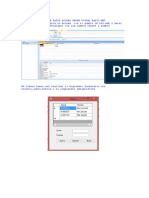
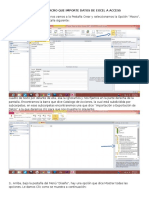
Potrebbero piacerti anche
- Cómo entender estadística fácilmenteDa EverandCómo entender estadística fácilmenteValutazione: 3.5 su 5 stelle3.5/5 (2)
- Estadística Aplicada PDFDocumento143 pagineEstadística Aplicada PDFZan Medina17% (6)
- Anteproyecto de GotasDocumento18 pagineAnteproyecto de GotasMaurilio HuNessuna valutazione finora
- Regresión entre el IPC y el IPM en EE.UU. 1980-2006Documento4 pagineRegresión entre el IPC y el IPM en EE.UU. 1980-2006Johana Pao Salgado GarciaNessuna valutazione finora
- Clase 7 - Medidas de Tendencia Central y de DispersionDocumento4 pagineClase 7 - Medidas de Tendencia Central y de DispersionEnzo OlmosNessuna valutazione finora
- Fase 2 Pedro Manrique IndividualDocumento19 pagineFase 2 Pedro Manrique IndividualAdriana CruzNessuna valutazione finora
- M8 Matemáticas II (B) FBN A Proyecto ModuladorDocumento10 pagineM8 Matemáticas II (B) FBN A Proyecto ModuladorᴀʟғᴏɴsᴏNessuna valutazione finora
- Medidas de Tendencia CentralDocumento4 pagineMedidas de Tendencia CentralNotasddNessuna valutazione finora
- Actividades Cap 10 InvestigacionDocumento19 pagineActividades Cap 10 InvestigacionMercy LópezNessuna valutazione finora
- 5 Medidas de Dispersión Datos No AgrupadosDocumento6 pagine5 Medidas de Dispersión Datos No Agrupadoscalvita2494Nessuna valutazione finora
- GUIA 3 Medidas de Tendencia CentralDocumento8 pagineGUIA 3 Medidas de Tendencia CentralAida AbadNessuna valutazione finora
- Medidas de Tendencia CentralDocumento21 pagineMedidas de Tendencia CentralJoan FajardoNessuna valutazione finora
- 3 . Videoconferencia: Estadística BásicaDocumento23 pagine3 . Videoconferencia: Estadística BásicaMartin CarmonaNessuna valutazione finora
- Protocolo Individual EstadisticaDocumento6 pagineProtocolo Individual EstadisticaMr JesuNessuna valutazione finora
- Guía Desempeño 8 Trigonometría 10º 2022Documento17 pagineGuía Desempeño 8 Trigonometría 10º 2022John CaroNessuna valutazione finora
- Medidas de Tendencia Central y de Posición.Documento16 pagineMedidas de Tendencia Central y de Posición.Hither Amaury Trinidad Tavarez100% (1)
- Actividad IvDocumento7 pagineActividad IvGlorybell Cabrera AlmanzarNessuna valutazione finora
- Cuadro de FrecuenciasDocumento12 pagineCuadro de FrecuenciasLaineibi GomezNessuna valutazione finora
- Medidas centrales del Covid-19Documento26 pagineMedidas centrales del Covid-19Alberto Olivares Ramírez0% (2)
- Daniel Parra Resolucion de Ejercicos, Estadistica T1Documento6 pagineDaniel Parra Resolucion de Ejercicos, Estadistica T1DanielNessuna valutazione finora
- Tercero Eskarleth U2T1a3Documento9 pagineTercero Eskarleth U2T1a3Eskarleth YaniraNessuna valutazione finora
- Estadística descriptiva problemaDocumento4 pagineEstadística descriptiva problemaDennNessuna valutazione finora
- GUÍA No 3 RAZONAMIENTO CUANTITATIVO GRADO OCTAVODocumento7 pagineGUÍA No 3 RAZONAMIENTO CUANTITATIVO GRADO OCTAVOJoseph Orjuela0% (1)
- Portafolio de Evidencias U2 EstadísticaDocumento18 paginePortafolio de Evidencias U2 EstadísticaCarlos BarnetNessuna valutazione finora
- GRUPO99 - Fase 2 - Identificación de Variables Estadísticas PDFDocumento40 pagineGRUPO99 - Fase 2 - Identificación de Variables Estadísticas PDFYUNEIDY KARINA VARGAS CAYCEDONessuna valutazione finora
- Edm-302 Unidad 1Documento15 pagineEdm-302 Unidad 1LuisJunniorRomeroManzuetaNessuna valutazione finora
- Medidas de Tendencia Central para Datos No AgrupadosDocumento3 pagineMedidas de Tendencia Central para Datos No AgrupadosJosé Pérez JiménezNessuna valutazione finora
- Trabajo Filnal Unidad 1 EstadisticaDocumento12 pagineTrabajo Filnal Unidad 1 EstadisticaChavez Angel Michel Monserrat PGEA 4BNessuna valutazione finora
