Potrebbero piacerti anche
- Multicore Software Development Techniques: Applications, Tips, and TricksDa EverandMulticore Software Development Techniques: Applications, Tips, and TricksValutazione: 2.5 su 5 stelle2.5/5 (2)
- Operating Systems Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesDa EverandOperating Systems Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesNessuna valutazione finora
- Darshan Institute of Engineering & TechnologyDocumento49 pagineDarshan Institute of Engineering & TechnologyDhrumil DancerNessuna valutazione finora
- Unit-IV Operating System SupportDocumento23 pagineUnit-IV Operating System SupportKrishna Satya Varma ManthenaNessuna valutazione finora
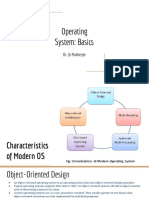
- 2.operating System - Basics2Documento18 pagine2.operating System - Basics2Shashank RahNessuna valutazione finora
- Operating Systems: - Chapter 1Documento6 pagineOperating Systems: - Chapter 1Hazem MohamedNessuna valutazione finora
- Introduction of DSDocumento41 pagineIntroduction of DSHarsh NebhwaniNessuna valutazione finora
- Cis PDFDocumento60 pagineCis PDFJan LunaNessuna valutazione finora
- Linux TutorialDocumento10 pagineLinux TutorialRadwa EhabNessuna valutazione finora
- Design of Parallel and Distributed Systems: Dr. Seemab LatifDocumento36 pagineDesign of Parallel and Distributed Systems: Dr. Seemab LatifNadi YaqoobNessuna valutazione finora
- Unit1 Parallel and DistributedDocumento29 pagineUnit1 Parallel and Distributedadamaloudi2017Nessuna valutazione finora
- Distributed & MultiProcessorDocumento3 pagineDistributed & MultiProcessorKripesh SharmaNessuna valutazione finora
- Chapter1 DosDocumento51 pagineChapter1 DosnimmapreetuNessuna valutazione finora
- Ds/Unit 1 Truba College of Science & Tech., BhopalDocumento9 pagineDs/Unit 1 Truba College of Science & Tech., BhopalKuldeep PalNessuna valutazione finora
- Chapter Three ProcessDocumento27 pagineChapter Three ProcessPro NebyuNessuna valutazione finora
- Chapter 3-ProcessesDocumento40 pagineChapter 3-Processesezra berhanuNessuna valutazione finora
- Questions To Practice For Cse323 Quiz 1Documento4 pagineQuestions To Practice For Cse323 Quiz 1errormaruf4Nessuna valutazione finora
- Lecture 1 Introduction To Distributed Systems - 034922Documento6 pagineLecture 1 Introduction To Distributed Systems - 034922leonardkigen100Nessuna valutazione finora
- ACA Unit 4Documento41 pagineACA Unit 4sushil@irdNessuna valutazione finora
- Introduction To Distributed Operating Systems Communication in Distributed SystemsDocumento150 pagineIntroduction To Distributed Operating Systems Communication in Distributed SystemsSweta KamatNessuna valutazione finora
- IntroductionDocumento34 pagineIntroductionjosephboyong542Nessuna valutazione finora
- Threads Revisited: Lecture NotesDocumento8 pagineThreads Revisited: Lecture NotesTESFAHUNNessuna valutazione finora
- Intro To DS Chapter 2Documento29 pagineIntro To DS Chapter 2Habib MuhammedNessuna valutazione finora
- OperatingsystemDocumento18 pagineOperatingsystemAdnanNessuna valutazione finora
- Chapter 4Documento15 pagineChapter 4MehreenAkramNessuna valutazione finora
- Distributed Systems PerspectiveDocumento83 pagineDistributed Systems PerspectiveRameez RashidNessuna valutazione finora
- Chapter 3 - ProcessDocumento30 pagineChapter 3 - ProcesslaliselamatoleraNessuna valutazione finora
- Complete Unit 1Documento106 pagineComplete Unit 1bdfine9Nessuna valutazione finora
- E-Content OS Full Notes Unit - 1 To 4Documento54 pagineE-Content OS Full Notes Unit - 1 To 4Zaid AhmedNessuna valutazione finora
- CS4513 Distributed Computer SystemsDocumento23 pagineCS4513 Distributed Computer SystemsShahnaz ShakirNessuna valutazione finora
