender crianças superdotadas na Educação InfantilDocumento63 pagineManual para identificar e atender crianças superdotadas na Educação InfantilEndi CecciNessuna valutazione finora
- Atividades de Inglês para MilitarDocumento4 pagineAtividades de Inglês para MilitarBruna OliveiraNessuna valutazione finora
- Língua Portuguesa 1o AnoDocumento58 pagineLíngua Portuguesa 1o AnoDuelNessuna valutazione finora
- Selo Procel de Economia de Energia para EletrodomésticosDocumento93 pagineSelo Procel de Economia de Energia para EletrodomésticosJorge PinhoNessuna valutazione finora
- Kósmos Noetós. Metafísica de PeirceDocumento17 pagineKósmos Noetós. Metafísica de Peircegmjr760% (1)
- MUV posição tempoDocumento1 paginaMUV posição tempoJailton AlvesNessuna valutazione finora
- Lean Six Sigma em Análise de Registros IndustriaisDocumento22 pagineLean Six Sigma em Análise de Registros IndustriaisIBRNessuna valutazione finora
- Aprova Brasil 1EM MAT 3-AlunoDocumento20 pagineAprova Brasil 1EM MAT 3-Alunosó hoje prova75% (4)
- O olhar da sedução: entre desejo e dependênciaDocumento18 pagineO olhar da sedução: entre desejo e dependênciaAdriel DutraNessuna valutazione finora
- Física - CIE - TEC - VOL 2Documento264 pagineFísica - CIE - TEC - VOL 2Italo Yuri86% (7)
- Cidade Santos Propriedades Geotecnicas SubsoloDocumento9 pagineCidade Santos Propriedades Geotecnicas SubsoloVirginio MantessoNessuna valutazione finora
- 2o SIMULADO BANCO DO BRASIL - GabaritoDocumento19 pagine2o SIMULADO BANCO DO BRASIL - GabaritoEDUARDA PINTONessuna valutazione finora
- CrossFit: Aspectos fisiológicos do treinamento intermitente de alta intensidade (TIAIDocumento31 pagineCrossFit: Aspectos fisiológicos do treinamento intermitente de alta intensidade (TIAIGisele Ferreira MachadoNessuna valutazione finora
- 5 - CSR VW Rev 13 - Fórmula Q Integral 5 EdiçãoDocumento34 pagine5 - CSR VW Rev 13 - Fórmula Q Integral 5 Ediçãoandte costaNessuna valutazione finora
- 02 MatematicaDocumento219 pagine02 Matematicaadones araujo100% (1)
- Racionais 6oDocumento244 pagineRacionais 6oMara AzevedoNessuna valutazione finora
- FICHA REVISÕES 9oDocumento5 pagineFICHA REVISÕES 9oAnabela FernandesNessuna valutazione finora
- Teste de Aprendizagem Auditivo-Verbal de ReyDocumento2 pagineTeste de Aprendizagem Auditivo-Verbal de ReyCamila AzevedoNessuna valutazione finora
- Segurança em Instalações e Serviços em EletricidadeDocumento29 pagineSegurança em Instalações e Serviços em EletricidadeAlessandro GomesNessuna valutazione finora
- Manual de Imobilizador VW Imob 1 PDFDocumento19 pagineManual de Imobilizador VW Imob 1 PDFJoao Silva LopesNessuna valutazione finora
- AS TRÊS CONCEPÇÕES DE LINGUAGEMDocumento4 pagineAS TRÊS CONCEPÇÕES DE LINGUAGEMValeria MartinsNessuna valutazione finora
- Artigo - Santaella - 'Filosofia Disruptiva para Arte Disruptiva' (2018) PDFDocumento21 pagineArtigo - Santaella - 'Filosofia Disruptiva para Arte Disruptiva' (2018) PDFOrange-BrNessuna valutazione finora
- Geografia 80sanos Umepedroii 20a30setembro 2021Documento2 pagineGeografia 80sanos Umepedroii 20a30setembro 2021Lidia RossmannNessuna valutazione finora
- A Dor Faz ArteDocumento3 pagineA Dor Faz ArtealavigneNessuna valutazione finora
- O Espelho Do Amor Pais e ProfessoresDocumento3 pagineO Espelho Do Amor Pais e ProfessoresJúliaNessuna valutazione finora
- Mapa CorumbiaraDocumento1 paginaMapa CorumbiaraJessica RodriguesNessuna valutazione finora
- 3667 - Projeto de Rede de Distribuição - Cálculo Elétrico PDFDocumento23 pagine3667 - Projeto de Rede de Distribuição - Cálculo Elétrico PDFRolando DalenzNessuna valutazione finora
- Movimento Uniforme IIDocumento7 pagineMovimento Uniforme IIClaude BrechtNessuna valutazione finora
- O ethos lúdico do bebê: curiosidade, intenção e mãoDocumento8 pagineO ethos lúdico do bebê: curiosidade, intenção e mãoFernanda Binda Alves TouretNessuna valutazione finora