- Ejercicio 1 - Henry Cuadros PuentesDocumento9 pagineEjercicio 1 - Henry Cuadros PuentesMarya Isa CNessuna valutazione finora
- Aca 2 EstadisticaDocumento13 pagineAca 2 EstadisticalEIDYNessuna valutazione finora
- Guía Proyecto IntegradorDocumento22 pagineGuía Proyecto IntegradorHatashii ChiyokoNessuna valutazione finora
- T2. EstadísticaDocumento26 pagineT2. Estadísticarca_rodrigo0% (1)
- Material Unidad 1Documento21 pagineMaterial Unidad 1AnaPetrizNessuna valutazione finora
- Pre-Tarea Wilmer AlvarezDocumento11 paginePre-Tarea Wilmer AlvarezEDINSON SUAREZNessuna valutazione finora
- Daniel Parra Resolucion de Ejercicos, Estadistica T1Documento10 pagineDaniel Parra Resolucion de Ejercicos, Estadistica T1DanielNessuna valutazione finora
- Estadística Descriptiva y Teoría Del MuestreoDocumento22 pagineEstadística Descriptiva y Teoría Del MuestreoJesús alberto poot cocomNessuna valutazione finora
- Investigación Probabilidad y Estadística-Equipo 3Documento27 pagineInvestigación Probabilidad y Estadística-Equipo 3Paola RuizNessuna valutazione finora
- Apuntes Estadística DescriptivaDocumento12 pagineApuntes Estadística Descriptivaioki3Nessuna valutazione finora
- Medidas de Tendencia Central EJCHZDocumento7 pagineMedidas de Tendencia Central EJCHZERWINCHZ2009100% (2)
- Cómo clasificar y ordenar datos estadísticos para reportajes periodísticosDocumento9 pagineCómo clasificar y ordenar datos estadísticos para reportajes periodísticosAbel JmcNessuna valutazione finora
- ECEDU: Análisis estadístico descriptivo de conceptos básicosDocumento11 pagineECEDU: Análisis estadístico descriptivo de conceptos básicosLuz Victoria MoraNessuna valutazione finora
- Tema 02 Medidas EstadisticasDocumento19 pagineTema 02 Medidas EstadisticasGuillermo Vasquez VallejosNessuna valutazione finora
- Tema 4. Medidas de Tendencia CentralDocumento11 pagineTema 4. Medidas de Tendencia CentralOscar Leonardo Bellido LópezNessuna valutazione finora
- Deber EstadisticaDocumento8 pagineDeber Estadisticaandrea amayaNessuna valutazione finora
- GuíaDocumento22 pagineGuíaJefrypazz100% (2)
- Unidad No. 02 Análisis EstadísticoDocumento17 pagineUnidad No. 02 Análisis Estadísticoaxelmrd100% (1)
- Medidas de tendencia central en estadísticaDocumento4 pagineMedidas de tendencia central en estadísticaALEXANDER GIRONNessuna valutazione finora
- Mat 9u2Documento46 pagineMat 9u2Carlos SantillanaNessuna valutazione finora
- Medidas centrales y dispersión datosDocumento20 pagineMedidas centrales y dispersión datosMine CruzNessuna valutazione finora
- CUARTILES Y MEDIDAS DE DISPERSION Naiara Conrado 9d1 PDFDocumento11 pagineCUARTILES Y MEDIDAS DE DISPERSION Naiara Conrado 9d1 PDFhector enrique conrado barrancoNessuna valutazione finora
- Secme 21224Documento16 pagineSecme 21224Serafin CondeNessuna valutazione finora
- Medidas de tendencia centralDocumento13 pagineMedidas de tendencia central2C maria belen yupanqui gutierrezNessuna valutazione finora
- Caracterización de Variables Cuantitativas2.Documento9 pagineCaracterización de Variables Cuantitativas2.Vilmari PiñerosNessuna valutazione finora
- Fase 2 - Identificación de Variables Estadísticas Trabajo GrupalDocumento23 pagineFase 2 - Identificación de Variables Estadísticas Trabajo Grupaljose alejandroNessuna valutazione finora
- Tarea 4 Estadistica CargarDocumento5 pagineTarea 4 Estadistica CargarJuan Antonio Cruz GonzalezNessuna valutazione finora
- Medidas de Tendencia CentralDocumento13 pagineMedidas de Tendencia CentralAneth Ochoa cosmetologiaNessuna valutazione finora
- GIEFD U4 Edgar Olmos ARDocumento7 pagineGIEFD U4 Edgar Olmos AROziel OlmosNessuna valutazione finora