- Lecture 2 Distributed and Parallel Computing CSE423Documento23 pagineLecture 2 Distributed and Parallel Computing CSE423ZeyRoX GamingNessuna valutazione finora
- Introduction To Distributed SystemsDocumento25 pagineIntroduction To Distributed SystemsshabinmohdNessuna valutazione finora
- Assignmet of Distribute SystemDocumento10 pagineAssignmet of Distribute SystemadmachewNessuna valutazione finora
- Performance Analysis of N-Computing Device Under Various Load ConditionsDocumento7 paginePerformance Analysis of N-Computing Device Under Various Load ConditionsInternational Organization of Scientific Research (IOSR)Nessuna valutazione finora
- Types of Operating SystemsDocumento12 pagineTypes of Operating SystemsRaja AnsNessuna valutazione finora
- OSY Lecture 2 Notes - MSBTE NEXT ICONDocumento11 pagineOSY Lecture 2 Notes - MSBTE NEXT ICONBarik PradeepNessuna valutazione finora
- Unit 1 NotesDocumento31 pagineUnit 1 NotesRanjith SKNessuna valutazione finora
- Chapter 2 ProcessDocumento28 pagineChapter 2 ProcessMehari KirosNessuna valutazione finora
- DS Chapter 3Documento39 pagineDS Chapter 3Maddula PrasadNessuna valutazione finora
- Mscs6060 Parallel and Distributed SystemsDocumento50 pagineMscs6060 Parallel and Distributed SystemsSadia MughalNessuna valutazione finora
- Network Operating SystemDocumento7 pagineNetwork Operating SystemMuñoz, Jian Jayne O.Nessuna valutazione finora
- Operating SystemDocumento66 pagineOperating SystemDr. Hitesh MohapatraNessuna valutazione finora
- Lecture 1 Thay TuDocumento87 pagineLecture 1 Thay Tuapi-3801193100% (1)
- Distributed Operating SystemsDocumento54 pagineDistributed Operating Systemsbeti_1531Nessuna valutazione finora
- CCT Unit - 1Documento26 pagineCCT Unit - 1vedha0118Nessuna valutazione finora
- Unit 4Documento7 pagineUnit 4tanuverma0215Nessuna valutazione finora
- Chapter 2 ProcessesDocumento39 pagineChapter 2 ProcessesHiziki TareNessuna valutazione finora
- Chapter 3-Processes: Mulugeta ADocumento34 pagineChapter 3-Processes: Mulugeta Amerhatsidik melkeNessuna valutazione finora
- Os 4 Units - RotatedDocumento90 pagineOs 4 Units - Rotatednarsi reddy MorthalaNessuna valutazione finora
- Types of Operating System3Documento6 pagineTypes of Operating System3gsssbheemsanaNessuna valutazione finora
- Distributed Shared MemoryDocumento20 pagineDistributed Shared MemoryAsemSalehNessuna valutazione finora
- Institution of Technology School of Computing Department of Information TechnologyDocumento42 pagineInstitution of Technology School of Computing Department of Information TechnologysemagnNessuna valutazione finora
- Replication in Distributed Systems: Kavya Barnadhya HazarikaDocumento27 pagineReplication in Distributed Systems: Kavya Barnadhya HazarikaDimple BansalNessuna valutazione finora
- MIT-101-Acitvity 1-Operating System and NetworkingDocumento5 pagineMIT-101-Acitvity 1-Operating System and NetworkingCarlo Moon CorpuzNessuna valutazione finora
- RMCSDocumento127 pagineRMCSAmita Rathee DahiyaNessuna valutazione finora
- LSODocumento72 pagineLSObadsoftNessuna valutazione finora
- Lec 1 IntroductionDocumento94 pagineLec 1 Introductionzelalem alemNessuna valutazione finora
- Emb 1Documento14 pagineEmb 1Shah VatsalNessuna valutazione finora
- A To Z PPT NotesDocumento62 pagineA To Z PPT NotesKarthikeyan RamajayamNessuna valutazione finora
- Parallel ProcessingDocumento35 pagineParallel ProcessingGetu GeneneNessuna valutazione finora
- Help Lab ThreadsDocumento17 pagineHelp Lab ThreadsAliWaris HaideryNessuna valutazione finora
- Chapter 3-Processes: Mulugeta ADocumento34 pagineChapter 3-Processes: Mulugeta Amerhatsidik melkeNessuna valutazione finora
- Distributed System LessonplanDocumento6 pagineDistributed System LessonplanramyajesiNessuna valutazione finora
- Os 2Documento17 pagineOs 2kingofsoumenNessuna valutazione finora
- Scheduling Algorithms UpdateDocumento36 pagineScheduling Algorithms UpdateRamin Khalifa WaliNessuna valutazione finora
- 02 CPipeShellDocumento13 pagine02 CPipeShellJohn SmithNessuna valutazione finora
- OS Practical FileDocumento48 pagineOS Practical Fileprecious mNessuna valutazione finora
- 2-INTRODUCTION TO PDC - MOTIVATION - KEY CONCEPTS-03-Dec-2019Material - I - 03-Dec-2019 - Module - 1 PDFDocumento63 pagine2-INTRODUCTION TO PDC - MOTIVATION - KEY CONCEPTS-03-Dec-2019Material - I - 03-Dec-2019 - Module - 1 PDFANTHONY NIKHIL REDDYNessuna valutazione finora
- Cpu SchedulingDocumento6 pagineCpu SchedulingMaAngelicaElimancoNessuna valutazione finora
- Dr. Faris LlwaahDocumento25 pagineDr. Faris LlwaahHussein ShakirNessuna valutazione finora
- Lecture 6, OS PDFDocumento7 pagineLecture 6, OS PDFMaria Akter LuthfaNessuna valutazione finora
- Cs56 Super-Imp-Tie-23Documento2 pagineCs56 Super-Imp-Tie-23Brundaja D NNessuna valutazione finora
- Unit V Part A: Sri Vidya College of Engineering & Technology - VirudhunagarDocumento5 pagineUnit V Part A: Sri Vidya College of Engineering & Technology - VirudhunagarSuresh SubramanianNessuna valutazione finora
- Index:: NAME - Yash Chowdhary ID - 201003003001 Batch - Bcs3D - Ai Subject - Operating SystemDocumento25 pagineIndex:: NAME - Yash Chowdhary ID - 201003003001 Batch - Bcs3D - Ai Subject - Operating SystemPiyush KumarNessuna valutazione finora
- Very Simple Threading ExampleDocumento38 pagineVery Simple Threading ExamplephanishyamnagaNessuna valutazione finora
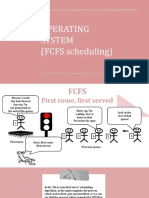
- Operating Systems: Scheduling AlgorithmsDocumento23 pagineOperating Systems: Scheduling AlgorithmsSneha Chowdhary KNessuna valutazione finora
- OsDocumento9 pagineOsanon_48973018Nessuna valutazione finora
- Ud923 Birrell PaperDocumento38 pagineUd923 Birrell PaperBurtNessuna valutazione finora
- ThreadsDocumento11 pagineThreadsFariha Nuzhat MajumdarNessuna valutazione finora
- 01intro PDFDocumento60 pagine01intro PDFHiro RaylonNessuna valutazione finora
- Traffic Deadlock: Deadlock: Bridge Crossing ExampleDocumento3 pagineTraffic Deadlock: Deadlock: Bridge Crossing ExampleHari HaranNessuna valutazione finora
- DBMS Concurrency Control - Two Phase, Timestamp, Lock-Based ProtocolDocumento11 pagineDBMS Concurrency Control - Two Phase, Timestamp, Lock-Based ProtocolKidderüloDanielNessuna valutazione finora
- Power Off Reset Reason BackupDocumento5 paginePower Off Reset Reason BackupGuilherme NascimentoNessuna valutazione finora
- Theoretical Study Based Analysis On The Facets of MPI in Parallel ComputingDocumento4 pagineTheoretical Study Based Analysis On The Facets of MPI in Parallel ComputingAnthony FelderNessuna valutazione finora
- Data Sasaran SMPDocumento122 pagineData Sasaran SMPSyahdan HudaNessuna valutazione finora
- Barrière de Synchronisation: Émaphores OrrectionDocumento5 pagineBarrière de Synchronisation: Émaphores OrrectionDjamila BekhedidjaNessuna valutazione finora
- UntitledDocumento7 pagineUntitledFitria KrismarwatiNessuna valutazione finora
- Unit 3 - Java Programming - WWW - Rgpvnotes.inDocumento32 pagineUnit 3 - Java Programming - WWW - Rgpvnotes.inbosoho4313Nessuna valutazione finora
- Virus Decrypt ScriptDocumento3 pagineVirus Decrypt ScriptGTA 5Nessuna valutazione finora
- Advanced Computer ArchitectureDocumento5 pagineAdvanced Computer ArchitecturePranav JINessuna valutazione finora