- Estadistica Descriptiva - MedidasTendenciaCentralDocumento10 pagineEstadistica Descriptiva - MedidasTendenciaCentralNicolas Cruz SwaneckNessuna valutazione finora
- Clase 1 Aplicac Estadistica 2019 - 1Documento38 pagineClase 1 Aplicac Estadistica 2019 - 1FabianNessuna valutazione finora
- Ejercicio Estadistica DescriptivaDocumento53 pagineEjercicio Estadistica DescriptivaLEYDI VIVIANA CASTILLO SALIRROSASNessuna valutazione finora
- Práctica PROBABILIDAD Parte de AdrianDocumento13 paginePráctica PROBABILIDAD Parte de Adrianvictor emanuelNessuna valutazione finora
- La Serie Armónica y La Serie de Los Inversos de Los Números PrimosDocumento2 pagineLa Serie Armónica y La Serie de Los Inversos de Los Números PrimosGustavo RíosNessuna valutazione finora
- Ejercicio 3Documento8 pagineEjercicio 3DRNessuna valutazione finora
- Definicion R&RDocumento4 pagineDefinicion R&RIng. Alejandro Hernández B.Nessuna valutazione finora
- Transmisión de PotenciaDocumento40 pagineTransmisión de Potenciamattyas Bernal100% (2)
- IndeterminismoDocumento37 pagineIndeterminismoFrancis MarambioNessuna valutazione finora
- Informe Técnico Myh 125HPDocumento2 pagineInforme Técnico Myh 125HPDaniel FrankoNessuna valutazione finora
- Razonamiento Logico MatematicoDocumento59 pagineRazonamiento Logico MatematicoRossina Encinos López33% (3)
- Informe Et Activator PDFDocumento19 pagineInforme Et Activator PDFRichard Henry Sanchez CalderonNessuna valutazione finora
- Tensiones en Los Acordes y RearmonizacionDocumento40 pagineTensiones en Los Acordes y RearmonizacionrafaelNessuna valutazione finora
- Efecto TúnelDocumento5 pagineEfecto TúnelIván Del ÁngelNessuna valutazione finora
- Trabajo Con Ajax en PHP Utilizando XajaxDocumento94 pagineTrabajo Con Ajax en PHP Utilizando XajaxJonathan MoranNessuna valutazione finora
- Practica 3 Laboratorio Control ModernoDocumento9 paginePractica 3 Laboratorio Control Modernohector mariano gonzalez garciaNessuna valutazione finora
- Curvas IsoluxDocumento4 pagineCurvas IsoluxMartin MachucaNessuna valutazione finora
- Ficha 2 - 5to - Exp 8Documento3 pagineFicha 2 - 5to - Exp 8robyn humpire molinaNessuna valutazione finora
- Banco de Preguntas Ultimas ExposicionesDocumento15 pagineBanco de Preguntas Ultimas ExposicionesJoe BotelloNessuna valutazione finora
- CAPITULODocumento63 pagineCAPITULOMA MacedoNessuna valutazione finora
- TermodinamicaDocumento9 pagineTermodinamicaIvan Rivera ArgumedoNessuna valutazione finora
- Mínimos cuadrados ponderados en regresión linealDocumento9 pagineMínimos cuadrados ponderados en regresión linealALISON ELIZABETH HUAPAYA CAYCHONessuna valutazione finora
- Practica Vbnet Con AccessDocumento3 paginePractica Vbnet Con AccessfranzepedacNessuna valutazione finora
- Crear Una Macro Que Importe Datos de Excel A AccessDocumento8 pagineCrear Una Macro Que Importe Datos de Excel A AccessJonhy Juancho MagañaNessuna valutazione finora
- Simetría en figuras 2DDocumento18 pagineSimetría en figuras 2Dalexisomar_cidNessuna valutazione finora
- Unidad 2 Datos AtipicosDocumento3 pagineUnidad 2 Datos Atipicosjose florezNessuna valutazione finora
- Ciclo Rankine Regenerativo ....Documento13 pagineCiclo Rankine Regenerativo ....Jhoel Sierra F100% (2)
- Cómo Instalar Nagios en Debian 10 BusterDocumento24 pagineCómo Instalar Nagios en Debian 10 BusterYoali VerduNessuna valutazione finora
- Deshidratacion Osmotica de FrutasDocumento7 pagineDeshidratacion Osmotica de FrutasLeibnitz Romario Sanchez BandaNessuna valutazione finora
- RL5 Iib S4Documento3 pagineRL5 Iib S4Marco Antonio Campos Plasencia100% (2)
- Tesis Doctoral - David Alonso UrbanoDocumento608 pagineTesis Doctoral - David Alonso UrbanoEmma AlarconNessuna valutazione finora
- FactorizacionDocumento6 pagineFactorizacionSamuel TejadaNessuna valutazione finora